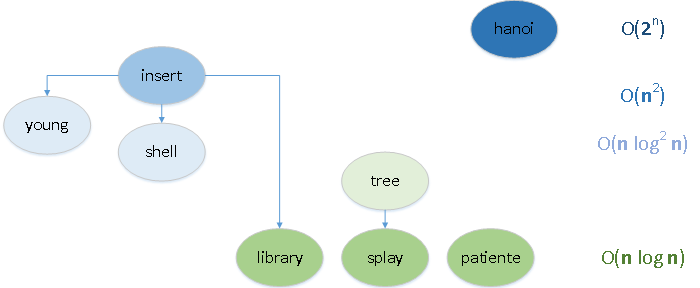
Как программисту, принимавшему участие в разработке платежных систем, мне неоднократно приходилось анализировать на наличие уязвимостей различные платежные сервисы, хранящие персональные данные клиентов и я постоянно сталкиваюсь с одной очень распространенной проблемой. Имя этой проблеме — инкрементальные айдишники.
Пример №1.
Сайт крупнейшего агрегатора платежных методов в России, обслуживает лидера онлайн-игр. После оплаты заказа переадресовывает клиента на урл вида
Перебирая значения параметра

Пример №1.
Сайт крупнейшего агрегатора платежных методов в России, обслуживает лидера онлайн-игр. После оплаты заказа переадресовывает клиента на урл вида
aggregator-domain/ok.php?payment_id=123456, который в свою очередь переадресовывает на сайт онлайн-игры с адресом вида (декодировал для читабельности) online-game-domain/shop/?...amount=32.86...¤cy=RUB...&user=user_email@gmail.com...&item_name=1 день премиум аккаунта...Перебирая значения параметра
payment_id, мы можем видеть логины юзеров в онлайн-игре, покупки, которые они совершали, их сумму.