Запрос на бесконечное продление жизни (жизнь после смерти) присутствует практически во все время существования человечества. Ответы на этот запрос пытаются дать большинство религий. Есть и чисто коммерческая эксплуатация данной темы: криозаморозки различной направленности и полная запись жизни человека для создания правдоподобной посмертной его копии. Все эти способы не дают истинного продления жизни, скорее психотерапевтический и манипуляционный эффект для живущих людей.

Data Scientist
Структура Data Science-проекта с высоты птичьего полета
6 min
Как узнать наверняка, что внутри у колобка?
Может, ты его проглотишь, а внутри него река? © Таня Задорожная
Что такое Data Science сегодня, кажется, знают уже не только дети, но и домашние животные. Спроси любого котика, и он скажет: статистика, Python, R, BigData, машинное обучение, визуализация и много других слов, в зависимости от квалификации. Но не все котики, а также те, кто хочет стать специалистом по Data Science, знают, как именно устроен Data Science-проект, из каких этапов он состоит и как каждый из них влияет на конечный результат, насколько ресурсоемким является каждый из этапов проекта. Для ответа на эти вопросы как правило служит методология. Однако бОльшая часть обучающих курсов, посвященных Data Science, ничего не говорит о методологии, а просто более или менее последовательно раскрывает суть упомянутых выше технологий, а уж со структурой проекта каждый начинающий Data Scientist знакомится на собственном опыте (и граблях). Но лично я люблю ходить в лес с картой и компасом и мне нравится заранее представлять план маршрута, которым двигаешься. После некоторых поисков неплохую методологию мне удалось найти у IBM — известного производителя гайдов и методик по управлению чем угодно.
YOLOv4 – самая точная real-time нейронная сеть на датасете Microsoft COCO
9 min
Darknet YOLOv4 быстрее и точнее, чем real-time нейронные сети Google TensorFlow EfficientDet и FaceBook Pytorch/Detectron RetinaNet/MaskRCNN.
Эта же статья на medium: medium
Код: github.com/AlexeyAB/darknet
Статья: arxiv.org/abs/2004.10934
Обсуждение YOLOv4-tiny 1770 FPS: www.reddit.com/r/MachineLearning/comments/hu7lyt/p_yolov4tiny_speed_1770_fps_tensorrtbatch4
Обсуждение: www.reddit.com/r/MachineLearning/comments/gydxzd/p_yolov4_the_most_accurate_realtime_neural

Мы покажем некоторые нюансы сравнения и использования нейронных сетей для обнаружения объектов.
Нашей целью было разработать алгоритм обнаружения объектов для использования в реальных продуктах, а не только двигать науку вперед. Точность нейросети YOLOv4 (608x608) – 43.5% AP / 65.7% AP50 Microsoft-COCO-testdev.
62 FPS – YOLOv4 (608x608 batch=1) on Tesla V100 – by using Darknet-framework
400 FPS – YOLOv4 (320x320 batch=4) on RTX 2080 Ti – by using TensorRT+tkDNN
32 FPS – YOLOv4 (416x416 batch=1) on Jetson AGX Xavier – by using TensorRT+tkDNN

Эта же статья на medium: medium
Код: github.com/AlexeyAB/darknet
Статья: arxiv.org/abs/2004.10934
Обсуждение YOLOv4-tiny 1770 FPS: www.reddit.com/r/MachineLearning/comments/hu7lyt/p_yolov4tiny_speed_1770_fps_tensorrtbatch4
Обсуждение: www.reddit.com/r/MachineLearning/comments/gydxzd/p_yolov4_the_most_accurate_realtime_neural
Мы покажем некоторые нюансы сравнения и использования нейронных сетей для обнаружения объектов.
Нашей целью было разработать алгоритм обнаружения объектов для использования в реальных продуктах, а не только двигать науку вперед. Точность нейросети YOLOv4 (608x608) – 43.5% AP / 65.7% AP50 Microsoft-COCO-testdev.
62 FPS – YOLOv4 (608x608 batch=1) on Tesla V100 – by using Darknet-framework
400 FPS – YOLOv4 (320x320 batch=4) on RTX 2080 Ti – by using TensorRT+tkDNN
32 FPS – YOLOv4 (416x416 batch=1) on Jetson AGX Xavier – by using TensorRT+tkDNN
Играем с CLIP. Создаем универсальный zero-shot классификатор на Android
9 min
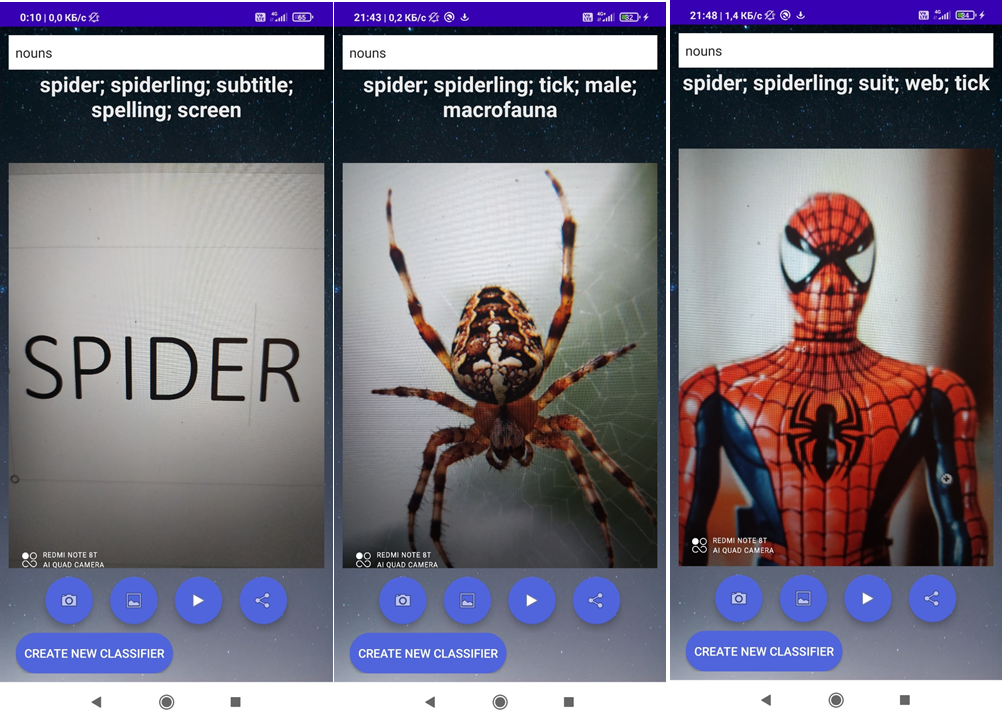
TLDR: приложение можно скачать и потестить тут
Эта статья является дополненной и сильно расширенной версией моей статьи в TowardsDataScience о создании приложения, использующем новейшую мультимодальную нейросеть от OpenAI
В чем проблема классификаторов?
Многие заметили, что в последние годы все чаще для обработки изображений используется нейросетевой подход.
37 причин, почему ваша нейросеть не работает
9 min
Tutorial
Translation
Сеть обучалась последние 12 часов. Всё выглядело хорошо: градиенты стабильные, функция потерь уменьшалась. Но потом пришёл результат: все нули, один фон, ничего не распознано. «Что я сделал не так?», — спросил я у компьютера, который промолчал в ответ.
Почему нейросеть выдаёт мусор (например, среднее всех результатов или у неё реально слабая точность)? С чего начать проверку?
Сеть может не обучаться по ряду причин. По итогу многих отладочных сессий я заметил, что часто делаю одни и те же проверки. Здесь я собрал в удобный список свой опыт вместе с лучшими идеями коллег. Надеюсь, этот список будет полезен и вам.
Почему нейросеть выдаёт мусор (например, среднее всех результатов или у неё реально слабая точность)? С чего начать проверку?
Сеть может не обучаться по ряду причин. По итогу многих отладочных сессий я заметил, что часто делаю одни и те же проверки. Здесь я собрал в удобный список свой опыт вместе с лучшими идеями коллег. Надеюсь, этот список будет полезен и вам.
Автоэнкодеры и сильный искусственный интеллект
16 min
Теория автоэнкодеров и генерирующих моделей последнее время получила серьезное развитие, но достаточно мало работ посвящено тому, как можно использовать их в задачах распознавания. При этом свойство автоэнкодеров получать скрытую параметрическую модель данных и математические следствия из этого дают возможность связать их с Байесовскими методами принятия решения.
В статье предложен оригинальный математический аппарат «набор автоэнкодеров с общим латентным пространством», который позволяет выделять абстрактные понятия из входных данных и демонстрирует способность к «one-shot learning». Кроме того, с его помощью можно преодолеть многие фундаментальные проблемы современных алгоритмов машинного обучения, основанных на многослойных сетях и подходе «Deep learning».
В статье предложен оригинальный математический аппарат «набор автоэнкодеров с общим латентным пространством», который позволяет выделять абстрактные понятия из входных данных и демонстрирует способность к «one-shot learning». Кроме того, с его помощью можно преодолеть многие фундаментальные проблемы современных алгоритмов машинного обучения, основанных на многослойных сетях и подходе «Deep learning».
Квантование эмбеддингов: что это, зачем оно нужно и как его правильно готовить
8 min
Привет, меня зовут Женя. Сегодня я расскажу, что такое квантование эмбеддингов, какие бывают способы квантования и как с их помощью мы в Яндекс.Дзене смогли сократить использование памяти, рейта записи и сетевого трафика в четыре раза. Будет совсем немного математики, умеренно размышлений о machine learning, highload и big data и много разноцветных картинок.
Эмбеддинг — числовой вектор, который каким-то (в общем случае непонятным на глаз) образом характеризует интересы пользователя или контент. Например, эмбеддинги могут быть такими.

У каждого пользователя и карточки может быть несколько эмбеддингов разных типов. В основном используются два вида эмбеддингов.
Что такое эмбеддинги?
Эмбеддинг — числовой вектор, который каким-то (в общем случае непонятным на глаз) образом характеризует интересы пользователя или контент. Например, эмбеддинги могут быть такими.
У каждого пользователя и карточки может быть несколько эмбеддингов разных типов. В основном используются два вида эмбеддингов.
Сознание и тезис Макса Фрая
26 min

С древних времен считалось, что в феномене сознания есть что-то непонятное. Что-то непостижимое. Считалось, что сознание есть проявление нематериального, привнесенного высшими силами. Если для мифологического мировосприятия такой порядок вещей естественен, то со сменой парадигм и зарождением естествознания феномен сознания потребовал объяснения.
World Models — обучение в воображении
10 min
Обучение с подкреплением (Reinforcement Learning) плохо, а точнее, совсем не работает с высокими размерностями. А также сталкивается с проблемой, что физические симуляторы довольно медленные. Поэтому в последнее время стал популярен способ обойти эти ограничения с помощью обучения отдельной нейросети, которая имитирует физический движок. Получается что-то вроде аналога воображения, в котором и происходит дальнейшее основное обучение.
Давайте посмотрим, какой прогресс достигнут в этой сфере и рассмотрим основные архитектуры.
D&D-классы для разработчиков
10 min
Translation
Вам кажется, что разработка ПО похожа на большую и плохо структурированную RPG, хотя никто не признаёт этого на собеседованиях? Тогда эта классификация вам понравится.

Как Reinforcement Learning помогает ритейлерам
14 min
Введение
Привет! Наша команда Glowbyte Advanced Analytics разрабатывает ML-решения для прикладных индустрий (ритейл, банки, телеком и др). Многие задачи требуют нестандартных решений. Одно из них — оптимизация цепочек коммуникаций с клиентом с помощью Reinforcement Learning (RL), которому мы решили посвятить данную статью.
Мы разбили статью на три блока: введение в задачу оптимизации цепочек коммуникаций; введение в RL; а в третьем блоке мы объединяем 1 и 2 вместе.

GPT-3 от OpenAI может стать величайшей вещью со времён Bitcoin
4 min
Translation
Резюме: Я делюсь своими ранними экспериментами с бета-версией новой модели прогнозирования языка OpenAI (GPT-3). Я объясняю своё мнение, что GPT-3 обладает революционным потенциалом, сравнимым с блокчейн-технологией.

Некоммерческую исследовательскую ИИ-компанию OpenAI поддерживают Питер Тиль, Илон Маск, Рид Хоффман, Марк Бениофф, Сэм Альтман и другие. Недавно она выпустила модель языкового прогнозирования третьего поколения (GPT-3) с открытым исходным кодом. Языковые модели позволяют компьютерам создавать случайные предложения приблизительно той же длины и грамматической структуры, что и заданные в качестве образца.
В моих ранних экспериментах с GPT-3 я обнаружил, что предсказанные предложения GPT-3, опубликованные на форуме bitcointalk.org, привлекли много положительного внимания со стороны форумчан, включая предположения о том, что автор должен быть умным (и/или саркастичным) и что в его сообщениях есть тонкие паттерны. Полагаю, аналогичные результаты можно получить, опубликовав выдачу GPT-3 на других форумах, в блогах и социальных сетях.
Некоммерческую исследовательскую ИИ-компанию OpenAI поддерживают Питер Тиль, Илон Маск, Рид Хоффман, Марк Бениофф, Сэм Альтман и другие. Недавно она выпустила модель языкового прогнозирования третьего поколения (GPT-3) с открытым исходным кодом. Языковые модели позволяют компьютерам создавать случайные предложения приблизительно той же длины и грамматической структуры, что и заданные в качестве образца.
В моих ранних экспериментах с GPT-3 я обнаружил, что предсказанные предложения GPT-3, опубликованные на форуме bitcointalk.org, привлекли много положительного внимания со стороны форумчан, включая предположения о том, что автор должен быть умным (и/или саркастичным) и что в его сообщениях есть тонкие паттерны. Полагаю, аналогичные результаты можно получить, опубликовав выдачу GPT-3 на других форумах, в блогах и социальных сетях.
Подборка статей о машинном обучении: кейсы, гайды и исследования за январь 2020
5 min
Исследовательская работа в области машинного обучения постепенно покидает пределы университетских лабораторий и из научной дисциплины становится прикладной. Тем не менее, все еще сложно находить актуальные статьи, которые написаны на понятном языке и без миллиарда сносок.
Этот пост содержит список англоязычных материалов за январь, которые написаны без лишнего академизма. В них вы найдете примеры кода и ссылки на непустые репозитории. Упомянутые технологии лежат в открытом доступе и не требуют сверхмощного железа для тестирования.
Этот пост содержит список англоязычных материалов за январь, которые написаны без лишнего академизма. В них вы найдете примеры кода и ссылки на непустые репозитории. Упомянутые технологии лежат в открытом доступе и не требуют сверхмощного железа для тестирования.
Искусственный интеллект общего назначения. ТЗ, текущее состояние, перспективы
12 min
В наше время словами «искусственный интеллект» называют очень много различных систем — от нейросети для распознавания картинок до бота для игры в Quake. В википедии дано замечательное определение ИИ — это «свойство интеллектуальных систем выполнять творческие функции, которые традиционно считаются прерогативой человека». То есть из определения явно видно — если некую функцию успешно удалось автоматизировать, то она перестаёт считаться искусственным интеллектом.
Тем не менее, когда задача «создать искусственный интеллект» была поставлена впервые, под ИИ подразумевалось нечто иное. Сейчас эта цель называется «Сильный ИИ» или «ИИ общего назначения».
Тем не менее, когда задача «создать искусственный интеллект» была поставлена впервые, под ИИ подразумевалось нечто иное. Сейчас эта цель называется «Сильный ИИ» или «ИИ общего назначения».
Нейросети. Куда это все движется
7 min
Статья состоит из двух частей:
- Краткое описание некоторых архитектур сетей по обнаружению объектов на изображении и сегментации изображений с самыми понятными для меня ссылками на ресурсы. Старался выбирать видео пояснения и желательно на русском языке.
- Вторая часть состоит в попытке осознать направление развития архитектур нейронных сетей. И технологий на их основе.

Рисунок 1 – Понимать архитектуры нейросетей непросто
Все началось с того, что сделал два демонстрационных приложения по классификации и обнаружению объектов на телефоне Android:
- Back-end demo, когда данные обрабатываются на сервере и передаются на телефон. Классификация изображений (image classification) трех типов медведей: бурого, черного и плюшевого.
- Front-end demo, когда данные обрабатываются на самом телефоне. Обнаружение объектов (object detection) трех типов: фундук, инжир и финик.
Что не так с обучением с подкреплением (Reinforcement Learning)?
21 min
Tutorial

Еще в начале 2018 года вышла статья Deep Reinforcement Learning Doesn't Work Yet ("Обучение с подкреплением пока не работает"). Основная претензия которой сводилась к тому, что современные алгоритмы обучения с подкреплением требуют для решения задачи примерно столько же времени, как и обычный случайный поиск.
Изменилось ли что-то с того времени? Нет.
Обучение с подкреплением считается одним из трех основных путей к созданию сильного ИИ. Но трудности, с которыми сталкивается эта область машинного обучения, и методы, которыми ученые пытаются бороться с этими трудностями, наводят на мысль что, возможно, с самим этим подходом имеются фундаментальные проблемы.
Невидимая фотография
4 min

О чём речь?
Знакомые часто интересуются: зачем я занимаюсь невидимой фотографией? Инфракрасной, ультрафиолетовой, тепловой. Неужели там есть что-то интересное?
Поскольку лучше один раз увидеть, чем сто раз услышать, то вот вам небольшая демка. С 15-ю предметами. Здесь они в видимом спектре, а дальше мы на них посмотрим в других диапазонах:

[Видимый свет, 400-750 нм. F/6.3, 1/2500 сек, ISO 200, стеклянная 35-мм линза Nikkor. Снято на модифицированный Nikon D90 с удалёнными внутренними ИК/УФ фильтрами через светофильтр видимого света Kolari Vision Hot Mirror UV/IR Cut filter.]
Интуитивный RL (Reinforcement Learning): введение в Advantage-Actor-Critic (A2C)
6 min
Привет, Хабр! Предлагаю вашему вниманию перевод статьи Rudy Gilman и Katherine Wang Intuitive RL: Intro to Advantage-Actor-Critic (A2C).

Специалисты по обучению с подкреплением (RL) подготовили множество отличных учебных пособий. Большинство, однако, описывают RL в терминах математических уравнений и абстрактных диаграмм. Нам нравится думать о предмете с другой точки зрения. Сама RL вдохновлена тем, как учатся животные, так почему бы не перевести лежащий в основе этого механизм RL обратно в природные явления, которые он призван имитировать? Люди учатся лучше всего через истории.
Это история о модели Actor Advantage Critic (A2C). Модель «Субъект-критик» — это популярная форма модели Policy Gradient, которая сама по себе является традиционным алгоритмом RL. Если вы понимаете A2C, вы понимаете глубокий RL.
PDDM — Новый Model-Based Reinforcement Learning алгоритм с улучшенным планировщиком
7 min

Обучение с подкреплением (Reinforcement Learning) делится на два больших класса: Model-Free и Model-Based. В первом случае действия оптимизируются напрямую по сигналу награды, а во втором нейросеть является только моделью реальности, а оптимальные действия выбираются с помощью внешнего планировщика. У каждого подхода есть свои достоинства и недостатки.
Разработчики из Berkeley и Google Brain представили Model-Based алгоритм PDDM с улучшенным планировщиком, позволяющий эффективно обучаться сложным движениям с большим числом степеней свободы на небольшом числе примеров. Чтобы научиться вращать мячи в роботизированной руке с реалистичными суставами пальцев с 24 степенями свободы, потребовалось всего 4 часа практики на реальном физическом роботе.
Как мы обучали приложение Яндекс.Такси предсказывать пункт назначения
7 min
Представьте: вы открываете приложение, чтобы в очередной раз заказать такси в часто посещаемое вами место, и, конечно, в 2017 году вы ожидаете, что все, что нужно сделать – сказать приложению «Вызывай», и такси за вами тут же выедет. А куда вы хотели ехать, через сколько минут и на какой машине — все это приложение узнает благодаря истории заказов и машинному обучению. В общем-то все, как в шутках про идеальный интерфейс с единственной кнопкой «сделать хорошо», лучше которого только экран с надписью «все уже хорошо». Звучит здорово, но как же приблизить эту реальность?

На днях мы выпустили новое приложение Яндекс.Такси для iOS. В обновленном интерфейсе один из акцентов сделан на выборе конечной точки маршрута («точки Б»). Но новая версия – это не просто новый UI. К запуску обновления мы существенно переработали технологию прогнозирования пункта назначения, заменив старые эвристики на обученный на исторических данных классификатор.
Как вы понимаете, кнопки «сделать хорошо» в машинном обучении тоже нет, поэтому простая на первый взгляд задача вылилась в довольно захватывающий кейс, в результате которого, мы надеемся, у нас получилось немного облегчить жизнь пользователей. Сейчас мы продолжаем внимательно следить за работой нового алгоритма и еще будем его менять, чтобы качество прогноза было стабильнее. На полную мощность запустимся в ближайшие несколько недель, но под катом уже готовы рассказать о том, что же происходит внутри.
На днях мы выпустили новое приложение Яндекс.Такси для iOS. В обновленном интерфейсе один из акцентов сделан на выборе конечной точки маршрута («точки Б»). Но новая версия – это не просто новый UI. К запуску обновления мы существенно переработали технологию прогнозирования пункта назначения, заменив старые эвристики на обученный на исторических данных классификатор.
Как вы понимаете, кнопки «сделать хорошо» в машинном обучении тоже нет, поэтому простая на первый взгляд задача вылилась в довольно захватывающий кейс, в результате которого, мы надеемся, у нас получилось немного облегчить жизнь пользователей. Сейчас мы продолжаем внимательно следить за работой нового алгоритма и еще будем его менять, чтобы качество прогноза было стабильнее. На полную мощность запустимся в ближайшие несколько недель, но под катом уже готовы рассказать о том, что же происходит внутри.