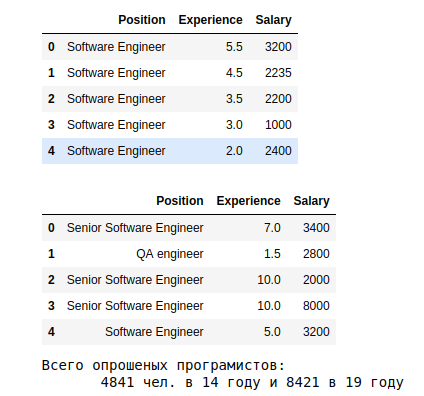
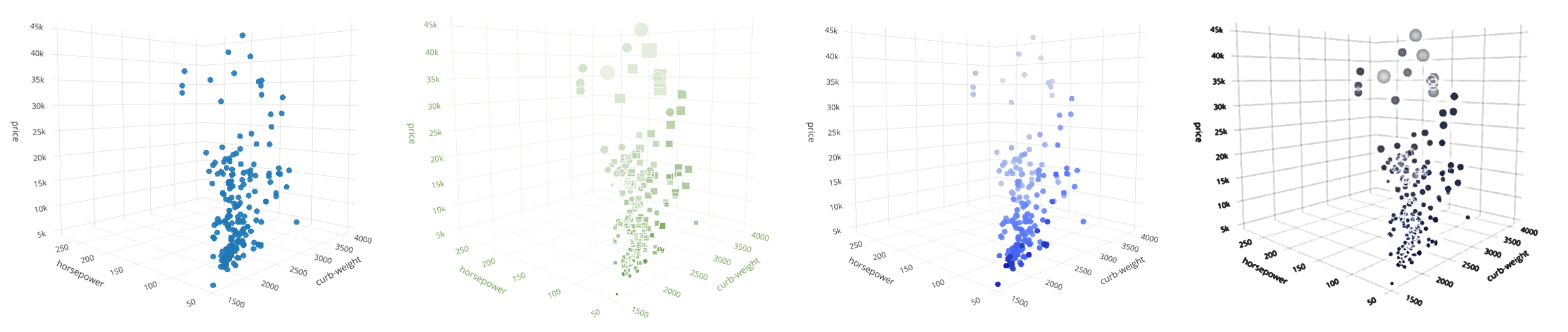
Хватит создавать ветвящиеся пути, начинайте использовать циклическую генерацию подземелий. Ваши уровни станут гораздо более похожими на созданные вручную.
Чаще всего для генерации подземелий в играх жанра roguelike на карту добавляются сгенерированные или заранее созданные фрагменты подземелья. Подземелье вырастает из начальной точки подобно дереву. Однако деревья заканчиваются ветвями, что приводит к созданию множества тупиков. Чтобы обойти эту проблему, большинство генераторов подземелий ищут места, в которых можно случайным образом соединить ветви, чтобы игрок мог двигаться по кругу, а не возвращаться постоянно назад.
В dungeon crawler'е Unexplored использован фундаментально иной подход (см. рисунок 1). Вместо линейных путей в качестве самой базовой структуры он изначально использует циклы. Разница оказывается поразительной: при старом подходе хорошие и интересные циклы могли возникать случайно, а в Unexplored они являются запланированной особенностью результата работы генератора.