Comments 50
Ладно бы еще была инфраструктура автоматического поиска сложноформализуемой информации — т.е. я даю нейросети подборку картинок и говорю «найди мне все похожие в инете», и оставляю компьютер на ночь — ну так ведь тут именно инфраструктура нужна. И картинки — самое примитивное (с чем современные нейросети вероятно справятся), а если нужны более сложные задачи — поиск и подборка текстовой информации на определенную тему?
Постепенно ведутся работы по преобразованию текста в изображение: вы пишете текст, а нейросеть рисует картинку.
У меня есть идея сделать регулярные публикации по новинкам машинного обучения. Там даю разные идеи по применению нейросетей. Я уже сделал 5 рассылок, а шестую и далее планирую публиковать на Хабре.
Поднятие шлагбаума только для номеров авто из жильцов дома.А так же для машин скорой помощи, пожарных, полиции и больших грузовых мусорных машин. Было бы супер. Каждое товарищество жильцов, которое хочет поставить шлагбаум задается вопросом кто будет впускать во двор все эти спец-автомобили.
Спасибо за подборку.
На конвейере отсеивание гнилых яблок и картошки
Можно ещё делать binning: лучшие яблоки продаём как 1ый сорт, хорошие — как 2ой сорт, средние — в компот/варенье, худшие — на биомассу.
Наверное, используя такое можно оптимизировать/корректировать цену закупки у поставщиков.
Какая эпоха, функциональные преобразования ещё на специальных лампах делались, а классификаторы, ладно а то вдруг там до сих пор какая тайна, не суть…
… если копнуть в глубь, то свойства элементов составляющих зоопарки станут очевидны, как и свойства "топологий" и уже ничего не будет новым даже казаться, разве что биология будет ещё подбрасывать массу интересных идей, но юпитером их не проверить
Прогресса в паблике нет и не будет, снизили порог вхождения, получили тонны публикаций соответствующего уровня.
Под «эпохой» имеются ввиду скорее технические новинки, чем теоретические выкладки математиков. Уверен, у математиков есть методы покруче, чем метод обратного распространения ошибки, но у них как-то времени нет объяснить мне, программисту, как это запрограммировать, чтобы работало.
Есть притча о глиняных горшках:
Однажды преподаватель гончарного дела провёл любопытный эксперимент. Он разделил студентов на две части и дал им разные задания. Первой половине студентов гончар поручил сделать всего один горшок. Он сказал, что будет оценивать их труд по качеству этого горшка: чем лучше у них выйдет горшок, тем выше будет оценка.
Второй половине студентов гончар сказал «гнать вал»: сделать по 50 горшков на человека. Дескать, сдаёте 50 неказистых горшков, и пять баллов у вас в кармане.
По окончании семестра внезапно выяснилось, что горшки «халтурщиков» получились гораздо качественнее, чем горшки «перфекционистов». Так как халтурщики учились на ошибках, и каждый следующий горшок получался у них лучше предыдущего.
Джоэл уже слышал эту историю. Коронная фраза как-то связана со сломанными часами, если он все помнит точно.
– Эти штуки вроде как учатся на собственном опыте, правильно? – продолжает Джарвис. – Ну и все думали, что зельц научился запускать вентиляторы по какому-то очевидному признаку. Жару тела, движению, уровню углекислого газа, ну ты понимаешь. В результате выяснилось, что эта хрень просто смотрела за часами на стене. Прибытие поезда совпадало с предсказуемым набором паттернов на цифровом дисплее, поэтому она включала вертушки, когда видела один из них.
– Ага. Точно. – Джоэл качает головой. – А какие-то вандалы часы разбили.
(«Морские звёзды», Питер Уоттс)
По мнению специалистов опасность ИИ не в том, что он нас всех поработит, а в убийственной простоте. В общем, это стремление к простоте является проблемой всех нейросетей, в том числе и биологических.
Это примерно как обвинить цемент в том, что мост упал.
Если распространённая технология обычно хорошо работает, а в конкретном редком случае всё закончилось факапом, это наводит на мысли, что всё-таки не технология виновата, а проектировщики, неправильно её применившие.
Yolo (включая последнюю третью версию YOLO3) и SSD, не говоря о древних R-CNN и аналогах, уже устарели. Их имеет смысл использовать только если есть ограничения, например запуск на мобильной платформе очень упрощённые версии этих сетей. Они могут распознавать только крупные объекты и работают с маленькими разрешениями от 224х224 до 300-600 максимум. После них появилась архитектура RetinaNet, которая сразу нормально работает с разрешениями под 1300х800 и распознает мелкие объекты размером с десяток пикселей. Однако и она уже устарела. Ей на смену пришли более новые CenterNet и EfficientDet, которые так же хорошо распознают мелкие детали, но работают точнее и быстрее. Эти нейросети снова вернули времена, когда на одном GPU за пару дней можно было обучить state-of-the-art распознавалку на конкурс. Из старых сетей разве что Faster R-CNN и пара AutoML моделей от гугла ещё удерживают позиции, но они очень медленные (хотя FasterRCNN и была в свое время самая быстрая из своего семейства).
Просто смотрите графики
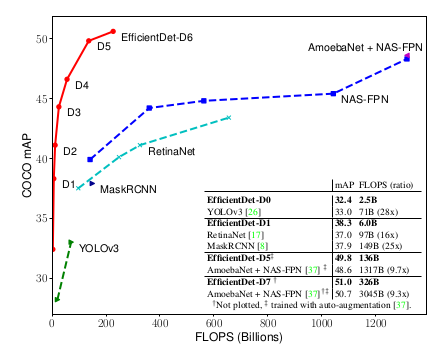

Уточнение: под CenterNet я имел ввиду CenterNet: Objects as Points, потому что есть ещё с таким же названием CenterNet: Keypoint Triplets for Object Detection. Они вроде вышли с разницей в пару дней, поэтому получилась путаница с названиями. Первая лучше. Вторая является развитием предыдущего поколения CornerNet, и скорее всего повлияла на последние тенденции отказа от регионов при поиске объектов, но судя по результатам, уступает по скорости и точности той что Objects as Points.

Сюда конечно не вошли ещё много других интересных статей, которые сравнивают по inference time. Данные поэтому далеко неполные и возможно не очень точные, но какое-то представление о более-менее быстрых вариантах даёт. В частности, может быть кому-то будет интересно посмотреть на SM-NAS и DetNASNet, который даже в чём-то лучше чем EfficientDet.

Почему убрали DetNASNet? Выглядит интересно.
Ясно, спасибо. Насколько я понимаю, в модели могут быть сохранены параметры оптимизатора, чтобы можно было продолжить обучение. Т.е. полный checkpoint. Что запросто может увеличить размер сети раза в три. Особенно с адаптивными оптимизаторами, такими как adam, так как они для каждого веса еще хранят свои параметры. Но все зависит от того в чем обучали нейросеть и в каком виде ее сохранили, конечно.
2. Google и некоторые другие пишут значение BFLOPS в 2 раза меньше (они считают 2 (операции умножение и последующее сложение) за одну FMA-операцию, т.к. в их железе Google ASIC TPU v3 это выполнено как один конвейер). Т.е. когда Google пишет про свои нейронки MixNet/EfficientDet/EfficientNet, то он считает 2 операции за 1, и занижает BFLOPS в 2 раза, а когда Google пишет про своё железо TPU, то уже считает 2 операции за 2 :) Т.е. даже Google на официальном уровне манипулирует данными, то FMA это 1 операция, то это 2 операции.
В nVidia GPU или в сетях Yolo сколько операций есть — столько и пишется.
3. MixNet, EfficientNet, EfficientDet, MobileNetV3, GhostNet,… — имеют в ~20 раз меньше BFLOPS, чем другие модели с той же точностью, но при этом в ~2 раза медленнее их на GPU/TPUv3. Это из-за depthwise/groped-convolutional, которые выполняются крайне медленно на GPU/TPUv3. Поэтому даже Google в статьях публикует EfficientDet/Net с низкими BFLOPS (depthwise/groped-convolutional), а в продакшене использует сети без depthwise/groped-convolutional и без SE-блоков под названием EfficientNet-TPU-edge: ai.googleblog.com/2019/08/efficientnet-edgetpu-creating.html
Вычисления depthwise/groped-convolutional слоев очень плохо распараллеливаются, поэтому на 1-потоке CPU они работают быстро, на множестве потоков с SIMD работают не сильно ускоряются, а на GPU/TensorCores/TPU работают медленнее, чем обычные convolutional-слои.
Поэтому малое значение BFLOPS ещё не значит, что сеть будет быстрая.
4. Размер файла весов зависит от (размера_фильтра * количество_фильтров * колво_каналов / колво_групп), а BFLOPS зависит от ещё от размера_слоя. При этом колво_групп может снижать файл весов и BFLOPS, но увеличивать время выполнения. Поэтому размер файла весов, BFLOPS и FPS могут вообще не коррелировать.
5. CSP простая и хорошая идея arxiv.org/abs/1911.11929v1 — делать Concatenate = (выходов после предыдущего subsampling) + (перед следующим subsampling). Применяется к любой модели, позволяет строить сети ещё глубже, чем с обычным Residual-connection и улучшает точность.

YOLO, SSD и rcnn(masc-rcnn) много где используют и работают они вполне достойно. Особенно если обучать на собственных данных (почти все предобученные сетки из коробки работают паршиво). Во всяком случае почти все с кем я говорил от конференций типа "machines can see" до всем известных компаний.
YOLO3, как скорее всего и остальные версии YOLO работают с частью кадра 30x30 пикселей, что позволяет детектить мелкиме объекты в том числе, если увеличить размер входного изображения (меняется в .cfg).
Незря YOLO добавили в visionworks.
С CenterNet и EfficientDet попробую поработать, но ещё пока не было ни одной статьи, где бы "достижения" не были преувеличены, так что все нужно проверять
По моему мнению есть достойный ресурс, где можно понять, какая сетка "круче":
https://paperswithcode.com/task/object-detection
Поэтому появилась необходимость узнать, какие архитектуры нейросетей обнаруживают объекты на изображениях…
Object Detection in 20 Years: A Survey — хорошая обзорная статья. В частности, отвечает на вопрос «куда это все движется» в отношении object detection. Из последних достижений, не отмеченных в этой обзорной статье, можно добавить: EfficientDet, SpineNet, CSPNet…
По мере изучения этих архитектур я понял, что ничего не понимаю… Нет системного мышления! Не понятно, что менять и как оптимизировать имеющиеся достижения… Постепенное уменьшение точности и увеличение скорости вычислений: нечеткая логика, алгоритмы бустинга ...
Вы за какое время попытались изучить имеющиеся достижения? Не похоже, что вы этим уже давно занимаетесь.
Сам не программист, только увлекаюсь C# (пишу небольшие приложения для автоматизации проектирования для AutoCad). Работаю проектировщиком (сотовая связь). В мыслях написать программу которая по фотографиям объекта составит список оборудования. Но в какую сторону смотреть ни знаю, глаза разбегаются, инфы много, но очень сложно для понимания.
Машинное обучение — это прикладная область знания. Только решением задач можно научиться чему-то конкретному.
А почему только нейросети? Собственно свёртка вообще никак к нейросетям не относится. То же самое можно сказать о куче других алгоритмов. И вот эта «куча» осталась вне поля зрения.
Хотя понятно, что шума вокруг сетей гораздо больше, чем вокруг несетевых алгоритмов, но сдаётся мне, что всё разнообразие сетей во многом основано именно на разнообразии этих других алгоритмов. То есть прикручивают сеть к ранее полученному алгоритму (как вот к свёртке прикрутили) и получают новую возможность для очередной рекламной кампании, мол новейшая технология, мега-супер-вундер-достижения и т.д. Пилить венчурные инвестиции — самое оно.
А почему только нейросети?
На кучу других алгоритмов мало обращают внимание может потому, что только нейронные сети дали огромный скачок точности в большинстве рейтингов, по сравнению с этой кучей: https://arxiv.org/pdf/1905.05055v2.pdf
Вот DPM не нейронка, а все остальные в топе — только нейронки. Т.е. дело не только в рекламной компании.
Как только в топ рейтингка попадет дргой алгоритм (не нейронка) — все переключатся на него.

— обучение чему-то новому требует огромных массивов информации, т.е. не одна условная фотка, а целые размеченные датасеты
— обучение новому приводит к стиранию старой памяти. Нейросеть либо «цементируется» и не может обучатся, либо обучается новому ценой потери старой модели
Первая проблема решалась с помощью более мощного железа. Вторая проблема решается либо добавлением старого датасета к новому, либо что-то новое должна узнавать уже новая нейросеть, которая подсоединяется к старой.
Мои ожидания? Смена концепции на что-то более оригинальное, например, идеи Редозубова "Логика сознания"
И даже неплохая реализация на распознавании автомобильных номеров. Обычные нейросети натравливают сразу на цифры и из-за шума/грязи будет множество ложных срабатываний. Но если вначале определить границы самого автомобильного номера, а потом натравливать на конкретные зоны, то «вот эта грязь на самом деле цифра».
Преимущества:
1) память отделена от сверточной нейросети
2) учет множества искажений, кроме сдвига еще и наклоны
Общим недостатком для прорывных идей является ее закрытость, т.е. если новые модели изобретены сейчас, то они станут доступны широкой общественности только через условные 10-20 лет. Как с 3D принтерами, которые долгое время были под патентами и крайне дорогими.
Со времени написания первой статьи прошло 3.5 года, а воз и ныне там. Моя позиция проще: не пытаться заменить мозг технологией, а дополнить его и усилить при помощи технологии. По этой причине, хотелось бы узнать, на каких принципах конструировать новые архитектуры? Этого я пока не нашел нигде. Все только и делают, что конструируют на основе каких-то своих догадок и инсайтов. Если для этого придется отказаться от «нейрона бабушки», то откажусь без колебаний: мы же не секта какая-то :-)
При просмотре двенадцати статей «Логики сознания» пришла идея, что необходимо оперировать не только весами синапсов, но и их положением и, возможно, даже количеством синапсов в свертке. Так в классической конволюционной сети оперируют девятью синапсами в свертке, расположенными в виде квадрата 3×3. Затем появилась операция выбрасывания части синапсов при обучении (dropout). Затем перешли к пространственной свертке (dilated convolution). Вполне возможно, что все это движется в сторону оперирования положением и количеством синапсов в свертке.
Итак, добавляем пространственную организацию синапсов при свертке (сворачиваем не только квадратиком, но и более сложными двумерными фигурами). Пока не понятно, как добавить «динамическую перестройку контекстных карт». Каким образом синапсы будут перемещаться по предыдущему слою? Каким образом будет выбираться их количество?
Во второй статье узнал, что, вообще, можно отказаться от сверток, а использовать другие математические операции. Но какие, пока не понял.
не пытаться заменить мозг технологией, а дополнить его и усилить при помощи технологии
Моя еще проще — избавится от рутинных операций. Например:
— распознавание автомобильных номеров, чтобы их данные ввести в некую базу данных; аналогично для бейджиков или бирок;
— пройтись с видеокамерой по торговому ряду и из видео потом извлечь данные по всем ценам вместе с изображением товара
— сделать десяток фотографий и получить полноценную 3D модель вообще без редактирования
— сделаны фото страниц на телефон, выровнять ориентацию страниц и распознать текст с них
— распознование неких стандартных бланков
и т.д.
Для перечисленных задач не требуется вся мощность мозга. Особенно, когда приходит новый тип идентификатора и чтобы не обучать заново нейросеть на распознавание этого типа в течении нескольких часов, а достаточно одной фото идентификатора, т.е. условного бейджика нового образца или даже разметить вручную где какие области находятся, а дальше ИИ сам извлекает данные.
Сейчас обученный ИИ не готов к серьезному изменению распознаваемого образа для обычного пользователя. Если есть готовый ИИ, который распознает собачек, то если пользователь распознавание кошечек, то не достаточно одной фотографии, нужны:
— специалист по ИИ-обучению
— целый датасет с кошечками
— мощный ПК с хорошими видеокартами для обучения нейросети
и т.д.
Соответственно, ИИ не готов для практического использования для новых задач для обычных пользователей. Мне уже сообщали, что можно скачать и самому настроить, но это не совсем верно, т.к. нужно еще и научится самому настраивать. Т.е. граничные условия в виде условного неопытного пользователя, который ничего не знает в ИТ, данный метод провалит из-за сложности.
Вывод: нейросети далеки от Plug&play для аналогичных задач, но уже могут использоваться в таком режиме для конкретных узких задач со множеством ограничений, дабы избежать промахи ИИ.
На примере Excel — это как можно редактировать таблицы 4х5 с обязательным заголовком, но нельзя редактировать таблицы 5х6 или даже 4х5 без заголовка.
Казалось бы, именно здесь зарыта золотая жила.
Прогнал все эти линии на руке и выдал ответ когда клиенту полярный писец придёт.
Материала для тренировки сети накоплено тонны за последние пару тысяч лет.

www.gazeta.ru/science/news/2019/11/11/n_13684502.shtml
Это только первый шаг
и пр. предсказатели
В трейдинге, бывает, балуются т.н. "техническим анализом", в том числе и на нейронных сетях.
Можете "на пальцах" пояснить эту фразу:
Есть разница между задачами по классификации изображений, обнаружению объектов на изображении и сегментацией изображений
Как именно обнаруживаются/классифицируются объекты без сегментации? В старых (донейросетевых) книгах достаточно чёткая последовательность сегментация-обнаружение-классификация.
- Классификация (image classification) — это когда картинка классифицируется целиком. Если на картинке несколько разных объектов, то ситуация неопределенная. Алгоритм либо определит правильно один из объектов, либо выдаст совершенно произвольный результат.
- Обнаружение объектов на картинке (object detection) — алгоритм обнаруживает объект на картинке и обводит его прямоугольником. Несколько разных объектов на картинке обведутся разными видами прямоугольников. В общем случае, алгоритм может определить, сколько объектов на изображении, где на изображении они находятся (не обязательно) и каких они классов (классифицировать каждый обнаруженный объект на одной картинке).
- Сегментация изображений (вернее сегментация объектов на изображении, image segmentation) — вместо прямоугольников вокруг объектов на изображении алгоритм определяет объект с точностью до пикселя (сегментирует, отделяет от остального изображения). В общем случае, алгоритм с точностью до пикселя может сказать, где находится объект. Если объектов несколько, то хороший алгоритм сегментирует все из них.
Т.е. в object detection считаются локальные черты (features) в определенном окне, а потом смотрят доминирование определенных черт в локальной окрестности и её уже обводят прямоугольником?
Нейросети. Куда это все движется