
Введение
Данная статья является продолжением серии статей описывающей алгоритмы лежащие в основе
Synet — фреймворка для запуска предварительно обученных нейронных сетей на CPU.
В предыдущей статье я описал методы, основанные на матричном умножении. Эти методы с минимальными усилиями позволяют достичь во многих случаях более 80% от теоретического максимума. Казалось бы, ну куда тут можно еще дальше улучшать? Оказывается можно! Существуют математически методы, которые позволяют сократить число операций, необходимых для свертки. С одним из таких методов — алгоритму свертки по методу Винограда мы и ознакомимся в настоящей статье.

Шмуэль Виноград (Shmuel Winograd) 1936.01.04 — 2019.03.25 — выдающийся израильский и американский ученый в области компьютерных наук, создатель алгоритмов быстрого матричного умножения, свертки и преобразования Фурье.
 Перед вами – перевод свободной онлайн-книги Майкла Нильсена «Neural Networks and Deep Learning», распространяемой под лицензией
Перед вами – перевод свободной онлайн-книги Майкла Нильсена «Neural Networks and Deep Learning», распространяемой под лицензией 
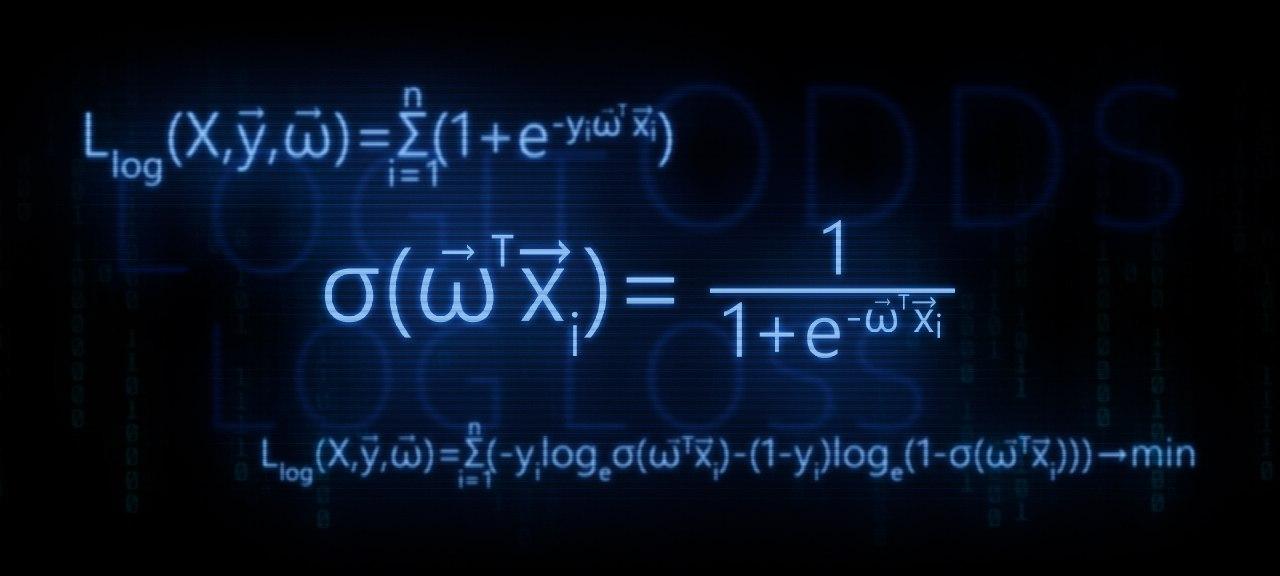









{kind=link}