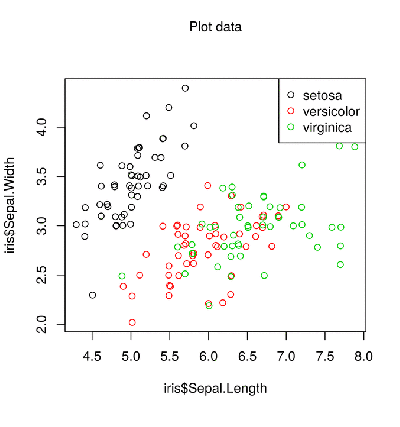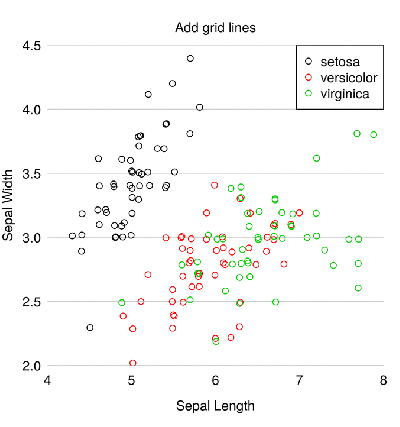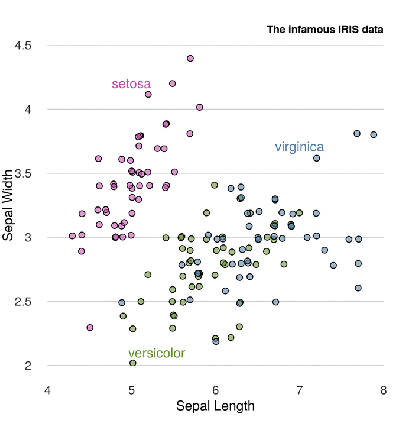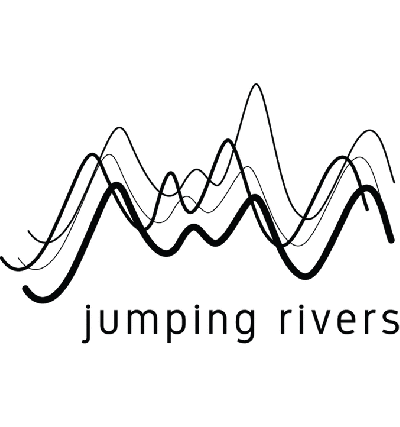
Статистика в последнее время получила мощную PR поддержку со стороны более новых и шумных дисциплин — Машинного Обучения и Больших Данных. Тем, кто стремится оседлать эту волну необходимо подружится с уравнениями регрессии. Желательно при этом не только усвоить 2-3 приемчика и сдать экзамен, а уметь решать проблемы из повседневной жизни: найти зависимость между переменными, а в идеале — уметь отличить сигнал от шума.
Для этой цели мы будем использовать язык программирования и среду разработки R, который как нельзя лучше приспособлен к таким задачам. Заодно, проверим от чего зависят рейтинг Хабрапоста на статистике собственных статей.


 Все, что я здесь пишу — это мой личный опыт и наблюдения. За то время, что я искал работу, столкнулся с тем, что в интернете очень много, мягко говоря, противоречивой информации по данной теме. Все люди очень разные, ситуации у всех очень разные — то, что сработало со мной, не сработает с вами, и наоборот. Поэтому мой текст нужно воспринимать не как инструкцию, а как просто одну из историй о том, как можно найти работу в Сан Франциско.
Все, что я здесь пишу — это мой личный опыт и наблюдения. За то время, что я искал работу, столкнулся с тем, что в интернете очень много, мягко говоря, противоречивой информации по данной теме. Все люди очень разные, ситуации у всех очень разные — то, что сработало со мной, не сработает с вами, и наоборот. Поэтому мой текст нужно воспринимать не как инструкцию, а как просто одну из историй о том, как можно найти работу в Сан Франциско.