
В этом посте мы расскажем об использовании библиотеки ускорения аналитики данных Intel Data Analytics Acceleration Library (Intel DAAL) с языком программирования Go для пакетной, интерактивной и распределенной обработки.

Golang и распределенные системы

Когда мы в последний раз остановились на Movie Monad, мы создали десктопный видео-плеер, использующий все веб-технологии (HTML, CSS, JavaScript и Electron). Фокус был в том, что весь исходный код проекта был написан на Haskell.
Одним из ограничений нашего веб-подхода было то, что размер видео-файла не мог быть слишком большим, в противном случае приложение падало. Чтобы этого избежать, мы внедрили проверку размера файла и предупреждали пользователя о превышении ограничения.
Мы могли бы продолжить развивать наш подход с вебом, настроив бэкенд на стриминг видеофайла в HTML5-сервер, запустив параллельно сервер и Electron-приложение. Вместо этого мы откажемся от веб-технологий и обратимся к GTK+, Gstreamer и системе управления окнами X11.
Недавно PHP-проекты Avito перешли на версию PHP 7.1. По этому случаю мы решили вспомнить, как происходил переход на PHP 7.0 у нас и наших коллег из OLX. Дела давно минувших дней, но остались красивые графики, которые хочется показать миру.
Первая часть рассказа основана на статье PHP’s not dead! PHP7 in practice, которую написал наш коллега из OLX Łukasz Szymański (Лукаш Шиманьски): переход OLX на PHP 7. Во второй части — опыт перехода Avito на PHP 7.0 и PHP 7.1: процесс, трудности, результаты с графиками.


Привет, Хабр! С этого выпуска мы начинаем хорошую традицию: каждый месяц будет выходить набор рецензий на некоторые научные статьи от членов сообщества Open Data Science из канала #article_essence. Хотите получать их раньше всех — вступайте в сообщество ODS!
Статьи выбираются либо из личного интереса, либо из-за близости к проходящим сейчас соревнованиям. Если вы хотите предложить свою статью или у вас есть какие-то пожелания — просто напишите в комментариях и мы постараемся всё учесть в дальнейшем.
Редко когда кандидат проходит только одно техническое собеседование — обычно их несколько. Среди причин, почему человеку они могут даваться непросто, можно назвать и ту, что каждый раз приходится общаться с новыми людьми, думать о том, как они восприняли твой ответ, пытаться интерпретировать их реакцию. Мы решили попробовать использовать формат контеста, чтобы сократить количество итераций для всех участников процесса.

Для Блица мы выбрали исключительно алгоритмические задачи. Хотя для оценки раундов и применяется система ACM, в отличие от спортивного программирования все задания максимально приближены к тем, которые постоянно решают в продакшене Поиска. Те, кто решит успешно хотя бы четыре задачи из шести, могут считать, что прошли первый этап отбора в Яндекс. Почему алгоритмы? В процессе работы часто меняются задачи, проекты, языки программирования, платформы — те, кто владеет алгоритмами, всегда смогут перестроиться и быстро научиться новому. Типичная задача на собеседовании — составить алгоритм, доказать его корректность, предложить пути оптимизации.
Квалификацию можно пройти с 18 по 24 сентября включительно. В этом раунде вам нужно будет написать программы для решения шести задач. Можете использовать Java, C++, C# или Python. На всё про всё у вас будет четыре часа. В решающем раунде будут соревноваться те, кто справится как минимум с четырьмя квалификационными задачами. Финал пройдёт одновременно для всех участников — 30 сентября, с 12:00 до 16:00 по московскому времени. Итоги будут подведены 4 октября. Чтобы всем желающим было понятно, с чем они столкнутся на Блице, мы решили разобрать пару похожих задач на Хабре.
 Приветствую вас, коллеги. Оказывается, не все компьютерное зрение сегодня делается с использованием нейронных сетей. Хотя многие стартапы и заявляют, что у них дип лернинг везде, спешу вас разочаровать, они просто хотят хайпануть немножечко. Рассмотрим, например, задачу сегментации. В нашем слаке развернулась целая драма. Одна богатая и высокотехнологичная селфи-компания собрала датасет для сегментации селфи с помощью нейросетей (а это непростое и недешевое занятие). А другая, более бедная и не очень развитая решила, что можно подкупить людей, размечающих фотки, и
Приветствую вас, коллеги. Оказывается, не все компьютерное зрение сегодня делается с использованием нейронных сетей. Хотя многие стартапы и заявляют, что у них дип лернинг везде, спешу вас разочаровать, они просто хотят хайпануть немножечко. Рассмотрим, например, задачу сегментации. В нашем слаке развернулась целая драма. Одна богатая и высокотехнологичная селфи-компания собрала датасет для сегментации селфи с помощью нейросетей (а это непростое и недешевое занятие). А другая, более бедная и не очень развитая решила, что можно подкупить людей, размечающих фотки, и спполучить базу. В общем, страсти в этих ваших Интернетах еще те. Недавно я наткнулся на статью, где без всяких нейросетей на устройстве делают очень даже хорошую сегментацию. Для сегментации от пользователя требуется дать алгоритму несколько подсказок, но с помощью dlib и opencv такие подсказки легко автоматизируются. В качестве бонуса мы так же сгладим вырезанное лицо и перенесем на какого-нибудь рандомного человека, тем самым поймем, как работают маски во всех этих снапчятах и маскарадах. В общем, классика еще жива, и если вы хотите немного окунуться в классическое компьютерное зрение на питоне, то добро пожаловать под кат.


Большинство присутствующих в аудитории поднимают руки 
Глубинное обучение в последние годы стало ключевым направлением исследований в машинном обучении. Начавшись с архитектурных прорывов, позволявших эффективно обучать глубокие нейросети, оно стало распространяться на другие подобласти, предоставляя набор эффективных средств там, где для решения задачи требуется приближение некоторой сложной функции.
Многие современные исследовательские статьи активно используют байесовский формализм в сочетании с глубокими нейросетями, приходя к интересным результатам. Мы – исследовательская группа BayesGroup с помощью наших друзей из Сколтеха, а так же при поддержке Высшей Школы Экономики, Сбербанка, Яндекса, Лаборатории Касперского, JetBrains и nVidia – решили поделиться накопленным опытом и устроить летнюю школу по байесовским методам в глубинном обучении Deep|Bayes, где подробно рассказать, что такое байесовские методы, как их комбинировать с глубинным обучением и что из этого может получиться.
Отбор на школу оказался весьма сложным занятием – мы получили более 300 заявок от сильных кандидатов, но вместить смогли только 100 (приятно, что среди участников были не только жители Москвы и Петербурга, но и студенты из регионов, а так же русскоговорящие гости из-за границы). Пришлось отказать многим сильным кандидатам, поэтому для смягчения этого прискорбного факта мы решили сделать доступными максимальное количество материалов, которыми и хотим поделиться с хабраюзерами.

 Дмитрий Бугайченко. Закончил Санкт-Петербургский Государственный Университет в 2004 году, там же защитил кандидатскую по формально-логическим методам в 2007. Почти 9 лет проработал в аутсорсинге, не теряя контакта с университетом и научной средой. Анализ больших данных в Одноклассниках стал для Дмитрия уникальным шансом совместить теоретическую подготовку и научный фундамент с разработкой реальных и востребованных продуктов.
Дмитрий Бугайченко. Закончил Санкт-Петербургский Государственный Университет в 2004 году, там же защитил кандидатскую по формально-логическим методам в 2007. Почти 9 лет проработал в аутсорсинге, не теряя контакта с университетом и научной средой. Анализ больших данных в Одноклассниках стал для Дмитрия уникальным шансом совместить теоретическую подготовку и научный фундамент с разработкой реальных и востребованных продуктов.
За лето в офисе Mail.Ru Group прошли пять митапов, выступлениями с которых мы с вами сегодня поделимся. Каждое видео — доклад, рассказывающий о последних новостях и технологиях в различных областях. Просмотр позволит вам идти в ногу с профессиональными сообществами.
Ниже мы публикуем подборку видео с митапов лета 2017-го:

Привет.
Я впервые пишу в поток об управлении и найме персонала. Речь пойдет об одном из способов классифицировать ваших будущих или действующих программистов. Мой основной тезис: все разработчики, грубо говоря, делятся на 4 больших типажа и каждому из этих типажей есть своя область применения. Попытка направить неправильный типаж на решение неподходящих для него задач ведет к провалу (неэффективная работа, или сотрудник покидает команду). Хотите знать почему так — добро пожаловать под кат. Приготовьтесь, текста много.
float FastInvSqrt(float x) {
float xhalf = 0.5f * x;
int i = *(int*)&x; // представим биты float в виде целого числа
i = 0x5f3759df - (i >> 1); // какого черта здесь происходит ?
x = *(float*)&i;
x = x*(1.5f-(xhalf*x*x));
return x;
}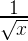

Все справочники из этой статьи бесплатны и открыто лежат в интернете. Ни один не украли из ФСБ таинственные хакеры.