Big O
Easy
5 min
Tutorial
Translation
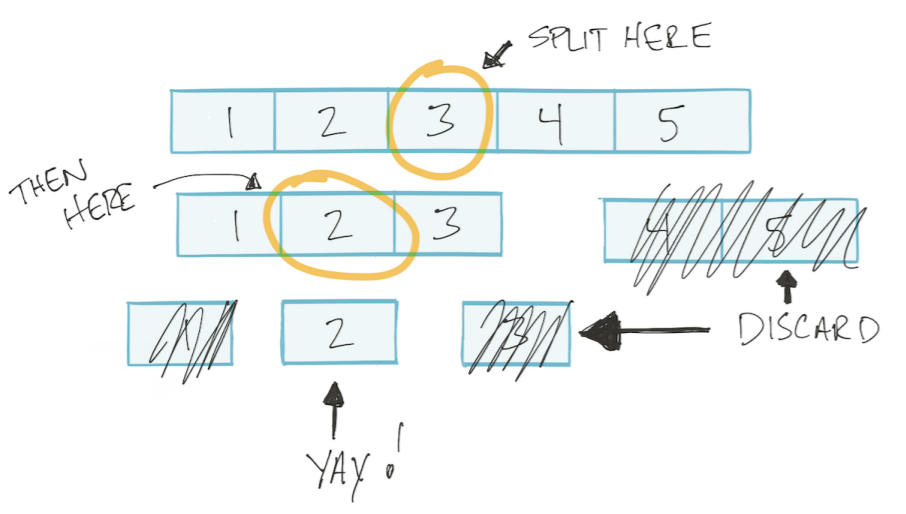
Примечание. Сокращенный перевод, скорее пересказ своими словами.
UPD: как отметили в комментариях, примеры не идеальны. Автор не ищет лучшее решение задачи, его цель объяснить сложность алгоритмов «на пальцах».
Big O нотация нужна для описания сложности алгоритмов. Для этого используется понятие времени. Тема для многих пугающая, программисты избегающие разговоров о «времени порядка N» обычное дело.
Если вы способны оценить код в терминах Big O, скорее всего вас считают «умным парнем». И скорее всего вы пройдете ваше следующее собеседование. Вас не остановит вопрос можно ли уменьшить сложность какого-нибудь куска кода до n log n против n^2.
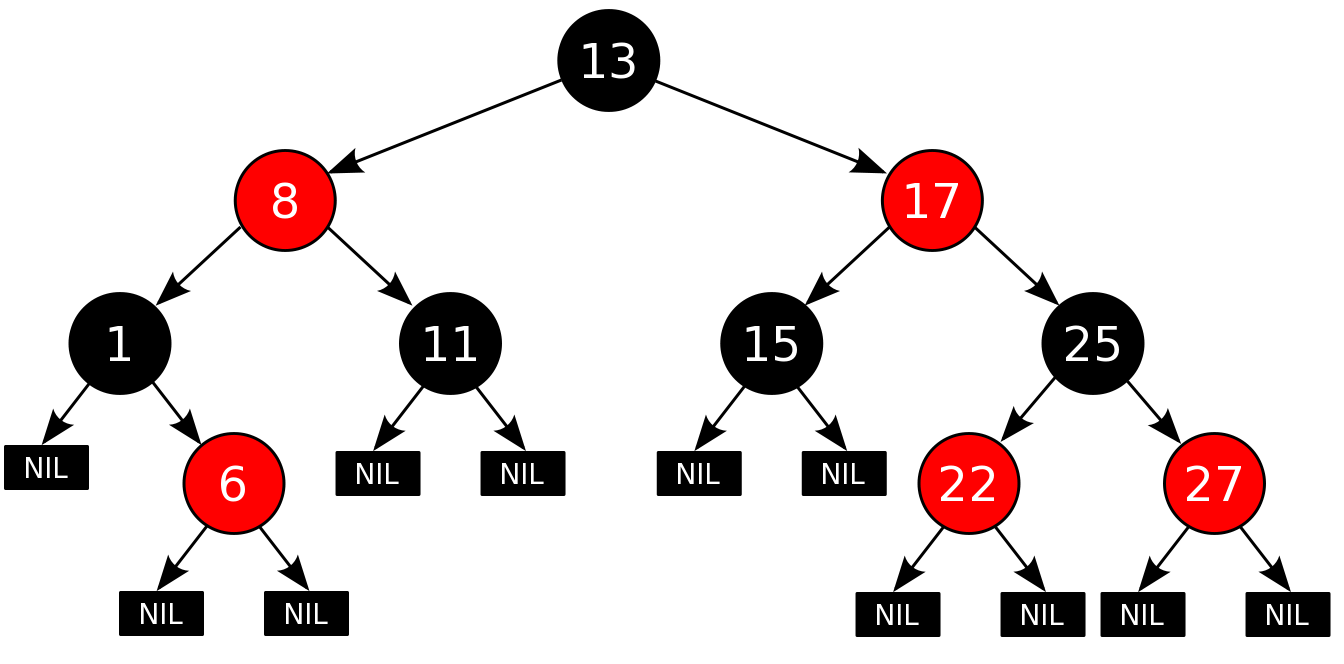
Структуры данных
Выбор структуры данных зависит от конкретной задачи: от вида данных и алгоритма их обработки. Разнообразные структуры данных (в .NET или Java или Elixir) создавались под определенные типы алгоритмов.
Часто, выбирая ту или иную структуру, мы просто копируем общепринятое решение. В большинстве случаев этого достаточно. Но на самом деле, не разобравшись в сложности алгоритмов, мы не можем сделать осознанный выбор. К теме структур данных можно переходить только после сложности алгоритмов.
Здесь мы будем использовать только массивы чисел (прямо как на собеседовании). Примеры на JavaScript.