1. В оригинальном исследовании показано совсем не то, что люди думают.
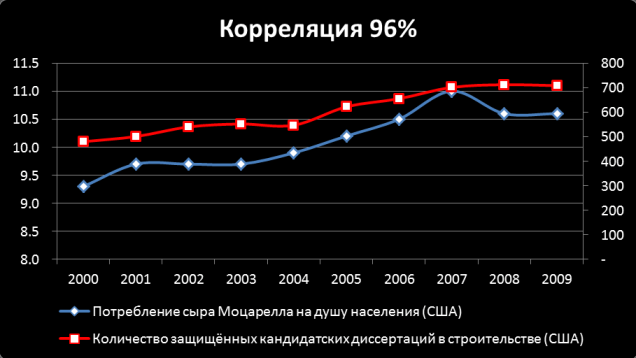
2. Оригинальное исследование так криво сделано статистически, что просто не удовлетворяет критерию фальсифицируемости. Простыми словами - генератор случайных чисел демонстрирует такой же результат.
3. Единственное, что этот эффект демонстрирует - это любовь людей к красивым историям (а математику никто не любит … и вообще есть ложь, большая ложь и статистика).
Давным-давно, один специалист по базам данных (из тех, бородатых и уже седых) сказал мне, что метки времени (timestamp) — это самая сложная тема в базах данных. Я ему, правда, не поверил, но приколы со временем реально встречаются.
Есть стандартная проблема, которую часто вижу в чужих данных. Положим собрались вы отслеживать события/действия пользователя. Обычно у вас будет это делать некий код (JS в вебе или SDK для аппов), который будет слать данные серверу.
Каждому событию нужна метка времени. И есть выбор из двух: локальное время на клиенте или время получения события сервером. Один хороший совет что делать и загадка без ответа под катом
В этой статье хочу поделиться способом, который позволил нам прекратить хаос с процессингом данных. Раньше я считал этот хаос и последующий ре-процессинг неизбежным, а теперь мы забыли что это такое. Привожу пример реализации на BiqQuery, но трюк довольно универсальный.
У нас вполне стандартный процесс работы с данными. Исходные данные в максимально сыром виде регулярно подгружаются в единое хранилище, в нашем случае в BigQuery. Из одних источников (наш собственный продакшн) данные приходят каждый час, из других (обычно сторонние источники) данные идут ежедневно.
В последствии данные обрабатываются до состояния пригодного к употреблению разнообразными пользователями. Это могут быть внутренние дашборды; отчёты партнёрам; результаты, которые идут в продакшн и влияют на поведение продукта. Эти операции могут быть довольно сложными и включать несколько источников данных. Но по большей части мы с этим справляется внутри BigQuery с помощью SQL+UDF. Результаты сохраняются в отдельные таблицы там же.
Недавно заметил в ленте фейсбука ссылку на статью с кучей примеров «странных корреляций» как на картинке. Первоисточник оказывается здесь, и там таких примеров штук 20. Решил по-практиковаться в статистике и проверить насколько эти корреляции удивительны на самом деле.
Здравствуй Хабр! Хочу рассказать как мы делали свою собственную Big Data.
Каждый стартап хочет собрать что-то дешевое, качественное и гибкое. Обычно так не бывает, но у нас, похоже, получилось! Ниже идёт описание нашего решения и много моего сугубо субъективного мнения по этому поводу.
И да, секрет в том, что используется 6 сервисов гугла и собственного кода почти не писалось.
Прочтение последних постов про Bitcoin меня очень разочаровало. Рассуждения о полной необеспеченности зелёных фантиков (долларов) и о нематериальности золота показывают, что хабровчанам не хватает знаний по теории денег, чтобы во всём этом разобраться.
А посему сегодня мы будем анализировать Bitcoin с точки зрения Количественной Теории Денег, которая является на сегодня базовой в экономической науке.