Comments 42
Статью в ворде готовили?
Некоторые символы отображаются квадратиками


SVD — аббревиатура от Singular Value Decomposition, a не Single Value Decomposition. Поправьте, пожалуйста.
Победителю был обещан приз в $ 1 000 000. Соревнование длилось примерно три года. За первый год качество улучшили на 7%, дальше все немного замедлилось. Но в конце две команды с разницей в 20 минут прислали свои решения, каждое из которых проходило порог в 10%, качество у них было одинаковое с точностью до четвертого знака.Какова вероятность, что два года две команды готовили практически два одинаковых решения и выложили его с интервалом в два десятка минут??? Кто помог одной команде срерайтить код другой команды? Чьи команды были???
почайте историю этого соревнования. комманды не ждали два года а потом раааз и выложили, они выкладывали свои алгоритмы регулярно в течении 2х лет, каждый раз улучшая их. В последние дни комманды работали в режиме 24 часа в сутки. Разница в 20 минут, это разница между их последними «коммитами».
Нужно понимать, что обе команды приблизились к условной «асимптоте» качества рекомендаций. Так что нет ничего удивительного в том, качество у них так сильно совпадало, даже если использовались разные алгоритмы.
Вопрос — как конкретно вычисляется норма в функционале J? Дело в том, что модульная функция не дифференцируема в точке экстремума, а, следовательно, применять градиентный метод для неё нельзя. Выход из ситуации — использовать численные методы нулевого порядка. Это как раз то, что описано в пункте «Alternating Least Squares». В нашей литературе этот метод называется методом покоординатного спуска. Но даже если функция дифференцируема, применять градиентный метод нужно с осторожностью, ведь для сходимости градиентного метода нужно, чтобы градиент целевой функции удовлетворял условию Липшица (см., например, книгу Бориса Теодоровича Поляка «Введение в оптимизацию», стр. 31).
В случае выпуклой целевой функции экстремум единственен и оба метода (при выполнении условий сходимости) будут сходиться к нему, локальных экстремумов нет.
Опять же обычно методы первого порядка сходятся к экстремуму быстрее, чем методы нулевого порядка. В Вашем случае Вы почему-то отказываетесь от этого (если не выполняются условия сходимости, то отказ обоснован).
Или трудно вычислить частные производные — повод отказаться от градиентного метода.
Вообще, в подобных задачах обычно полноценный градиентный спуск слишком (вычислительно) сложен, ибо размер обучающего множества может быть очень велик, вычислять такое на каждой итерации дорого. На практике используется только стохастический градиентный спуск, у которого из-за стохастичности имеются шумы, так что сходится он ещё дольше, а на шаг нужно налагать условия Роббинса-Монро.
Все хорошо в рекомендациях, но, вот, для примера:
Зашел я на Яндекс-Музыку. Слушаю то, что мне близко, но тут увидел обложку альбома незнакомого исполнителя. Обложка понравилась, имя певца прозвучано нормально — я щелкнул по альбому. Послушал, и решил, что «нет, я такое не хочу».
Но с тех пор песни этого певца и этого жанра и этого издательства будут регулярно рекомендоваться мне системой. Щелкну еще раз по симпатичной обложке — система решит, что мне такого надо побольше показывать.
И кто кому что навязывает и что первично — моя любовь к какому-то типу музыки, или неверное, в общем, предположение системы, что мне нравится нечто вовсе другое? Причем предположение это подтолкнуто самой же системой.
Как вариант, могу предложить ситуацию: если у рок-группы есть одна-две милых гитарных романтичных баллад (отличающихся от их обычного стиля), и я их прослушаю в рамках сборника «романтические мелодии к дню Валентина», то меня, как, в рокеры запишут, в романтики, в любителей сборников — и что я в сумме буду получать в рекомендациях?
Как вывод — ОЧЕНЬ хочется иметь кнопку «я НЕ люблю этого, не советовать мне», и «я уже купил этот тип товара, хватит доставать!» А то стоит день поискать в каталоге холодильник, как тебе его Контекст будет сватать еще два месяца :(
Зашел я на Яндекс-Музыку. Слушаю то, что мне близко, но тут увидел обложку альбома незнакомого исполнителя. Обложка понравилась, имя певца прозвучано нормально — я щелкнул по альбому. Послушал, и решил, что «нет, я такое не хочу».
Но с тех пор песни этого певца и этого жанра и этого издательства будут регулярно рекомендоваться мне системой. Щелкну еще раз по симпатичной обложке — система решит, что мне такого надо побольше показывать.
И кто кому что навязывает и что первично — моя любовь к какому-то типу музыки, или неверное, в общем, предположение системы, что мне нравится нечто вовсе другое? Причем предположение это подтолкнуто самой же системой.
Как вариант, могу предложить ситуацию: если у рок-группы есть одна-две милых гитарных романтичных баллад (отличающихся от их обычного стиля), и я их прослушаю в рамках сборника «романтические мелодии к дню Валентина», то меня, как, в рокеры запишут, в романтики, в любителей сборников — и что я в сумме буду получать в рекомендациях?
Как вывод — ОЧЕНЬ хочется иметь кнопку «я НЕ люблю этого, не советовать мне», и «я уже купил этот тип товара, хватит доставать!» А то стоит день поискать в каталоге холодильник, как тебе его Контекст будет сватать еще два месяца :(
Ни разу ещё ни одна система рекомендаций не показала мне чего либо стоящего.
Потому что ее разума хватает на логику контекстной рекламы — «купили холодильник — вот вам инфа про холодильник», т.е. работаем по тому, что вроде знаем, но не учитываем текущего состояния юзера.
Рекомендации же не по простым метрикам («ищу высокий шкаф, и пусть мне предложат другие высокие шкафы») — вообще суть пальцем в небо. Как, скажем, мне создать метрику типа «вот эти песни других групп звучат примерно так же мелодично и спокойно, как и просматриваемый вами альбом-микс разных групп»? Тем более, если метрики выставляют люди, склонные, как известно, ошибаться, уставать, думать, что им мало платят и т.д.
Главное, что отладка системы рекомендации — штука странная: юзер даже на лажовую рекомендовалку может пару раз щелкнуть мышкой, чтобы просто посмеяться, а разработчики рекомендовалки будут радоваться и пищать «смотри-ка, нашей системой пользуются!»
Один выход — следить за каждым, вести на него постоянное досье, и из этого уже…
Рекомендации же не по простым метрикам («ищу высокий шкаф, и пусть мне предложат другие высокие шкафы») — вообще суть пальцем в небо. Как, скажем, мне создать метрику типа «вот эти песни других групп звучат примерно так же мелодично и спокойно, как и просматриваемый вами альбом-микс разных групп»? Тем более, если метрики выставляют люди, склонные, как известно, ошибаться, уставать, думать, что им мало платят и т.д.
Главное, что отладка системы рекомендации — штука странная: юзер даже на лажовую рекомендовалку может пару раз щелкнуть мышкой, чтобы просто посмеяться, а разработчики рекомендовалки будут радоваться и пищать «смотри-ка, нашей системой пользуются!»
Один выход — следить за каждым, вести на него постоянное досье, и из этого уже…
Кстати, вот она, авторекомендация во всей красе:
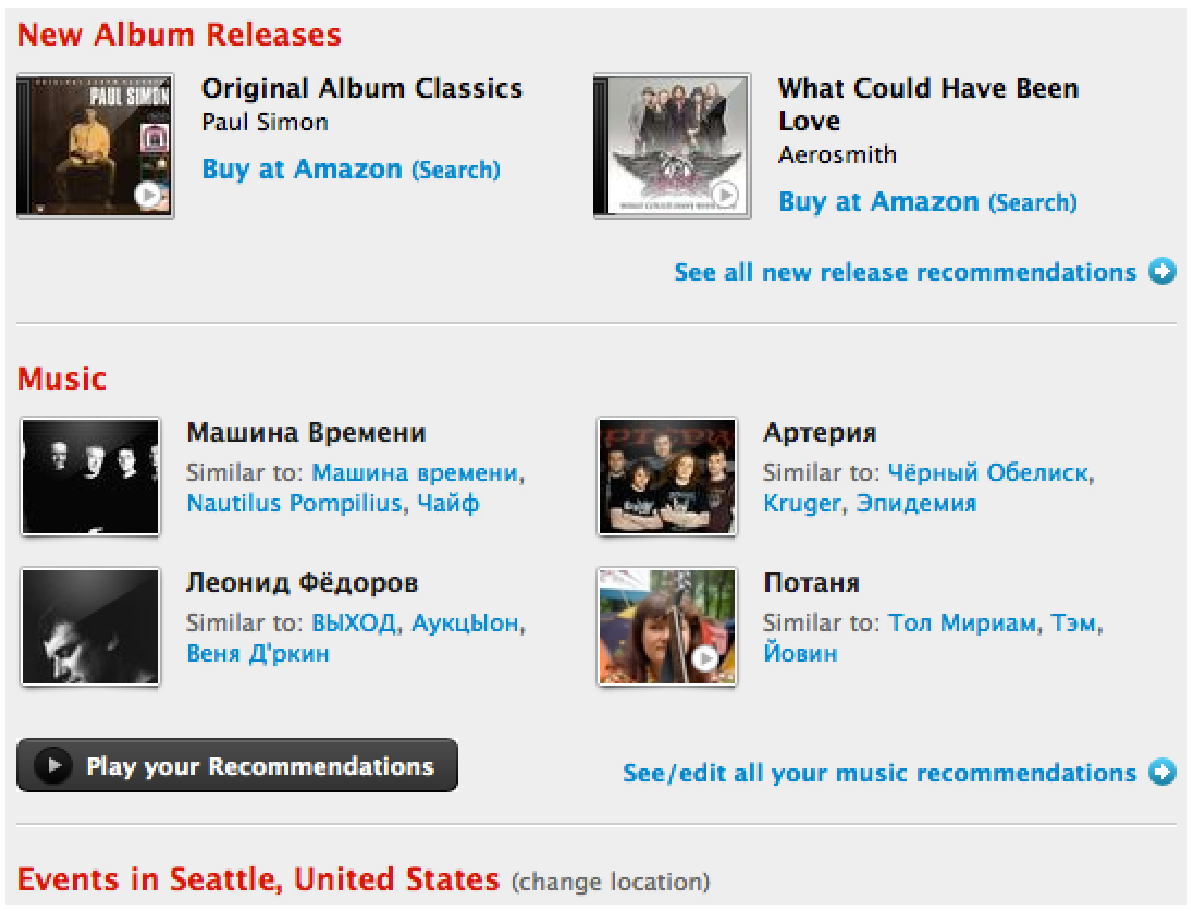
«Машина времени» и «Машина Времени» — рекомендации друг к другу. Отличный пример, когда за математикой и механической работой алгоритма теряется суть идеи советовать похожее.
Не говоря уже, что во фразе
имеется в самой формулировка косяк: ну купил я, скажем, у них плеер для бега, так мне и правда будут похожие плееры долго и упорно показывать. Не знаю, как кого, а лично меня это раздражает.
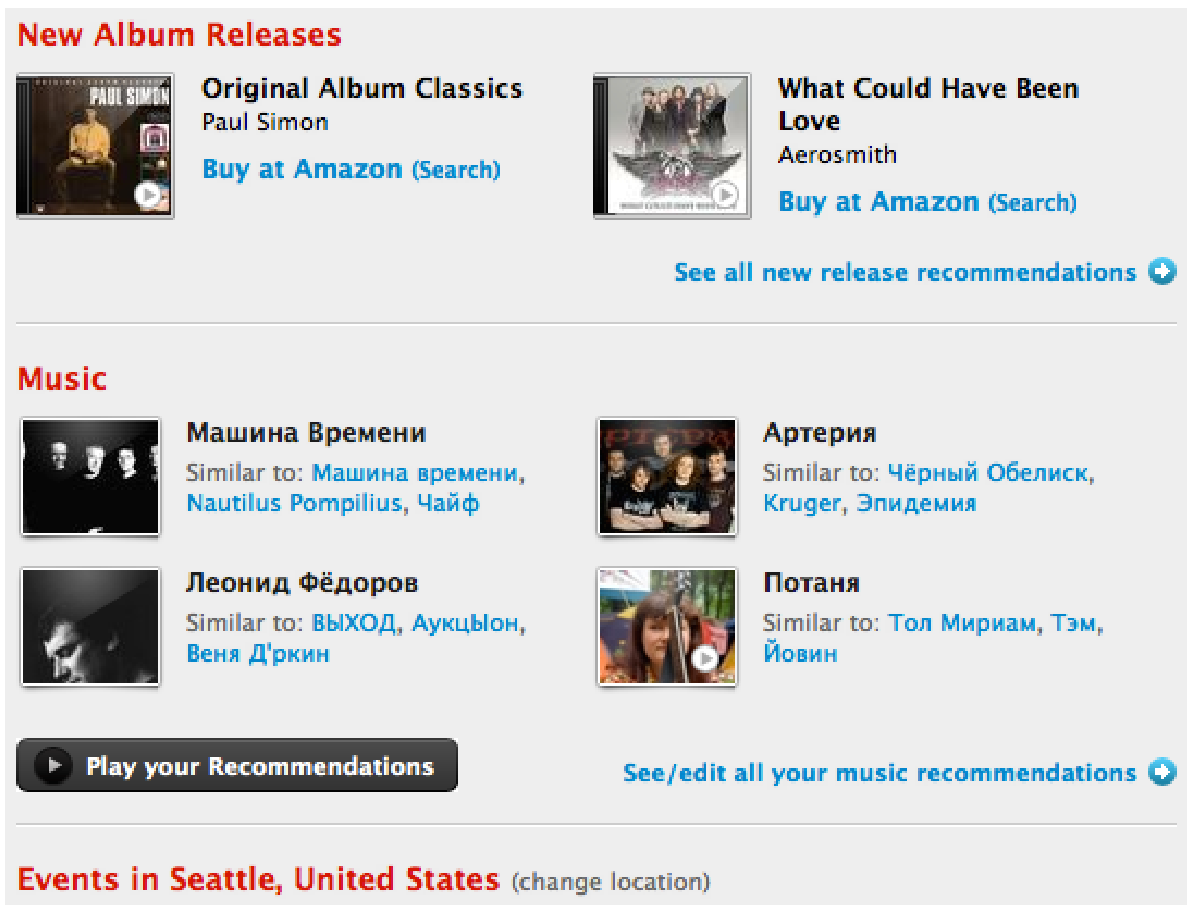
«Машина времени» и «Машина Времени» — рекомендации друг к другу. Отличный пример, когда за математикой и механической работой алгоритма теряется суть идеи советовать похожее.
Не говоря уже, что во фразе
Если вы купили что-то на амазоне, за вами будут охотиться с дополнительными предложениями: похожими товарами или аксессуарами
имеется в самой формулировка косяк: ну купил я, скажем, у них плеер для бега, так мне и правда будут похожие плееры долго и упорно показывать. Не знаю, как кого, а лично меня это раздражает.
«Машина времени» и «Машина Времени» — проблема нормализации данных, а не рекомендательного алгоритма. Алгоритм ожидает получить данные на вход в таком виде, что все исполнители различны. Поскольку что «Машина времени», что «Машина Времени» для него всего-лишь 2 набора байт, а распознавать естественный язык для машин пока непросто, приходится придумывать какие-то правила, приводящие данные к некой стандартной форме.
В общем, это обычный баг, по какой-то причине Last.FM не смог / не захотел использовать уже существующего исполнителя, что ввело рекомендательный алгоритм в замешательство. Общему подходу от этого ни жарко, ни холодно — с таким же успехом можно было где-нибудь в алгоритме заменить умножение на сложение, только баг был бы виден лучше.
Не стоит ожидать от математических алгоритмов совершенства, они всегда основаны на некоторых предположениях (далеко не всегда адекватных реальному миру).
В общем, это обычный баг, по какой-то причине Last.FM не смог / не захотел использовать уже существующего исполнителя, что ввело рекомендательный алгоритм в замешательство. Общему подходу от этого ни жарко, ни холодно — с таким же успехом можно было где-нибудь в алгоритме заменить умножение на сложение, только баг был бы виден лучше.
Не стоит ожидать от математических алгоритмов совершенства, они всегда основаны на некоторых предположениях (далеко не всегда адекватных реальному миру).
Все бы хорошо, этот лозунг «сначала нормализуем, зато потом оно полетит» все как-то часто не выдерживает столкновения с реальностью.
С теми же песнями: берем Синатру, берем его My Way, загоняем в базу — красотааа! А теперь берем все его пластинки, и, ба, на каждой пятой эта песня есть. Это одна и та же песня (та же запись), или чем-то отличаются? Наверное, отличаются, хотя бы часть из них. Но названия одни и те же. Как нам их хранить, в виде одного файла (какой тогда вариант берем), или в каждом «альбоме» храним отдельную копию и зовем ее «my way — версия из альбома такого-то»?
Дальше — больше. На каких-нибудь «Зайцев-нет» имеем для каждого исполнителя единицы, а то и десятки дублей песен, вида «синатра — мой путь», «синатра — my way» и даже «синатра — супер песня!»
Я к тому, что нормализовать жизнь — это не только задача сравнения названий. Нет одинаковых листьев на одном дереве (по сути — объекты «лист» (почти) всегда уникальны), и нет одинаковых песен (объекты «песня такая-то» тоже (почти) уникальны). На эту тему рекомендовалка должна скуксится, только если ей не загрубить порог восприятия — «человек слушает Синатру — рекомендуем вам также послушать Круга и группу Лесоповал» (потому что у кого-то Синатра и Круг оказались в одном треклисте).
С теми же песнями: берем Синатру, берем его My Way, загоняем в базу — красотааа! А теперь берем все его пластинки, и, ба, на каждой пятой эта песня есть. Это одна и та же песня (та же запись), или чем-то отличаются? Наверное, отличаются, хотя бы часть из них. Но названия одни и те же. Как нам их хранить, в виде одного файла (какой тогда вариант берем), или в каждом «альбоме» храним отдельную копию и зовем ее «my way — версия из альбома такого-то»?
Дальше — больше. На каких-нибудь «Зайцев-нет» имеем для каждого исполнителя единицы, а то и десятки дублей песен, вида «синатра — мой путь», «синатра — my way» и даже «синатра — супер песня!»
Я к тому, что нормализовать жизнь — это не только задача сравнения названий. Нет одинаковых листьев на одном дереве (по сути — объекты «лист» (почти) всегда уникальны), и нет одинаковых песен (объекты «песня такая-то» тоже (почти) уникальны). На эту тему рекомендовалка должна скуксится, только если ей не загрубить порог восприятия — «человек слушает Синатру — рекомендуем вам также послушать Круга и группу Лесоповал» (потому что у кого-то Синатра и Круг оказались в одном треклисте).
Во-первых, я не говорил, что для нормализации достаточно названия сверить. Посыл мой был в том, что нормализация есть отдельная задача, ортогональная рекомендации.
Можно, например, анализировать аудиопток, отсеивая таким образом дубликаты. Или как-то иначе, суть от этого не изменится: это отдельная задача со своими методами.
К чему здесь Зайцы — непонятно. Надо было бы им строить рекомендации или делать другую аналитику — привели бы свою свалку в порядок. Тут, вроде, не plug-and-play решение предлагается.
Касательно Вашего примера:
Я считаю, что задачей рекомендательных систем является преподнесение чего-то нового, о чём пользователь раньше не знал. Другой вариант трека, конечно, может быть интересен, но в меньшей степени, чем совершенно новый неизвестный ранее трек (возможно, нового исполнителя, у которого есть ещё много «вкусного»).
Опять же, если человек знает исполнителя, что мешает ему пойти и послушать всю его дискографию? На мой взгляд, в рекомендации уже известного исполнителя смысла мало (тут я лукавлю, и это зависит от того, как мы собираемся использовать систему. В случае радио, например, мы хотим составлять плейлист автоматически, не требуя от пользователя даже присутствия. Но в таком случае нет никакой разницы, поставим мы Машину времени или Машину Времени).
Ну а вообще, в случае несколькиз различных треков можно сделать по-разному:
1. Если мы уверены в качестве контента, а различия невелики, то можно все дубли считать за один трек, а проигрывать случайный.
2. Если различия велики (акустическая версия, например), то есть смысл создать отдельную запись под такой трек, отразив это в названии.
Более того, можно усложнить модель, введя таксономию на разных версия одной песни, так что рекомендовать мы их всё-таки будем, но с меньшим «весом».
Можно, например, анализировать аудиопток, отсеивая таким образом дубликаты. Или как-то иначе, суть от этого не изменится: это отдельная задача со своими методами.
К чему здесь Зайцы — непонятно. Надо было бы им строить рекомендации или делать другую аналитику — привели бы свою свалку в порядок. Тут, вроде, не plug-and-play решение предлагается.
Касательно Вашего примера:
Я считаю, что задачей рекомендательных систем является преподнесение чего-то нового, о чём пользователь раньше не знал. Другой вариант трека, конечно, может быть интересен, но в меньшей степени, чем совершенно новый неизвестный ранее трек (возможно, нового исполнителя, у которого есть ещё много «вкусного»).
Опять же, если человек знает исполнителя, что мешает ему пойти и послушать всю его дискографию? На мой взгляд, в рекомендации уже известного исполнителя смысла мало (тут я лукавлю, и это зависит от того, как мы собираемся использовать систему. В случае радио, например, мы хотим составлять плейлист автоматически, не требуя от пользователя даже присутствия. Но в таком случае нет никакой разницы, поставим мы Машину времени или Машину Времени).
Ну а вообще, в случае несколькиз различных треков можно сделать по-разному:
1. Если мы уверены в качестве контента, а различия невелики, то можно все дубли считать за один трек, а проигрывать случайный.
2. Если различия велики (акустическая версия, например), то есть смысл создать отдельную запись под такой трек, отразив это в названии.
Более того, можно усложнить модель, введя таксономию на разных версия одной песни, так что рекомендовать мы их всё-таки будем, но с меньшим «весом».
Вы знаете, я про рекомендации думаю именно в ключе «покажи мне новое, такое, чтобы было интересно». Это не всегда легко: скажем, приятель мне может сказать, глядя на мое состояние, на текущую манеру общения, зная о моих проблемах и радостях, что мне, может, стоило бы послушать не Машину, а, скажем, группу противоположного стиля — а машина этого всего не знает (да и вообще не «знает», а механически реагирует, скорее всего)
Может, конечно, глобальная следилка за человеком и сможет так точно предсказать, что у него на душе сейчас творится, но это уже какая-то рекомендовался «а'ля Эшелон» получится )
P.S. Кейс с плейлистом на радио — да, это идея, но такую станцию будет грустно слушать, она сама себя будет накручивать, не находите?
Может, конечно, глобальная следилка за человеком и сможет так точно предсказать, что у него на душе сейчас творится, но это уже какая-то рекомендовался «а'ля Эшелон» получится )
P.S. Кейс с плейлистом на радио — да, это идея, но такую станцию будет грустно слушать, она сама себя будет накручивать, не находите?
Вы гонитесь за точностью во всех случаях, что близко к сильному ИИ. Более того, далеко не каждый Ваш друг, я уверен, сможет так точно порекомендовать что-нибудь (даже зная ваши предпочтения), я уверен.
Эффективность математических моделей и машинного обучения в частности, как мне кажется, связана с тем, что многие вещь в мире хоть и сложны и, кажется, почти случайны, всё же имеют некоторую структуру под собой. Как бы изменичивы Ваши предпочтения ни были, это всё же не белый шум. Опять же, машины учатся хорошо работать в среднем, а не во всех случаях. Если раз в году на полнолуние после дождичка в четверг Вы слушаете Бразильские народные песни, а всё остальное время исключительно классику, то алгоритм вряд ли научится советовать Вам бразильскую музыку по тем самым дням. Хотя бы потому что такой сценарий неотличим от случая, когда к Вам приехали в гости родственники и какая-нибудь 12-летняя племянница захотела послушать Ранеток, которых Вы, в рассматриваемой ситуации, слушать не хотите.
Рассматриваемый Вами случай специфичен тем, что он не располагает никаких фидбеком от Вас в момент рекомендации. Ваш друг тоже ничего Вам не посоветует, если Вы будете сидеть с закрытым ртом и ничего ему про своё текущее состояние не скажете. Если же соответстующий фидбек у системы есть (Вы, например, решили что-то послушать, а машина на той же страничке предложила Вам что-то ещё), то у системы есть шанс на успех ибо
1. Ваши предпочтения не белый шум
2. Вы не единственный пользователь системы
Кого будет накручивать радио я не понял. Я ведь ни слова не сказал о том, какую модель, как и на каких данных мы собрались обучать. Более того, я нигде не говорил про то, что рекомендации должны быть детерминированы.
Эффективность математических моделей и машинного обучения в частности, как мне кажется, связана с тем, что многие вещь в мире хоть и сложны и, кажется, почти случайны, всё же имеют некоторую структуру под собой. Как бы изменичивы Ваши предпочтения ни были, это всё же не белый шум. Опять же, машины учатся хорошо работать в среднем, а не во всех случаях. Если раз в году на полнолуние после дождичка в четверг Вы слушаете Бразильские народные песни, а всё остальное время исключительно классику, то алгоритм вряд ли научится советовать Вам бразильскую музыку по тем самым дням. Хотя бы потому что такой сценарий неотличим от случая, когда к Вам приехали в гости родственники и какая-нибудь 12-летняя племянница захотела послушать Ранеток, которых Вы, в рассматриваемой ситуации, слушать не хотите.
Рассматриваемый Вами случай специфичен тем, что он не располагает никаких фидбеком от Вас в момент рекомендации. Ваш друг тоже ничего Вам не посоветует, если Вы будете сидеть с закрытым ртом и ничего ему про своё текущее состояние не скажете. Если же соответстующий фидбек у системы есть (Вы, например, решили что-то послушать, а машина на той же страничке предложила Вам что-то ещё), то у системы есть шанс на успех ибо
1. Ваши предпочтения не белый шум
2. Вы не единственный пользователь системы
Кого будет накручивать радио я не понял. Я ведь ни слова не сказал о том, какую модель, как и на каких данных мы собрались обучать. Более того, я нигде не говорил про то, что рекомендации должны быть детерминированы.
Так вот я и переживаю (по опыту), что, случись мне слушать классику (которая внутри еще делится на много вариантов) весь год, потом несколько раз слушаю что-то другое, а машина складывает все это и осредняет, давай мне что-то не точное и откровенно левое.
Было бы прекрасно, как в случае со спамом, так иметь фидбек, и иметь возможность стирать, скажем, строчки в истории прослушивании музыки с «моего» аккаунта, которые не отвечают моему общему вкусу.
Второй вопрос, что с утра (скажем) мне хорошо пойдет ритмы нанайского севера, в обед — классика, вечером — бразильское танго. И это по рабочим дням, а по выходным что-то еще. Машина с ума сойдет, и будет всегда неправа, пока не поймет, что нужно привязываться к а) времени суток б) времени года, в) жизни вокруг (обобщая). Если спросить меня, как да что, я скажу в ответ, что лучше я личные треклисты сам набью и себе сохраню для ручного переключения.
Еще есть момент, что, скажем, певец может часть всего своего творчества (а то и просто альбома) петь в одном стиле и с одном настроением, а потом как-то измениться. Т.е. с точностью до исполнителя не насоветуешься. Остается, как я и наблюдаю, «бить по площадям», в надежде, что хоть кому-то рекомендация покажется более-менее нормальной.
Мысль понятна: показал человеку новое, он его будет слушать, а сервис — жить и зарабатывать на этих показах. Но в целом такое поведение напоминает банальный почтовый спам — он тоже бьет по площадям, тоже шифруется в смысле невозможности дать точный фидбек.
А ИИ — это вы правы, от компа ждать чего-то реально стоящего трудно. Тут не просто ИИ нужен, но и упомянутая мною слежка за его поведением.
Хм… Мир вещей мог бы продаванам такую инфу сливать! :)
Было бы прекрасно, как в случае со спамом, так иметь фидбек, и иметь возможность стирать, скажем, строчки в истории прослушивании музыки с «моего» аккаунта, которые не отвечают моему общему вкусу.
Второй вопрос, что с утра (скажем) мне хорошо пойдет ритмы нанайского севера, в обед — классика, вечером — бразильское танго. И это по рабочим дням, а по выходным что-то еще. Машина с ума сойдет, и будет всегда неправа, пока не поймет, что нужно привязываться к а) времени суток б) времени года, в) жизни вокруг (обобщая). Если спросить меня, как да что, я скажу в ответ, что лучше я личные треклисты сам набью и себе сохраню для ручного переключения.
Еще есть момент, что, скажем, певец может часть всего своего творчества (а то и просто альбома) петь в одном стиле и с одном настроением, а потом как-то измениться. Т.е. с точностью до исполнителя не насоветуешься. Остается, как я и наблюдаю, «бить по площадям», в надежде, что хоть кому-то рекомендация покажется более-менее нормальной.
Мысль понятна: показал человеку новое, он его будет слушать, а сервис — жить и зарабатывать на этих показах. Но в целом такое поведение напоминает банальный почтовый спам — он тоже бьет по площадям, тоже шифруется в смысле невозможности дать точный фидбек.
А ИИ — это вы правы, от компа ждать чего-то реально стоящего трудно. Тут не просто ИИ нужен, но и упомянутая мною слежка за его поведением.
Хм… Мир вещей мог бы продаванам такую инфу сливать! :)
С чего Вы решили, что машина просто усредняет? Более того, даже в случае банального усреднения результат был бы больше похож на классику ибо частота её прослушивания больше, чем частота всего остального.
Ничто не мешает на утренних данным запускать один алгоритм, на дневных другой, на вечерних третий, а в промежутках интерполировать. К времени года тоже можно привязаться аналогично. Ну а ситуация вокруг отражается интересами всех пользователей, на которых машина и обучается.
Не обязательно советовать на уровне исполнителей. Можно рекомендовать альбомы, треки, кусочки треков. Описанная в данной статье модель достаточно общая, чтобы работать в любой из этих ситуаций.
Ваша аналогия с почтовым спамом очень странная. Спам приходит сам по себе, а от использования сервиса можно отказаться.
Ничто не мешает на утренних данным запускать один алгоритм, на дневных другой, на вечерних третий, а в промежутках интерполировать. К времени года тоже можно привязаться аналогично. Ну а ситуация вокруг отражается интересами всех пользователей, на которых машина и обучается.
Не обязательно советовать на уровне исполнителей. Можно рекомендовать альбомы, треки, кусочки треков. Описанная в данной статье модель достаточно общая, чтобы работать в любой из этих ситуаций.
Ваша аналогия с почтовым спамом очень странная. Спам приходит сам по себе, а от использования сервиса можно отказаться.
Слежу за вашими вопросами и восхищаюсь — вы уже задали кучу правильных вопросов, которые приводят к целым большим направлениям в исследованиях рекомендательных систем.
Например, ваш вопрос выше насчёт «покажи мне новое» приводит к тому, что иногда нам нужно не просто выдать топ-рекомендации, оптимизируя, грубо говоря, суммарный ожидаемый рейтинг, а оптимизировать ещё и что-нибудь другое. Для этого вводят различные метрики разнообразия (diversity, novelty, serendipity и т.д.) [Vargas, 2011; Castells et al., 2011].
А ваш вопрос насчёт «с утра или вечером» приводит к рекомендательным системам, учитывающим контекст (context-aware recommender systems, CARS) [Adomavicius, Tuzhilin, 2010].
Задавайте больше вопросов. :)
Например, ваш вопрос выше насчёт «покажи мне новое» приводит к тому, что иногда нам нужно не просто выдать топ-рекомендации, оптимизируя, грубо говоря, суммарный ожидаемый рейтинг, а оптимизировать ещё и что-нибудь другое. Для этого вводят различные метрики разнообразия (diversity, novelty, serendipity и т.д.) [Vargas, 2011; Castells et al., 2011].
А ваш вопрос насчёт «с утра или вечером» приводит к рекомендательным системам, учитывающим контекст (context-aware recommender systems, CARS) [Adomavicius, Tuzhilin, 2010].
Задавайте больше вопросов. :)
Мне кажется, статья была быинтересна более широкому кругу читателей, если бы к формулам прилагалась расшифровка обозначений.
Спасибо.
Спасибо.
А какие именно обозначения имеются в виду? Я старался вводить все обозначения, кроме стандартных математических.
На самом деле, вопросы «Что такое рекомендательные системы» и «как соптимизировать некий частный случай некоторой сложной высшей матричной алгеброй» надо бы очень сильно разводить по разным статьям. Иначе не очень съедобно получается.
А что должно быть в статье про рекомендательные системы? «Оптимизация некоего частного случая» является примером конкретного алгоритмы для решения конкретной задачи. Обилие математики обусловлено сложностью задачи.
На мой взгляд статья «Что такое рекомендательные системы» будет исключительно философско-болтологической, а для таких статей теперь существует GeekTimes. Эта же статья вполне подходит тематике Хабра.
Вообще, на хабре уже есть статьи про рекомендательные системы, вводную можно почерпнуть оттуда.
Как писали ТМ в статье о разделении
На мой взгляд статья «Что такое рекомендательные системы» будет исключительно философско-болтологической, а для таких статей теперь существует GeekTimes. Эта же статья вполне подходит тематике Хабра.
Вообще, на хабре уже есть статьи про рекомендательные системы, вводную можно почерпнуть оттуда.
Как писали ТМ в статье о разделении
«Хабрахабр» исключительно [...] профессиональный, хардкорный ресурс, где айтишники делятся опытом друг с другом и улучшают свои профессиональные навыки.
Так не надо тогда начинать с поверхностного обзора. Кратко дать в обзорной врезке у второго абзаца вот эту ссылку, дополнить комментом про то, о чем там наврали или недоговорили, а всю статью целиком посвятить именно своей узкой математике, объявив тему узкоматематичной в первом же абзаце. Это ж статья на профильном ресурсе, тут есть куда сослаться, как вы правильно заметили.
Хотя и на лекции — тоже, смесь обзорки с дебрями частного случая — форменное безобразие. Кому нужен частный случай, обзорка не нужна, и наоборот. Сначала скучают одни, потом недоумевают другие. Нельзя так смешивать аудитории.
Хотя и на лекции — тоже, смесь обзорки с дебрями частного случая — форменное безобразие. Кому нужен частный случай, обзорка не нужна, и наоборот. Сначала скучают одни, потом недоумевают другие. Нельзя так смешивать аудитории.
Жизнь хабра тоже развивается по спирали. :) Когда-то я писал вводный цикл о рекомендательных системах с примерно тем же по сути содержанием.
Впрочем, те посты я бы сейчас тоже по-другому написал. Но, возможно, кому-то из читателей будет интересно.
И совсем уж на правах рекламы — в других статьях того же блога Surfingbird я писал о вероятностных графических моделях, примерно так же «на пальцах»:
- Постановка задачи
- User-based и item-based
- SVD, часть I
- SVD и базовые предикторы
- Оверфиттинг и регуляризация
Впрочем, те посты я бы сейчас тоже по-другому написал. Но, возможно, кому-то из читателей будет интересно.
И совсем уж на правах рекламы — в других статьях того же блога Surfingbird я писал о вероятностных графических моделях, примерно так же «на пальцах»:
Считаю, что неправильно брать среднюю оценку пользователя как некоторую его границу между «хороший» и «плохой» (особенно в случае с фильмами). Дело в том, что в большинстве случаев люди смотрят фильмы, которые им нравятся, потому что перед просмотром можно выбрать фильм, который с большой вероятностью понравится (по чужим оценкам, жанру, описанию и т.д.). Соответственно, средняя оценка находится выше границы хороший-плохой.
Например, человек ставит большинству фильмам оценки от 7 до 9, и двум-трём оценку 2. Для него средняя оценка будет примерно 8, и те фильмы, которым он поставил 7, будут рассматриваться алгоритмом как фильмы, которые ему не понравились (хотя на самом деле они ему понравились).
Например, человек ставит большинству фильмам оценки от 7 до 9, и двум-трём оценку 2. Для него средняя оценка будет примерно 8, и те фильмы, которым он поставил 7, будут рассматриваться алгоритмом как фильмы, которые ему не понравились (хотя на самом деле они ему понравились).
Sign up to leave a comment.
Как работают рекомендательные системы. Лекция в Яндексе