
Пусть в блоге Яндекса на Хабрахабре эта неделя пройдет под знаком нейронных сетей. Как мы видим, нейросети сейчас начинают использоваться в очень многих областях, включая поиск. Кажется, что «модно» искать для них новые сферы применения, а в тех сферах, где они работают уже какое-то время, процессы не такие интересные.
Однако события в мире синтеза визуальных образов доказывают обратное. Да, компании еще несколько лет назад начали использовать нейросети для операций с изображениями — но это был не конец пути, а его начало. Недавно руководитель группы компьютерного зрения «Сколтеха» и большой друг Яндекса и ШАДа Виктор Лемпицкий рассказал о нескольких новых способах применения сетей к изображениям. Поскольку сегодняшняя лекция — про картинки, то она очень наглядная.
Под катом — расшифровка и большинство слайдов.
Однако события в мире синтеза визуальных образов доказывают обратное. Да, компании еще несколько лет назад начали использовать нейросети для операций с изображениями — но это был не конец пути, а его начало. Недавно руководитель группы компьютерного зрения «Сколтеха» и большой друг Яндекса и ШАДа Виктор Лемпицкий рассказал о нескольких новых способах применения сетей к изображениям. Поскольку сегодняшняя лекция — про картинки, то она очень наглядная.
Под катом — расшифровка и большинство слайдов.








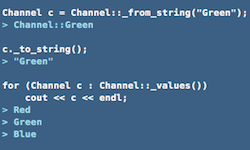 У перечислений есть множество способов применения в разработке. Например, при создании игр они используются для программирования состояний персонажа или возможных направлений движения:
У перечислений есть множество способов применения в разработке. Например, при создании игр они используются для программирования состояний персонажа или возможных направлений движения: