
В отличие от нечеткого сравнения строк, когда обе сравниваемые строки равнозначны, в задаче нечеткого поиска выделяются строка поиска и строка данных, а определить необходимо не степень похожести двух строк, а степень присутствия строки поиска в строке данных.
Даны строка данных и строка поиска как произвольные наборы символов, состоящие из слов – групп символов, разделенных пробелами.
Требуется найти в строке данных наиболее близкий к строке поиска по составу и взаимному расположения символов набор фрагментов.
Для оценки качества результата поиска вычислить коэффициент релевантности, значение которого должно лежать в диапазоне от 0 до 1, где 0 должен соответствовать полному отсутствию символов строки поиска в строке данных, а 1 – наличию строки поиска в строке данных в неискаженном виде.
Поиск должен осуществляться путем посимвольного анализа исходных строк, с учетом взаимного расположения символов и слов в строках, но без учета синтаксиса и морфологии языка.
Поиск осуществляется в несколько этапов.
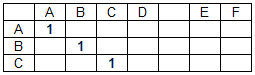
Матрица совпадений (M) представляет собой двумерную матрицу, количество столбцов которой соответствует длине строки данных, а количество строк – длине строки поиска. Элементы матрицы совпадений принимают значения 0 или 1 в зависимости от того, совпадают или нет соответствующие символы строк за исключением пробелов (разделителей слов).
Матрица совпадений для строки данных «ABCD EF» и строки поиска «ABC» имеет вид:
Постановка задачи
Даны строка данных и строка поиска как произвольные наборы символов, состоящие из слов – групп символов, разделенных пробелами.
Требуется найти в строке данных наиболее близкий к строке поиска по составу и взаимному расположения символов набор фрагментов.
Для оценки качества результата поиска вычислить коэффициент релевантности, значение которого должно лежать в диапазоне от 0 до 1, где 0 должен соответствовать полному отсутствию символов строки поиска в строке данных, а 1 – наличию строки поиска в строке данных в неискаженном виде.
Поиск должен осуществляться путем посимвольного анализа исходных строк, с учетом взаимного расположения символов и слов в строках, но без учета синтаксиса и морфологии языка.
Описание алгоритма
Поиск осуществляется в несколько этапов.
Построение матрицы совпадений
Матрица совпадений (M) представляет собой двумерную матрицу, количество столбцов которой соответствует длине строки данных, а количество строк – длине строки поиска. Элементы матрицы совпадений принимают значения 0 или 1 в зависимости от того, совпадают или нет соответствующие символы строк за исключением пробелов (разделителей слов).
Матрица совпадений для строки данных «ABCD EF» и строки поиска «ABC» имеет вид:

 С этой статьей я начинаю публиковать целую серию статей, результатом которой будет книга по работе .NET CLR, и .NET в целом. Тема IDisposable была выбрана в качестве разгона, пробы пера. Вся книга будет доступна на GitHub:
С этой статьей я начинаю публиковать целую серию статей, результатом которой будет книга по работе .NET CLR, и .NET в целом. Тема IDisposable была выбрана в качестве разгона, пробы пера. Вся книга будет доступна на GitHub:  CLR Book:
CLR Book:  Релиз 0.5.2 книги, PDF:
Релиз 0.5.2 книги, PDF: 












