На прошлой неделе BBC рассказала, что для новой версии главной страницы использовала методологию БЭМ, созданную в Яндексе. По такому случаю мы решили поднять материалы мастер-класса «Разрабатываем сайт с нуля на полном стеке БЭМ-технологий» и рассказать вам, как начать использовать полный стек БЭМ-технологий в своих проектах.
БЭМ упрощает разработку сайтов, которые нужно быстро создавать и долго поддерживать. Эту технологию используют во фронтенде почти всех сервисов Яндекса, и она уже успела обрасти множеством библиотек и инструментов, которыми мы хотим с вами поделиться.
В статье мы расскажем, в чём преимущество вёрстки независимыми блоками и что такое уровни переопределения, познакомимся с готовыми библиотеками блоков и инструментами для автоматизации сборки. Покажем, как разные инструменты — например, autoprefixer, css-препроцессор Stylus или модульная система YModules — упрощают жизнь разработчика и создают по-настоящему удобную платформу, если встроить их в процесс разработки по БЭМ.
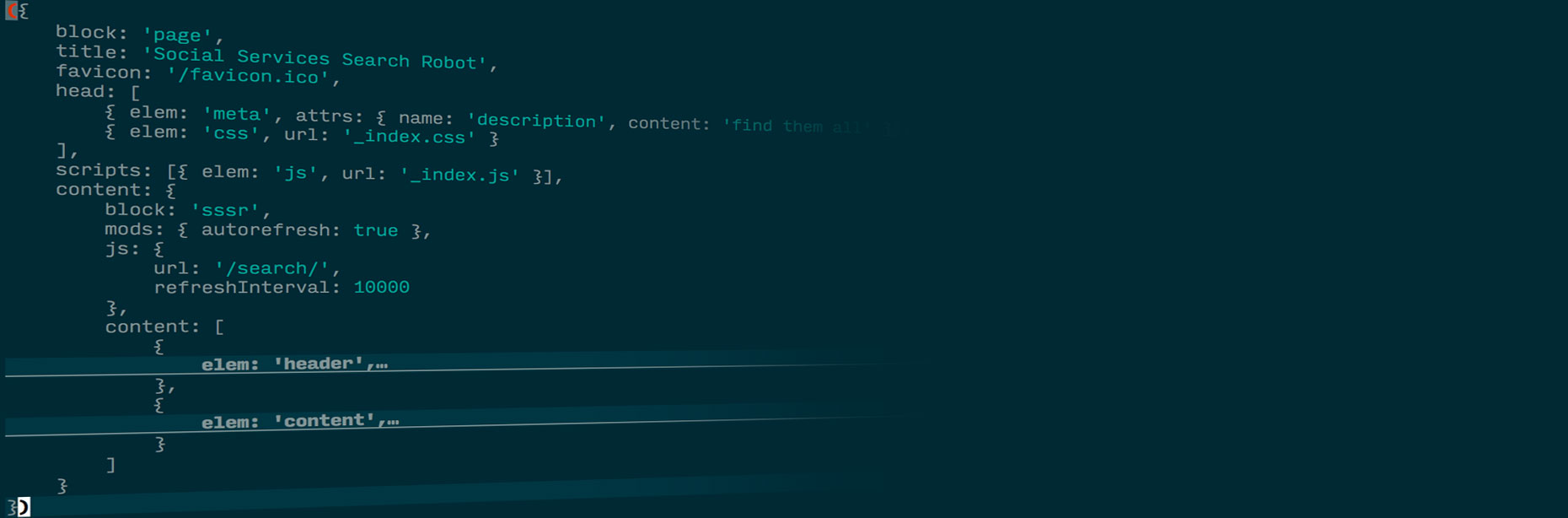
На живом примере мы объясним, в чём польза декларативного подхода, когда одни и те же идеи можно использовать как для CSS, так и для JavaScript. Отдельно остановимся на декларативных шаблонах BEMHTML и BEMTREE, которые позволяют преобразовывать данные в БЭМ-дерево, описанное в формате BEMJSON и, затем в HTML. Рассмотрим в деталях, как написать серверную часть приложения по БЭМ-методологии.
БЭМ упрощает разработку сайтов, которые нужно быстро создавать и долго поддерживать. Эту технологию используют во фронтенде почти всех сервисов Яндекса, и она уже успела обрасти множеством библиотек и инструментов, которыми мы хотим с вами поделиться.
В статье мы расскажем, в чём преимущество вёрстки независимыми блоками и что такое уровни переопределения, познакомимся с готовыми библиотеками блоков и инструментами для автоматизации сборки. Покажем, как разные инструменты — например, autoprefixer, css-препроцессор Stylus или модульная система YModules — упрощают жизнь разработчика и создают по-настоящему удобную платформу, если встроить их в процесс разработки по БЭМ.
На живом примере мы объясним, в чём польза декларативного подхода, когда одни и те же идеи можно использовать как для CSS, так и для JavaScript. Отдельно остановимся на декларативных шаблонах BEMHTML и BEMTREE, которые позволяют преобразовывать данные в БЭМ-дерево, описанное в формате BEMJSON и, затем в HTML. Рассмотрим в деталях, как написать серверную часть приложения по БЭМ-методологии.




 Некоторое время назад решил я освежить знания и почитать что-нибудь о графах. «Ну конечно же, на Хабре должны быть хорошие статьи!» — подумал я, и оказался прав. Статьи есть и их много. Но выглядит они преимущественно вот так:
Некоторое время назад решил я освежить знания и почитать что-нибудь о графах. «Ну конечно же, на Хабре должны быть хорошие статьи!» — подумал я, и оказался прав. Статьи есть и их много. Но выглядит они преимущественно вот так: