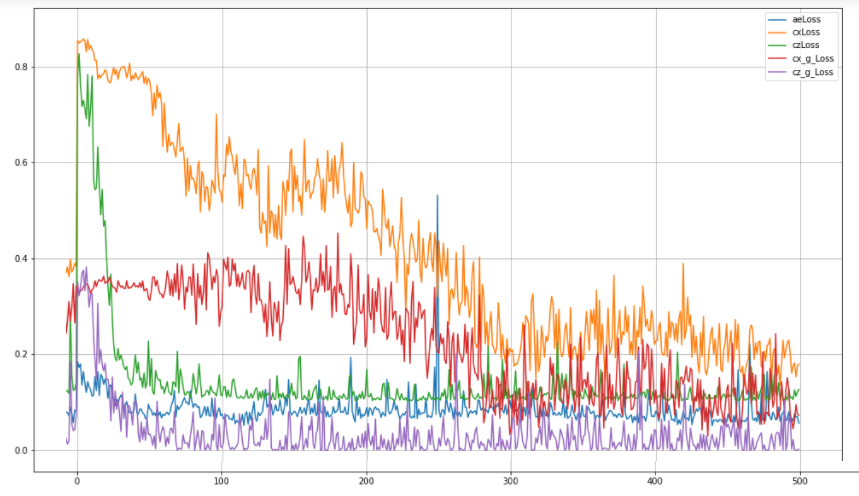
В текущей пандемии COVID-19 появилось много проблем, на которые хакеры с удовольствием набрасывались. От лицевых щитков, распечатанных на 3D-принтере и медицинских масок домашнего изготовления до замены полноценного механического аппарата искусственной вентиляции лёгких – этот поток идей вдохновлял и радовал душу. В то же самое время были попытки продвинуться и в другой области: в исследованиях, нацеленных на борьбу непосредственно с самим вирусом.
Судя по всему, наибольший потенциал для остановки текущей пандемии и опережения всех последующих есть у подхода, пытающегося докопаться до самого истока проблемы. Этот подход из разряда «узнай своего врага» исповедует вычислительный проект Folding@Home. Миллионы людей зарегистрировались в проекте и жертвуют часть вычислительных мощностей своих процессоров и GPU, создав таким образом крупнейший [распределённый] суперкомпьютер в истории.
Но для чего конкретно используются все эти экзафлопы? Почему нужно бросать такие вычислительные мощности на фолдинг [укладку] белков? Какая тут работает биохимия, зачем вообще белкам нужно укладываться? Вот краткий обзор фолдинга белков: что это, как он происходит и в чём его важность.