Комментарии 620
require сможет скачать файл, то автор будет вполне достоин спецприза :)node index.js <words.txt для локального файла
что-нибудь в духе
lynx -dump https://github.com/hola/challenge_word_classifier/raw/master/words.txt>words.txt
node index.js <words.txt
для удаленного файла.
Считывание:
var stdin = process.openStdin();
var result=[];
var t="";
var word=«aaa»;
stdin.addListener(«data», function(d) {
t+=d.toString();
});
stdin.addListener(«end», function(d) {
result=t.split('\n');
var a=result.findIndex((x)=>x.toLowerCase()===word)===-1;
console.log('Result: ', a);
});
> Казалось бы, это просто — нужно только проверить, встречается ли строка в словаре — если бы не ограничение на размер решения в 64 КиБ.
Файл размером 6+ МБ. С собой тащить все данные не получится.
> Нельзя загружать никаких модулей, даже тех, что входят в стандартный комплект Node.js.
Загрузить их откуда-то тоже не получится (ну а как это сделать без модуля http?), да и это явно противоречит духу правил.
feldgendler, я думаю, стоит в явном виде написать, что нельзя работать с сетью и файловой системой (если вы почитаете правила ACM и подобных соревнований — там это явно написано).
Задача, тем не менее, не об этом.
А вот как бороться с «почти словами» с 1-2 опечатками — пока даже идей никаких нет.
… дающая наибольший процент правильных ответов.
function main(){
return Math.random() > 0.5
}
module.exports = {
init: function(data){
// м-м-м бинарничек
console.log('бдыщь')
},
test: main
}
не, ну а че б и нет? :)
var n = 1000000;
new Array(n).join('1').split('').reduce(function(memo){
memo += new Array(100).join('1').split('').map(function(){ return Math.random() > 0.5;}).filter(function(item){ return item;}).length / 100;
return memo;
}, 0) / n;
// 0.4949049399999358
вот только не понял почему map по undefined не отрабатывает:
(new Array(10).join('1').split('')).map(function(){ return true})
// [true, true, true, true, true, true, true, true, true]
(new Array(10)).map(function(){ return true})
// [undefined × 10]
map calls a provided callback function once for each element in an array, in order, and constructs a new array from the results. callback is invoked only for indexes of the array which have assigned values; it is not invoked for indexes which have been deleted or which have never been assigned values.© mdc
callbackfn should be a function that accepts three arguments. map calls callbackfn once for each element in the array, in ascending order, and constructs a new Array from the results. callbackfn is called only for elements of the array which actually exist; it is not called for missing elements of the array.
http://www.ecma-international.org/ecma-262/6.0/index.html#sec-array.prototype.map
Array.from(new Array(10)).map((el, ind) => el = ind+1)
// [ 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 ]
Боюсь на сто тестов статистики не хватит чтобы набить 50%.
Тем более что мы имеем две вероятности — того тест в словаре, и того что рандом выдаст >0.5. Поправьте если ошибаюсь, но тогда baseline 25% при условии случайного выбора «слово» — «не слово» для теста.
false, наберёт 50%. Чтобы сделать хуже, чем 50%, нужно специально постараться.Впрочем, человек в начале треда постарался и сделал 25% с рандомом :)
Интересно, сколько будет подано решений с return false — return true?
Имх., для поиска специалистов именно на JS — не совсем удачная постановка.
На практике для большинства проектов нужны кодеры. И нечего стесняться. Кодер — этот тот человек, который сможет качественно написать код по имеющемуся алгоритму. На самом деле кодерство — не такая уж простая задача, как некоторые думают.
Вроде бы в правилах данные ограничения не указаны. Стоило бы указать, чисто для проформы. Чтобы как в прошлый раз никто не придрался к вам с претензиями, что его решение несправедливо дисквалифицированно.
Ведь можно, например, найти весь словарь в числе пи, в программе указать лишь смещение, затем в init() рассчитать пи с нужной тончностью и получить 100% надёжность теста. А потом возмущаться, что вы недождались завершения работы init() и отдали приз другому.
Ну на JavaScript да.
Исходный файл со словами занимает 6906809 Байт, а требуется ужать всё вместе с кодом до 65535, т.е. чуть более чем в 100 раз.
Что-то мне не верится что из менее чем 1% знаний о исходном наборе данных можно восстановить гарантированно все 100%, какой бы при этом язык не был использован.
отличает слова английского языка
tsktsk
stddmp
bkbndr
Очень замечательные слова.
weltschmerzes
Очень английское
Как генерируются тестовые примеры? Поровну и тех и тех? Для каждого пункта с равной вероятностью выбирается взять слово из словаря или сгенерировать рандом? Или как ещё?
К тому же это после gzip, а его реализация тоже потребует памяти.
ну, в таком случае, можно упаковать часть словаря :)
Ну мне удалось его в 100КиБ впихнуть.
Как? У меня 820КиБ, хоть ты тресни.
Хотя, есть идея как сжать сильнее, но время распаковки O(n!) и будет длиться до конца жизни вселенной.
Тут ниже есть комментарий о возможности упаковки «где-то в 300 Кб-1 Мб смотря как упаковывать.» — но я постеснялся спрашивать, как была получена первая цифра.
А так — да, с gzip'ом 100% утрамбовываются примерно в 820-860 КиБ.
Какая-то фантастика. Почитаешь комментарии и думаешь, что я тут вообще делаю. Мне чтоб в 820 упаковать пришлось еще некоторую предобработку словаря сделать. И то сжимал winrar-ом. gzip-ом только 920 получается. Как вы это делаете? И что я тут делаю?
Разумеется я указал размер после «предобработки» и gzip'a, а не просто ужатого gzip'ом словаря. Имелось в виду, что словарь и после обработки содержит 100% информации о словах (т.е. не укорочен/не испорчен блумом/машинным обучением / etc).
100Кб было частичное префиксное дерево.
P.S. ДУмал, что удалил тот коммент.
97193/97193 (100.00%)
fn = 0
fp = 0
вот только нет, не упаковывается.
test.coffee?https://gist.github.com/vird/453a86cf16903c017b060cdd457baf86
Это просто верификатор. 100% выходит где-то в 300 Кб-1 Мб смотря как упаковывать.
в 64к не влезает даже арифметическим кодированием.
Насилуйте генератор на здоровье.
for (i = _i = 0; _i < 1000; i = _i += 1) {
console.log("https://hola.org/challenges/word_classifier/testcase/" + i);
}
node script.js > list
mkdir solution_list
cd solution_list
wget -i ../list
Склеивание результатов, думаю, понятно как реализовать.
Мое на 100k sample'ов только 62.67%.
Очень жаль, что нету live leaderboard'а.
Прошу прощения если эта цифра ввела кого-то в заблуждение
А сколько именно?
P.S. Из за вас я выбросил все свои решение меньше 75, и у меня не осталось ни одного :( осталось только идеи как сделать >=75
Идеи тут у всех примерно одинаковые. Единственное, что не пробовал — нейросети. Но тут очень велико разнообразие их конфигураций, способов задания входов, алгоритмов обучения. Все перепробовать времени не хватит.
Прощу прощения, если это выглядело так, как будто я виню Don_Eric за выброшенные решение, это не так, наоборот это мне дал повод на больше размышление.
Пробовал создать псевдо-нейронную однослойную сеть, которая бы собирала статистику по словам с помощью регулярок, но тут проблема в «обучении» — простешая проверка положения букв в слове генерирует порядка нескольких тысяч «нейронов» помноженное на 630.404 верных слов дают очень долгое время прогона. Более сложные регулярки дадут ещё большее количество вариаций «нейронов» и затраченного времени на обучение. После обучения необходимо сохранить результат работы для дальнейшей обработки, фильтрации и выделения наиболее значимых «нейронов», т.к. весь результат обучения вместе с кодом поместить в 64Кб нереально.
Для себя я сделал вывод, что экспериментирование и обучение подобной сети требует от нескольких дней до пары недель фул-тайм без каких-либо гарантий того, что результат будет удовлетворительным.
Если у вас получилось добиться результата > 80% рад за вас. Но не получилось бы так, что вы вводите в заблуждение всех остальных участников, отбивая мотивацию попробовать что-то ещё сделать в последние пару дней.
Смотрите в чем дело. Если вы используете любой алгоритм обучения, та же нейронная сеть к примеру, то вы используете ограниченное кол-во неправильных слов. Все вы просто не сможете выкачать из тесткейсов, их огромное множество и формируются они случайно. Я к тому, что набор тесткейсов на котором организаторы будут тестировать будет выбран случайно, и ваша достигнутая вероятность сохранится лишь тем больше чем больше тесткейсов совпадет в вашей выборке и выборке организаторов.
Вы пробовали закачать случайные 10000 (к примеру) тесткейсов те которые вы точно не использовали при обучении и каков был результат? Сделать это 2-3 раза?
Если >80% могу вас заранее поздравить с тем что вы точно будете в топе и бороться за призы. А вот если нет, тогда вы вводите в заблуждение остальных! И тогда надо бы ваш комментарий подредактировать, чтобы не отнимать мотивацию у остальных.
На мой взгляд такая вероятность которую вы обозначали не достижима по 2 причинам:
1. ограниченный размер решения в 64К
2. неограниченное число искажений слов (причем отличаются большинство неправильных слов от слова в словаре минимально)
По моему мнению, большинству участников интересно узнать, каких результатов добились остальные. Если разница небольшая, то это огромный стимул, а если разница большая — значит у него тесты неправильные :)
И если кто-то не выкладывает свои результаты из боязни дать другим стимул, то мне интересно увидеть кто каких результатов добился. Давать точные цифры нет смысла, т.к. каждый использует собственный способ оценки и блоки, на которых прогоняется решение локально и будет прогоняться организаторами — разные, а значит результат будет в любом случае отличаться от опубликованного.
Со своей стороны если я у кого-то увижу огромный результат, то я попытаюсь добиться такого же или хотя бы приблизиться к нему. И, к тому же, всегда существует вероятность того, что где-то в тестах у участника была ошибка (т.к. это не официальная таблица результатов), так что опускать руки рано.
В моём случае я действительно оценивал локально по относительно небольшой выборке — 23К блоков. После письма мне самому стало интересно насколько результат будет отличаться, если использовать другие сеты с блоками, поэтому я скачал ещё 2 сета по 10К блоков и протестировал своё решение только на них. По сравнению с предыдущим тестированием результат колеблется в пределах 0,1%.
В любом случае задачка интересная, и будет интересно увидеть в итоге решения других участников.
Возможно, после публикации исходников получится добиться ещё более лучших результатов, чем тот что займёт первое место в этом конкурсе.
Вкратце суть в том, что группе ученых предоставили сфабрикованные доказательства существования устройства, вырабатывающего антигравитационное поле, дали неограниченные ресурсы и предложили воспроизвести это устройство (оно, якобы, было разрушено). В итоге некоторые потратили все свое время, чтобы разоблачить фальсификацию, а один, поверив в то, что ему показали, пошел какими-то нестандартными путями и в конце концов изобрел нечто, обладающее самыми что ни на есть антигравитационными свойствами.
Даже если 80% — ошибка или фальсификация, это все равно прекрасная мотивация для «поверивших».
Я, со своей стороны, пока болтаюсь в районе 77% и, не обладая верой в собственную исключительную гениальность, вполне допускаю, что вы или кто-то другой достигли 80, а может и 85 процентов.
2. С другой стороны я считаю, что как минимум половина достижений написанных тут при кроссвалидации покажет другую цифру. (для некоторых моих решений это было справедливо)
3. Я свои решения не кроссвалидировал (исправляюсь, сейчас начну)
4. Но я все-равно уверен в своих цифрах т.к. 75.19% это по тем блокам, что я выкачал, а по словарю words.txt у меня 85%. Т.е. мне стоило бы задуматься, если у меня было бы решение 75%, а на словаре 60%. Значит заменив выборку результат может быть хуже с большой вероятностью.
пробовать другие методы уже поздновато, так что рад что у кого-то получилось чудо (С) Gromo

Тоже уверенно преодолел 80% на официальном тестовом скрипте, но до 81 ещё далеко.
Вообще удивлён тем, что так мало заявок >=80% — все необходимые для 80% идеи написаны на этой странице по много раз.
85% в топовых местах уже не кажутся нереальными.
я дошел до 77.5% и остановился. Знаю как можно набрать еще несколько процентов, но вряд ли успею
По поводу комментариев в статье — соглашусь, это кладезь идей и информации о решениях, вот только выбрать правильный подход сложно, и нужно время, чтобы выбранный подход довести до ума
сколько именно сказать не могу: во-первых, и тут мог ошибиться, а во-вторых, по правилам конкурса создалась ситуация когда никто не раскрывает свои цифры, и гораздо «выгоднее» (по теории игр) скрывать свои или вводить в заблуждение других.
Возможно, отрицательные результаты хеш-функции — не очень большая проблема.
То, что JS прекрасно работает с отрицательными индексами — тоже не проблема (как известно, JS и правду умножит и ложь поделит).
А вот то, что в результате фильтр Блума использует в два раза больший объем памяти — уже проблема…
P.S. эх, а только 85% правильных ответов достиг…
В 2 раза больший по сравнению с чем?
На какой выборке? У меня всего 78 на миллионе. С починенным блюмом и парой эвристик.
Речь об отрицательных хеш-суммах? Ну так они и сохранение в файл не переживают :-) Так что по любому надо заменять на сложение по модулю.
Чувствую вся разница реализаций будет именно в предобработке слов :-)
В принципе, исправляется достаточно легко — берем по модулю или меняем 0xFFFFFFFF на 0x7FFFFFFF (меньше кода).
И да, разница в основном будет в доп. обработке слов и в эвристиках.
Ну и в подходах к решению — те же нейронные сети не думаю, что стоит сбрасывать со счетов.
https://en.wikipedia.org/wiki/Bloom_filter
https://habrahabr.ru/post/112069/
Вероятность ложного срабатывания:

Оптимальное значение k:
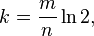
Что для этой задачи равно:
k = 65536/660000*ln(2) = 0,09929697*0,69314718 = 0,068827414. То есть оптимум 1.
p = 1 — e^(-n/m) = 1 — e^10,07080078125 = 1 — 4,2296729941409029988465653752585e-5 = 0,9999577
То есть вероятность ложного срабатывания 0,9999577. Что в общем очень-очень плохо.
Поправьте меня если я где-то ошибся в расчетах.
p = 1 — e^(-660000/524288) = 1 — e^(-1,25885009765625) = 1 — 0,28398039 = 0,7160196
Результат лучше, но все равно не очень хороший.
можно его увеличить если добавить юристику — заранее отсеивать шум по грамматическим правилам (типа 5 согласных подряд)
Но вообще там в правилах написано что текстовый файл с дополнительными данными можно архивировать. Дальше все зависит от того насколько хорошо сожмется файлик с фильтром. )
вес файла архива с помощью gzip + js файла должен быть не больше 64 КиБ.
а файл в распакованном виде может быть больше чем 64 КиБ.
Я прошу не интерфейс для тестирования, а доступ к тестирующему серверу. Например, в спортивном программировании перед соревнованием проводится пробный тур. На нем участники проверяют, что тестирующая среда ведет себя так, как они предполагают. А в соревнованиях topcoder есть возможность проверить свое решение на тестах из условия задачи.
Возможность проверить свое решение в реальной тестирующей среде, пусть и с дикими ограничениями, помогла бы избежать самой главной ошибки прошлого hola challenge.
Пользуйтесь.
Решение должно лежать в solution.js
Проверочные данные в validation.json
Сжатый словарь в serialize.gz
Если тестировать более правильным скриптом мое 70+% решение превратилось в 62.9%. Благо решений у меня было много, потому я переsubmit'ил одно 70% решение на другое, которое дает уже честные 69.8%. Но даже после этого я не уверен, что методология тестирования у меня правильная. Более того, я не уверен, что она будет совпадать с тем как будут тестировать организаторы.
Новый скрипт выкладывать не буду и объясню почему. ИМХО придумать идею, которая даст хороший процент — не проблема. Более того, большинство годных идей уже и так упомянуты в комментариях. А вот построить рабочее решение — это всё-таки то, за что тут дают деньги. Всё-таки я потратил на это 2 недели свободных вечеров и выходных, потому я, конечно, выложу наработки, но после конкурса.
Добился пока что 73% на тесткейсе из 100 тысяч слов, есть ещё пара мыслей, попробую, может ещё получится 0.5-1% выжать из решения.
Test correct words - 99.7636%
Test incorrect words - 52.0787%
Average correctness - 75.9212%
Данный подход хорош на первый взгляд, но он может давать довольно ощутимую разницу до ±1% за счёт того, что все слова для проверки уникальны, а в итоговом варианте часто будут встречаться дубликаты слов. Сам столкнулся с этим, и в моих случаях чаще было, когда дубликаты ухудшали результат, чем улучшали. Поэтому я предпочитаю делать быстрый прогон на предмет улучшений используя два словаря (от него и отталкиваюсь), но итоговый процент всё же прогоняю на тестовых блоках по 100 слов (он точнее, но проверка намного дольше из-за большого кол-ва файлов).
У меня с равной вероятностью выбирается словарь, а потом берётся из него случайное слово. Так что одно слово вполне попадается несколько раз на миллионе-то замеров. Смысла разбивать на группы по 100 слов не вижу смысла.
А вот брать среднее между результатами по выборкам разных размеров действительно нельзя — нужно суммировать число правильных ответов и делить на общее число замеров.
А вот брать среднее между результатами по выборкам разных размеров действительно нельзя — нужно суммировать число правильных ответов и делить на общее число замеров.
Я в начале так и делал, но если грубо взять словарь в 10 правильных слов и 100 неправильных (приближённо к реальности), при этом и там и там будет угадываться 10 слов, то в моём случае будет (100% + 10%) / 2 = 55%, а в случае общего замера будет ((10 + 10) / 110) * 100 = 18.2%, что неверно.
Объяснение же разницы уникальных и неуникальных слов довольно простое — всё зависит от количества false-negative для верных слов, т.к. повторяются именно они в связи с ограниченностью количества по сравнению с не-словами, коих невероятное множество. При 1-2% false-negative результат по сравнинею с проверкой блоков по 100 слов будет лучше, а вот при большем количестве false-negative результат будет хуже в связи с тем, что многие повторяющиеся правильные слова будут считаться неверными.
Так что одно слово вполне попадается несколько раз на миллионе-то замеров
Судя по
test[ word ] = wordsIndex[ word ] || false одно и то же слово несколько раз попасться не может, в отличие от блоков по 100 слов. Думаю, что Object.keys( test ).length не выдаст 1,000,000.Мне нет смысла настаивать на верности или неверности данного способа тестирования, но обратить внимание на этот момент стоит, просто, чтобы быть в курсе возможных расхождений с результатами тестирования блоков по 100 слов.
Совершенно не важно по сколько группировать: по 10, 100 или 100000. Если размер группы одинаков, то общее среднее значение будет одно и то же.
( X/N + Y/N )/2 === ( X + Y ) / 2NВ вашем примере будет ( 10 + 1 ) / 20 * 100 = 55% Так как мы делаем 20 замеров. Или ( 100 + 10 ) / 200 * 100 = 55%, если делаем 200. Чем больше замеров, тем выше точность.
Дублирование слов происходит в этой строчке:
var word = words[ isWord ][ Math.floor( Math.random() * words[ isWord ].length ) ]Вопрос: это пожелание или требование? Иными словами, будут ли рассматриваться решения, которые минифицированы/обфусцированы (или, например, скомпилированны из другого языка в javascript) без предоставления исходников? Если это требование, то, я считаю, это следует прописать в правилах более чётко.
Если это требование, то вот ещё более тонкий момент: если я, например, сделал и обучил нейронную сеть, которая решает задачу, обязан ли я описывать топологию сети, а так же предоставлять алгоритм обучения и наборы данных, которые я использовал?
Мы не можем машинно проконтролировать соблюдение этого условия, поэтому я вынужден сказать, что решения, не содержащие всех исходников, будут протестированы автоматом. Такой вариант нежелателен, так как мы не сможем оценить красоту решения.
Вопрос: вдвоем можно участвовать? Приз потом пополам поделить.
Уж простите за вопрос, но правильно ли я понимаю, что существует возможность «перекрестного» приглашения? Обычно в таких случаях «приглашающего» заставляют сначала зарегистрироваться самому, а уж потом приглашать друзей с реферальным кодом.
Как я понимаю метод init(data) запускается один раз и дальше запускается только test(word) много много раз? Или же на каждую сотню-блок — все по новой? Сколько будет минимально блоков?
а если построить структуру типа trie tree, где каждый узел это буквы алфавита и бит, если это слово в словаре. Вероятность принадлежности слова определять как глубину в этом дереве
trie?
2. С учетом того, что проверки после сабмита нет, будет ли дана возможность исправиться, если засабмиченная версия не запустилась или сразу на выход?
будет вызываться после test(word) и давать обратную связь алгоритму, чтобы он доплнительно обучался во время теста?
Мы будем использовать в тестах только ASCII-строки, содержащие латинские буквы нижнего регистра, а также символ ' (апостроф).
Значит ли это, что из словаря будут исключены аббревиатуры? Аббревиатура в нижнем регистре это уже слово (валидное или нет).
BTW. Тем временем 60,11% в 683 байта и 82.82% в 62464 байт.
Теоретически существует решение в как минимум 90%. Возможно, даже есть 95%.
У меня получилось решение, которое на диапазоне сидов 0-1000 работало хорошо, расширил диапазон, упало ниже 65%. Тестовый dataset странный предмет, вроде он есть, но на самом деле он бесконечный.
Решение откатил. Качаю dataset по-больше.
А ведь в самом топе будет жесточайшая битва, где победит тот кто лучше сбалансирует все свои словари, фичи и прочие признаки, и ужмёт их в 64 КиБ, вместе с исходником.
Да даже те же регулярки, если их будет столько много что они не будут умещаться в 64к, то можно будет подобрать такую комбинацию регулярок, которая будет покрывать больше всего правильных слов и давать меньшее кол-во ошибок на не словах.
xv
xvi
xvii
xviii
xw
xx
xxi
xxii
xxiii
xxiv
xxix
xxv
xxvi
xxvii
xxviii
Он каким образом получен-то?
Заодно таких ленивых можно слить, выдав им неправильные данные ;-)
И да, не всё меряется деньгами и первыми местами в конкурсах.
В природе существует туча разных молекул.
Перед нами стоит задача перебирать пролетающие мимо молекулы и отбирать только молекулы кислорода (O2) и воды (H2O).
Для этого мы будем использовать фильтр блума:
За первую хэш-функцию возьмем процедуру «получить названия атомов», которая возвращает список атомов, из которых состоит молекула.
Применим эту хэш-функцию к необходимым нам молекулам, и получим результат в виде «О» для первой молекулы и «Н, О» — для второй.
Минимальный фильтр блума с максимальным количеством false-positive в нашем случае будет выглядеть так:
H О
1 1
То есть ловя каждую молекулу и применяя к ней хэш-функцию «получить названия атомов», а затем сверяясь с нашим фильтром, мы ни за что не пропустим ни кислород, ни воду, однако мы «нахватаем» false-positive на таких молекулах как H2SO4, С2H5OH, HCl и т.д. Т.к. в этих молекулах тоже содержится H и/или O.
Для уменьшения количества false-positive, мы увеличим размер фильтра. Для максимального уменьшения false-positive на нашей хэш-функции, расширим фильтр до полной таблицы Менделеева.
В итоге мы получим подобный фильтр для наших O2 и H2O:
H He Li Be… O F Ne… Nb Mo…
1_0__0_0_..._1 0 0__… 0__0…
Теперь наш фильтр не пропустит молекулы С2H5OH и HCl, поскольку при применении к этим молекулам хэш-функции «получить названия атомов» мы получим результаты «C,H,O» и «H,Cl».
Пытаясь сверить «C,H,O» с нашим фильтром мы увидим, что, в нем хоть и установлены биты на местах H и O, но также не установлен бит на месте «С», Что говорит нам о том, что в списке того, что нам нужно, этой молекулы точно нет.
Однако у текущего нашего фильтра все еще будут случаться false-positive на таких молекулах как O3 и H.
Для решения этой проблемы мы введем вторую хэш-функцию вида «получить количество атомов в молекуле», которая будет возвращать количество указанных атомов в тестируемой молекуле.
Она будет применятся после сразу основной на каждом атоме из списка, возвращенного первой хэш-функцией. Наш фильтр тоже увеличится и будет теперь выглядеть примерно так:
H1 H2 H3 H4 H5… He1 He2 He3… O1 O2 O3 O4 O5…
0__1__0__0__0_..._0___0___0__..._1__1__0__0__0…
Этот фильтр уже не пропустит H, потому что после применения обеих наших хэш-функций к этой молекуле мы получим позицию «H1», для которой в нашем фильтре бит не установлен.
Стало хоть сколько-то понятней?
П.С.: Шрифт не моноширинный, парсер жрет пробелы, простите за извращения с "_"
Стало быть, фильтр Блума в чистом виде совершенно неприменим к решению данной задачи с приемлемой точностью, потому что для построения ряда битов надо слишком большое число. Накладных расходов больше, чем профит.
Исходный словарь рядом ухищрений получить ужать до 900 с копейками килобайт, дальше пока неясно, куда двигаться.
И да, я сомневаюсь, что человек, который первый раз услышал про нейронные сети/генетику/префиксные деревья только что, имеет шанс успешно воспользоваться этим «советом» :)
Совпадения с моим списком 55012
Различия 614277 (т.е. в 11 раз больше)
Список претендует на то, что он был получен честным способом.
Я уже организаторам говорил «а давайте всё-таки один общий false dataset». Ну вот. Теперь есть как минимум 2 dataset'а, которые отличаются друг от друга.
Просто к сведению.
Хочу скачать их все, но надо же знать когда остановиться.
Сумарно с сида 1 по 254200 всего встречается 10'041'446 уникальных не-слов, и 630'403 словарных слов. В словаре всего 630'404 слова, и единственное, которое до сих пор не встретилось — «constructor». С момента обнаружения последнего уникального слова в сиде 175475 прошло уже 78725 сидов. Для сравнения, чтобы найти предпоследнее слово, потребовалось всего 4475 сидов, в 17.6 раз меньше.
Так что есть хорошая вероятность, что слово «constructor» не встретится в выдаче вообще никогда.
json.loads(), а ему глубоко пофиг на специальные свойства JavaScript-а. Так что если баг и есть, то не на моей стороне.Проверил на node.js для очистки совести:
> s = JSON.stringify({constructor: "foobar"})
'{"constructor":"foobar"}'
> JSON.parse(s)
{ constructor: 'foobar' }
Их не так уж и мало — приблизительно 31 000, привожу скрипт (mysql) для их выборки:
SELECT word, COUNT(*) AS quality
FROM words_good
GROUP BY LOWER(word)
HAVING quality > 1
Думаю, их стоит исключить из списка, поскольку по условиям задачи все слова будут в нижнем регистре.
Вы предлагаете организатору конкурса сделать работу за конкурсантов?
cat words.txt | sort -fu | tr A-Z a-z > words_dedup.txtУ меня на два непробельных символа короче :)
cat words.txt | sort -unique > words_dedup.txthttps://habrahabr.ru/post/267697/#comment_8591149
1. Собираем статистику по длине слов на выборке в 1 млн. и выясняем, что простейшее if(strlen > 20 (или около того)) return false; else return true; дает что-то порядка 60% (точную цифру не сохранил).
2. Если тупо проанализировать словарь на отсутствующие 3-х буквенные комбинации с привязкой к длине слова и позиции относительно начала слова, то без всякого ИИ можно получить порядка 72%. С помощью перфиксного дерева можно много комбинаций запихнуть в 50+К, на код останется порядка 14К, вполне достаточно.
3. Любопытно, хотя и ожидаемо — анализ из п.2, но по контрольным суммам дает 50% :) Алгоритм расчета контрольных сумм дает равномерность распределения.
Не имел опыта работы с нейросетями, но общий смысл представляю так: Есть некий набор входных параметров, влияющих на выходные. При этом у каждого входного параметра есть некий весовой коэффициент, от которого зависит, насколько он влияет на результат. Весовые коэффициенты подбираются эмпирически в процессе обучения. Многослойность и т.п. — это уже детали, можно разобраться при желании. Но встает вопрос. Выходной параметр в текущей задаче это есть/нет в словаре. А что можно взять за входные параметры? Длину слова? Префиксы/постфиксы? Ну т.е. буквально на пальцах какие такие признаки будет искать этот пресловутый ИИ в мешанине слов и недослов?
Интересно попробовать adversarial networks
1. Используя префиксное дерево, дающего 100% результат удалось добиться размера 845Кб
2. То же префиксное дерево, но с результатом 98% весит уже 784Кб
3. 89% — 474Кб
4. 85% — 356Кб
и т.д…
Данная статистика наглядно показывает зависимость размера от результата.
Использование фильтрации по неиспользуемым сочетаниям букв даёт нулевой результат — 3-х буквенные неиспользуемые сочетания занимают 12Кб места, а толку от них 0, т.к. в выборке сгенерированных «неправильных» слов размером в 500тыс слов (ссылка в комментах выше) ни одно из этих сочетаний не используется.
Попытки найти какой-либо шаблон в словах, который бы использовался в словаре, но не использовался бы в сгенерированных словах, не удались. Сгенерированные слова слишком похожи на слова из словаря, а слова из словаря слишком разные. Например, слова с 5 согласными буквами подряд встречаются в словаре 1053 раза, а слова с одной и той же буквой 3 раза подряд встречаются 109 раз. При этом данная статистика бесполезна.
Следующим шагом была попытка использования масок для слов, например, 010101100 — где 0 — гласные, 1 — согласные, либо маски, сгруппированные по буквам, например, проверка одного и того же слова сразу по нескольким маскам, использующим различные группировки букв. Толку от подобного подхода слишком мало — опять же из-за сильной схожести сгенерированных слов со словами из словаря.
Наибольший результат достигается использованием фильтрации по первым буквам слов — для 3 букв при размере 17.5Кб результат — 57%, для 4 букв — 89Кб и 64%, для 5 букв — 73% (размер не смотрел). Использование префиксного дерева позволяет уменьшить размер — 3.5Кб для 3 букв, 24Кб — для 4 букв, 89Кб — для 5. Отсекая малоиспользуемые префиксы для 5 букв можно добиться результата в 71% при размере 60Кб (мой лучший результат). Попытка дополнительно учитывать длину слова и/или конечные буквы значительно увеличивает размер, при этом мало влияя на результат. Например, попытка использовать 2 префиксных дерева по 4 буквы для отсечения слов и с начала и с конца, даёт 66% при размере 58Кб, 5 с начала и 3 с конца — 71% при размере 67Кб. Выводы можете сделать сами.
Думаю, что нейронные сети могут найти более хороший подход к решению данной задачи, однако каким образом можно будет запихнуть результат обучения подобной сети в 64 Кб — не имею ни малейшего представления.
P.S. когда я увидел возможность упаковки 6.3Мб словаря в 100Кб, я был очень удивлён, но у меня появился стимул. Очень жаль, что это оказалось усечённое префиксное дерево :(.
Осталось добавить что попытка использовать описанные алгоритмы совместно, не дает хороших результатов, так как множества слов по которым алгоритмы отрабатывают имеют мощные пересечения и если каждый алгоритм дает скажем 57% то совместное применение разве что 58%.
Что до упаковки… как только мы пытаемся применить какую-то допобработку к словарю, степень сжатия результата сильно уменьшается. Мне например удалось ужать словарь что-то до 4,8Мб без потерь, но в итоге упаковался он в те же условные 100Кб.
Что в общем логично, так как любая уменьшающая словарь допобработка уменьшает его избыточность, а меньше избыточность == меншь степень сжатия.
: (
Например, слова с 5 согласными буквами подряд встречаются в словаре 1053 раза, а слова с одной и той же буквой 3 раза подряд встречаются 109 раз. При этом данная статистика бесполезна.
Не скажите. А сколько раз слова с 5 согласными встречаются среди «не слов»? Если их в разы больше, это вполне можно использовать.
Total words: 598216
Words with 5 consonants: 68502 or 11.45%
Words with 3 same letters: 2835 or 0.47%
Против статистики «верных» слов:
Total words: 630404
Words with 5 consonants: 1053 or 0.17%
Words with 3 same letters: 109 or 0.02%
Так что я ошибался — проверка на 5 согласных подряд должна добавить несколько процентов.
Добавлю сюда результат проверки для 4 гласных подряд:
Correct words with 4 vowels: 2447 or 0.39%
Incorrect words with 4 vowels: 6467 or 1.08%
Как бы там ни было, скорее всего в итоге вы будете в небольшом выигрыше. Все зависит от того, как вы изначально сохраняете trie в файл — попробовать стоит.
1. дерево ужимается в памяти, но не при сериализации (главный аргумент)
2. последние уровни усечённого дерева настолько разные, что смысла ужимать нет
Также думал о побитовом сжатии — использовать биты вместо 26 букв и апострофа, тогда вместо потенциальных 27 байтов можно использовать 4 (3 при усечении алфавита). И это действительно даёт преимущество в сериализации 2-3 первых уровней, где используются практически все буквы из алфавита, но на на последних уровнях, которые заканчиваются на 1-2 возможные буквы, это преимущество оказывается избыточным. Усечённое дерево, обычно сжимаемое до 60Кб, с использованием битовой маски превращается в 200Кб
Похожесть я смотрел по Levenshtein distance, и вот некоторые результаты:
29% не-слов отличаются от словаря на одну букву, 20% на 2, 12% на 3, и так по убыванию…
В случаях когда есть одно отличие, то в 60% поменяли букву, 30% добавили букву, и в 10% убрали.
В 17% меняли букву а, 9% букву b, 7% d,c,e. потом r 5.5%,l 5.3%,' 5.3%,n 4.3%,s 4.2%…
В 43% менялась первая буква, 11% 2 и 3я, 9% 4я…
В тех случаях когда добавляли или удаляли букву, то значимых отличий не наблюдается. Буквы s,e,a,i,' добавляются чаще остальных, e,a,i удаляются.
Очень любопытный факт, что если смотреть на похожесть слов в словаре между собой, то в 72% слов она равна 1, 24% равна 2, 3% равна 3, 1% 4, и гораздо меньше 1% в остальных случая.
Интересно будет посмотреть на такой граф, и сколько будет ключевых слов, которые порождают остальные.
Надеюсь, после конкурса будут предоставлены исходники генератора (чтобы убедиться в его «равномерности» на всех номерах блоков), а также доказательства случайного выбора номера блока для финальной проверки (а также того, что этот номер был выбран непосредственно перед зачётным тестом).
наиболее оптимальным, на мой взгляд, будет что-то типа:
отсеять непохожие слова с помощью эвристики, регулярок, сетей ит.д. | проверить похожие слова в Блуме
Я вот попробовал прогнать словарь с помощью функции metaphone (Функция metaphone была написана Lawrence Philips и описана в книге [«Practical Algorithms for Programmers», Binstock & Rex, Addison Wesley, 1995].), получился словарь не порядка 660 тысяч слов, а уже порядка 250 тысяч. При этом % угадываний на тесткейсах колеблется между 75-80%.
Хеши от 660 тыс. слов у меня получилось ужать в 429K (только данные), новый словарь пока не пробовал ужимать.
success: 81.53%
negatives: 100%
positives: 0%
т.е. наблюдаю то, что функция test отлично справляется с возвращением значения true (ни единой ошибки), а все ошибки связаны возвращением значения false.
success: 68.15%
negatives: 0%
positives: 100%
Но у меня получается, что на 1 хеш приходится довольно много срабатываний разных слов, поэтому эту идею пока что забросил.
Уже приблизился к такому результату:
success: 69.5%
negatives: 32.79%
positives: 67.21%
Тут ещё мысль пришла, можно ведь выбрать некое число бит под хеш, полный список всех хешей можно сгенерировать скриптом в отсортированном порядке, затем погонять тесты так, чтобы собралась некоторая статистика true и false срабатываний по каждому хешу. Затем всему этому списку хешей можно в оконцовке поставить бит 0 или 1, в зависимости того как часто срабатывало попадание слова в словарь. Ну и в итоге достаточно будет хранить лишь 1 бит на хеш, т.е. в 64к поместится 512000 бит. Например, мой словарь который получился по metaphone+crc32 уже можно уместить без потерь, даже не применяя gzip сжатия.
Ненастоящие слова будут распределены по всем возможным хешам тоже примерно равномерно и вряд ли вам удастся выделить небольшое количество хешей, на которые приходится много попаданий из ненастоящих слов так чтобы проставить им нули.
И порядка 3400 байт занимает код.
Если получится всё уместить в 64Кб, то дальше будет борьба за каждые сотые доли процента ;)
Вообще, можно и нужно функцию хеширования переделать. А потом уже можно будет эксперементировать с обрезанием части хешей, чтобы запихнуть всё содержимое вместе с исходниками в 64КБ.
У crc32 слишком много хешей от не слов пересекаются с хешами от слов.
Или можно будет где-то организовать доску с результатами попыток сжатия, но уже без финансовой мотивации — чисто ради интереса.
> сжатия, но уже без финансовой мотивации — чисто ради интереса.
то я бы ограничился
cat words.txt | gzip --best > data.gz
Мой коллега предложил гениально-простое самое маленькое возможное решение, которое будет давать 100% результат — это сгенерировать md5 хеш от словаря, и затем восстановить весь словарь перебором. Жаль, что ограничение по времени — 1 неделя :)
Напоминает анекдот, когда девушка идет к гинекологу из-за проблем.
Доктор: Тут болит?
Она: Нет
Доктор: А тут?
Она: Нет
Доктор: Тут?
Она: Да!
Доктор: О, милочка, это у вас гланды!
Да, конечно во всех реальных случаях сжимаются не произвольные данные, но такой способ всё равно даст огромное количество коллизий, как ни крути.
А жаль, идея выглядела такой перспективной :)))
Весь код решения должен находиться в единственном файла на JS
уважаемый feldgendler, разрешено хранить часть кода в файле данных?
HyperLogLog is an algorithm for the count-distinct problem, approximating the number of distinct elements in a multiset
Идея была в том чтоб хранить весь словарь в hll, в тесте добавлять туда слово и проверять если изменился общий счетчик. Для 64Кб hll ошибается на 0.15% в оценке общего кол-ва слов, но для проверки одного слова этого недостаточно
HLL — 60%
Я уже неделю как застрял на 76%, всё пытаюсь выжать очередные 0.2-0.5% в надежде как-нибудь добраться и до 80%, но пока тщетно. Правда теперь я уже не уверен насколько мои проценты «честны», прочитав комментарии выше по ошибке проверки точности алгоритма.
попробовал стандартные алгоритмы — decision tree, random forest, gradient boost trees и нейронные сети. Фичеры особо не выбирал, взял сами буквы и разные счетчики. Все алгоритмы дали примерно одинаковые результаты, около 65%, причем нейронные сети показали хуже всего.
Наилучший результат достиг с помощью GradientBoostedTrees, 73%, с помощью 100 деревьев глубиной 10, но я не уверен что получится их ужать в 64кб
Сейчас проверяю очень интересную идею с помощью deep learning. Надеюсь она не оправдает себя, так как не представляю как можно потом перевести код python и theano в javascript
В обычных алгоритмах machine learning я столкнулся с проблемой выбора features. Выбрал самые примитивные счетчики, типа длина строки, и изобрела новые, но в какой-то момент результат практически перестал улучшаться. Самое идеальное решение было б скормить алгоритму слово по буквам, а там пусть он сам находит самые лучшие правила, но это не сработало.
В поисках такого алгоритма, который извлекает свойства из слова, я нашел статью, которая описывает очень интересный способ, и интуитивно мне очень понравился. Потом оказалось что идея не настолько нова и используется еще в некоторых случаях. Идея в том, чтоб представить слово в виде вектора значений, и использовать свертку чтоб найти локальные свойства, и уже по этим свойствам судить если слово похоже на словарь или нет. Чтоб найти матрицу, которая переводит букву в значение и оптимизировать свойства используется Свёрточная нейронная сеть (CNN).



В этой работе используют CNN чтоб классифицировать текст твиттера и его хештеги по его сентиментальности, и в принципе, простой заменой данных на наш словарь можно попробовать этот алгоритм (нужен python и theano). Код на гите
Алгоритм показал 64% при начальных параметрах, и вполне возможно добиться более лучших результатов если настроить несколько hyper parameters. К сожалению, у меня компьютер не настолько мощный, и theano лучше бежит на GPU — поэтому я это оставил.
Understanding Convolutional Neural Network for NLP — еще одна хорошая статья на эту тему
Character-level Convolutional Networks for Text Classification — Похожая работа, но использует для прогонки lua и Torch. Запустить не получилось.
И еще в копилку deep learning, можно упомянуть RNN, рекуррентная нейронная сеть. Один из крутых специалистов, Andrej Karpathy, в своей статье описывает как ее можно использовать для похожих задач.
The Unreasonable Effectiveness of Recurrent Neural Networks
Тут можно посмотреть как с помощью RNN предсказывают следующую букву в слове. Кстати, в его гите много библиотек для machine learning, написанные на javascript, в том числе cnn и rnn
http://lbd.udc.es/Repository/Publications/Drafts/1441181386528_practical_compressed_string.pdf
Так бы можно было запостить решение на 66.978 % в 1714 байт
Или 66.093 % в 979 байт
1.
75.57-75.36 % (Реально если протестировать на большой выборке будет где-то 75%, ИМХО)
59989 байт
Решение подобрано используя OpenCL
2. Решение ломает ЛЮБОЙ скрипт тестирования где-то на 18-й 23-й тысяче запросов.
Воспроизводится на 6.0.0 и на 6.1.0
Ломает в смысле вызов функции приводит к зависанию. Тестовый console.log внутри функции даже не вызывается.
Потому вопрос к организаторам. Как быть?
Решения принимаются до 27 мая 2016, 23:59:59 UTC.
Я правильно понимаю, что по Москве это 28 мая 02:59:59?
Пожалуйста, после того, как закроется форма для приема решений, и обычный человек уже ничего не сможет изменить — опубликуйте все присланные решения (js + данные + объяснения) на гитхабе? Если вам так будет удобнее, то выложите их без указания авторов, просто под какими-то ничего не значащими номерами, чтобы имя победителя до последнего оставалось в тайне.
Это очень, очень поможет остальным участникам (и наблюдателям) существенно поднять свою квалификацию, прочитав и поняв решения даже тех, кто не вошел в первую тройку — а вам это будет в конечном итоге выгоднее, так как в следующем конкурсе средний уровень специалистов будет выше.
Спасибо.
После нескольких проб остановился на анализе статистики подобных сочетаний для верных слов и фильтрации всего остального — этот способ намного короче, чем пытаться анализировать последовательность согласных на сложность произношения, т.к. в словаре оказалось неожиданно много сложновыговариваемых сочетаний.
И такой фильтр даже работает, но итоговый результат получается хуже из-за того, что реализация занимает место и приходится жертвовать чем-то другим. Если бы генератор генерировал больше случайных последовательность букв, возможно этот вариант бы и сработал, а так слишком много «не-слов» практически не отличиются от «слов», что делает подобную проверку бесполезной (в моём случае).
На одном миллионе тестовых слов 82.05% на другом 82.1%
Все последние изменения, которые я пробовал сделать, приводили к увеличению максимум на +0.01%. Это очень мало, буквально в пределах погрешности. Т.к. я выбрал медленный алгоритм, то ожидание генерации файла и проверка на миллионе слов превратились в пытку :)
так как кол-во слов ограничено, то на 60,000 блоках кол-во повторений почти 45%, из которых 39% это слова и 6% не-слова.
Публикую это потому что это все-таки хак, а не интересный алгоритм, да и зависит от кол-ва блоков в финальном тесте
Зато меня порадовало сообщение (на часах 02:59), что «Вы можете публиковать еще и еще свои решения до наступления deadline»...)))
Напишите обязательно! Я делал почти тоже самое, и тоже дошел до уменьшения слов до около 300К+ для скармливания их блуму, но так и не успел разобраться, как сохранить результат в <64k. В лучшем случае получал 120. Напишу об этом во второй части статьи.
из которого удалил редко используемые словами, но часто используемые не-словами биты
Вот этот момент не ясен, я тоже так сначала начал, но по факту оказалось, что я подстраиваюсь под обучающую выборку не-слов. Решил что это не очень хорошо и перестал, видимо зря. Возможно для больших выборок это уже получается подстройка не на обучающую выборку, а на зависимости в генераторе, что имеет смысл. Мой вариант в начале набирает около 80%, но он учится по пути, если можно так сказать, и скажем на 10 миллионах вполне показывает результат в районе 85%, а на 20 миллионах ближе к 90%, вот только вопрос станут ли организаторы действительно тестировать на большом кол-ве блоков.
Это на 200 килоблоках (20 миллионов слов)
Судя по тому, что удалось понять, глядя на «неправильные» слова — они все (за исключением мусора) сформированы по принципу [префикс]основа[суффикс] (префикс и суффикс опциональны), а все префиксы, основы слов и суффиксы получены из словаря.
Например:
enzedrinesiancy = [enzedrines] + iancy <= [b]enzedrines + [r]iancy
testabaxilement's = test + [aba] + xilement's <= test[s] + [b]aba + [e]xilement's
Кажется, что префиксы и суффиксы строятся откусыванием кусков, которые сами по себе входят в словарь, а основы слов — откусыванием полученных префиксов и суффиксов. Впрочем, уверенности нет, да и в моем решении это никак не помогло (у меня 81.1%).
словарь я никак не обрабатывал, мне было интереснее попробовать больше алгоритмов. Сначала взял каждую букву как параметр в machine learning, и добавил еще другие: длина слова, кол-во гласных, согласных, их отношение. Местоположение апострофа с начала и с конца, перед и после какой буквой он идет. Средняя сумма частот букв в слове. Конволюцию (свертку) с окном в 3 буквы.
После этого попробовал все стандартные алгоритмы классификации, и наилучший результат по отношению к размеру показало дерево решений: глубина 7 и 250 узлов дало 66.3%. Дерево заняло 1.2Кб, сам код тоже немного, а остальное место использовал под bloom filter, взяв первые 6 букв слова. Это решение ушло в hola.
Другие решения:
Лес деревьев решений (100 штук) вместо 66.3% давали 72%, но размер был очень большой. Нейронная сеть с 100 нейронами в Spark mllib показала 65%, а в Azure ML почти 70%, но у меня не получилось вытащить этот слой, или повторить результат в open-source frameworks. А жаль, имплементация нейронов очень простая, и 100 штук ужималось как одно дерево. В последний момент даже поднял 2 виртуалки в Azure на 32 ядра каждую, но особо результат не улучшили.
Были еще попытки deep learning на theano и torch, но все бежало очень медленно, так как не было сильной графической карты.
Кроме machine learning я пробовал построить префиксное дерево, получилось слишком большим. Была еще попытка анализировать расстояние между словами и построить автомат Левенштейна, где все слова представлены как граф, и для проверки слова надо было взять все узлы с его начальной буквой, и попробовать найти путь с этим словом (благо времени достаточно). Предварительные результаты были хорошие, но постройка минимального графа для всех слов бежала почти бесконечное время.
Почти все опыты проводил на scala в кластере Spark, или локально на C# с помощью Accord.Net. Фичеры и алгоритмы, их hyper parameter tuning, сравнивал в Azure ML
Огромное спасибо организаторам за бесценный приобретенный опыт и интересное время!
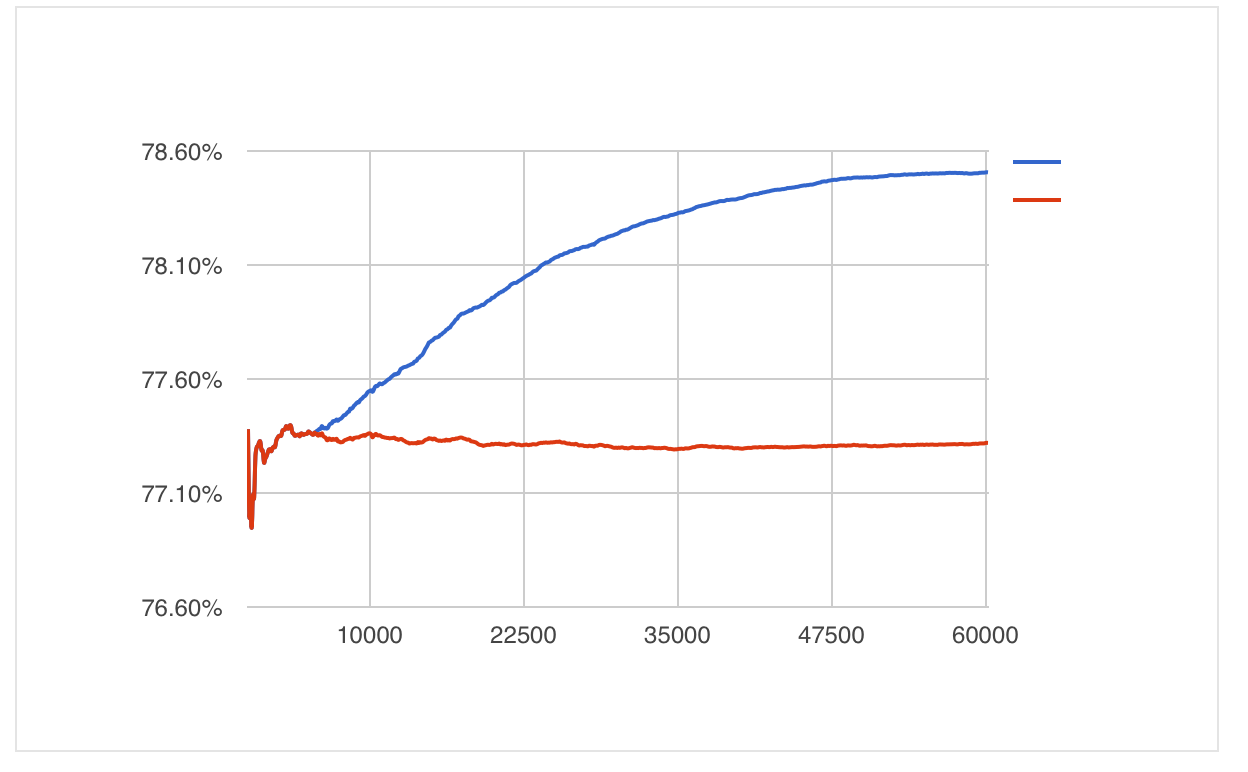
Это на 200 килоблоках (20 миллионов слов)
0-10М — слова это те которые повторились 2 и более раз
10-15М — те которые 3 и более раз и тд.
А вообще каждые 5 миллионов можно было проходить по статистике и у всех уменьшать счетчик на 1, а те которые стали 0 — удалять. Тогда алгоритм не выйдет за память никогда и в итоге даст число максимально близкое к 100% на бесконечном наборе входных данных. Но я все это отправлял в торопях и писалось все в полубессознательном состоянии уже, поэтому этого не сделал.
Судя по комментариям участники не брезговали использовать читерскими методами подкручивания статистик.
Например накопление словаря или статистик аргументов вызова функции.
Т.к. цитирование переписки с организаторами здесь поощряется, то
Я ничего не берусь говорить, но читая предыдущие отзывы о конкурсах от hola, я специально очень сильно расспрашивал про методику проведения и оценки. Я пока сделаю гипотезу, что скрипт, который будет проверять решения будет сбрасывать состояние решения каждого участника каждые 1000 блоков, к примеру. Потому все решения, которые базируются на запоминании потока вызовов внезапно превратятся в тыкву. У меня в кармане тоже были читерские методы подкрутки решения, например корректировка до априорной вероятности, но я не рискнул их включать в решение из-за боязни изменения условий тестирования в последний момент. Ждем комментариев от организаторов.
Мне очень интересно какую методологию тестирования будут использовать. Насколько я понял минимальным гарантированным квантом является один блок по 100 слов.
Это не работает. Редкие комбинации эффект дают, но не решающий.
Как то мне это 50/50, если они на это решаться — вы в топе.
В любом случае будет много негатива с обеих сторон, какой бы путь не был выбран.
В голову приходит только ограничение максимального количества блоков, чтобы не дать собрать статистику, либо действительно перезапускать init через какой-то интервал.
Возможно это было где-то тут: https://habrahabr.ru/company/hola/blog/282624/#comment_8887076
Поправьте меня, если ошибаюсь.
Мне, конечно, нравится решение с алгоритмами, да и уверен что участники потратили гораздо больше сил, времени и проявили больше смекалки, чтоб выжать лишнюю долю процента. С другой стороны также признаю что конечный результат у второй группы гораздо выше.
В общем, запасаемся попкорном 3е июня…
(Надеюсь, что победит гибридное решение, которое стартует с 85% и доходит быстрее всех до 100)
Выложил вторую часть своих экспериментов.
Организаторы конкурса были на высоте. Вовремя и корректно отвечали на вопросы и все такое. Но все же один минус есть. Я считаю, правильным было бы указать точное количество слов, на котором будет проходить тестирования. Формулировка "Мы будем тестировать Вашу программу на большом количестве слов" не является корректной. 1 млн. — это большая выборка? или 100 млн большая? — все относительно. Получается, зная алгоритм работы всех программ участников, организаторы сами могут выбрать победителей просто меня объем выборки. Это точно также, если судья двух боксеров (один который молотит как из пушки первые 3 раунда, а потом остается без сил, а второе менее активный в начале и более выносливый), решит судья, что 3 раунда будет (ВО время боя) — победит первый боец, решит что 5 раундов — второй. Было бы правильней предупредить обоих бойцов о количестве раундов ДО начала боя. А так, больше никаких замечаний к организаторам нет. Они молодцы.
Условия конкурса должны быть таковыми, чтобы каждый участник мог проверить решение другого и признать, что его хуже или лучше. От судей должно требоваться только запустить все тесты и взять 3-ку лучших. Более того, хотелось бы видеть предварительный результат своего решения (просто, чтобы удостоверится что тот файл отправил и тому подобное). Не нужно менять правила на ходу. Достаточно учесть замечания участников (если они объективны) и в следующем конкурсе не допустить подобного. А сейчас организаторы поставили себя в неудобную ситуацию, где в любом случаю будут недовольные. Я же стремлюсь к таким условия, где я и любой другой смогут признать свое поражение и не искать себе оправдание типа "если бы организаторы взяли другую выборку или объем данных я бы точно победил!". Все должно быть максимально прозрачно!
Просто нам не пришло в голову решение с накоплением информации о дубликатах, которое, действительно, разрушает методику тестирования. Это можно было легко исправить, сказав, что мы будем перезапускать программу и переинициализировать модуль каждые сколько-то блоков, но мы просто не предвидели именно этого. Мы могли бы и ничего не говорить о том, будет ли перезапускаться программа, но тогда было бы больше неопределённости, чем сейчас, и больше оснований для обвинений в несправедливости.
Все конкурсы разные, и в каждом можно найти какой-то изъян, что-то, чего не предусмотрели.
А чтобы сформулировать ограничение по времени выполнения, пришлось бы в точности описывать тестовую систему: железо, ось, настройки всевозможные. То есть вернулись бы к вопросу «как справедливо измерять производительность», от которого хотелось уйти.
Допустим, одно из решений падает (из-за переполнения памяти, например) после 1 миллиона тестов, другое — после 2, третье — не падает никогда. Непонятно, как быть, если все три решения при этом постоянно улучшают свои результаты при длительном тестировании.
Дотестировать до 1 миллиона, до 2 или до какого-то большего числа? Для упавшего решения брать последний результат или 0?
Посмотрим, на самом деле, насколько распространённой окажется эта проблема.
Все это понятно. Критика (пожелания) были направлена не на то, чтобы обвинить организаторов в чем-то, а на то, чтобы задание описывалось на основе системы тестирования. Т.е. в начале должна создаваться система тестирования. На этом этапе Вы смогли обнаружить простые вопросы типа: а сколько памяти? а сколько времени? а сколько выборки?.. и только после того как система тестирования готова, описывать задание. Ну я бы поступил так (задним умом мы все сильны). Что дает такая система? Если на каком-то этапе обнаружится, что система работает не совсем корректно или что-то не учитывает, Вы исправляете и заново прогоняете решения. Может мои идеи утопичны и/или я плохо мысли выражаю.
давайте новый конкурс! мне понравилось)) хочу еще.
Кстати, есть же открытые задачи, за которые даже есть награды. Например, поиск чисел Мерсенна.
Как то участвовал в решениитакой бесплатной задачи. Хоть и бесплатно, хоть и простая числодробилка, но, блин, интересно от того, что задачу еще кто-то кроме тебя решает.
Прописать в условиях, что в течении какого-то срока (скажем первая неделя из 4х) условия могут уточняться.
За неделю силами самих участников какая-то часть неоднозначностей будет устранена.
Я хотел бы ответить на комментарий @hellosandrik, — это всё же задача обучения, — может ей быть! Самообучающийся алгоритм способен распределить грамматические и синтаксические правила языка, — просто оценивая вероятность появления буквосочетаний. — И это не очень сложно для создания, но трудно для анализа и весьма ресурсоемко может оказаться, — вероятностные сети охочи до памяти и процессора. В естественном языке есть правила и исключения, этому нас даже в школе учат, — так вот правила — статистически классифицируются, а вот исключения нет. Мои сети при размерах образцов в три символа прекрасно отбрасываю всякий шум, но псевдослова начинают хорошо определять при размерах сэмпла в 4 символа, а это значит что дата-файл уже будет не менее пол мегабайта, при размере сэмпла в пять символов достигается оптимум, сеть полностью распределят правила языка (и это коррелирует с длинной корней, суффиксов и префиксов в словах). Я проверял следующим образом — давал программе половину словаря, но результат классификации не менялся, давал ей четверть словаря, и т.д. наступает момент когда обучающей выборки недостаточно, чтобы определить вероятностные законы языка, — это тонкий порог, определим лишь эмпирически.
Что же касается «задачи обучения», то я пришел к выводу что ни одно решение не будет лучше чем узко-направленного анализа словаря и битовой оптимизацией на уровне блюм фильтра. Максимум, что у меня выходило это 72% (в 64 Кб рамках)
Зато алгоритмы обучения универсальны, быстро имплементируемые и легко применяются в других задачах
Самой прорывной оказалась идея рассекать слова на части по определенным буквам, части нумеровать и хранить именно их.
Это сильно сэкономило место в блюме. Сейчас уже жалею, что так и не попробовал битовую оптимизацию.
Немного не по теме, но опубликуйте, пожалуйста свои приложения в альтернативных маркетах или выложите просто в открытый доступ. А то как-то странно получается – я хочу скачать приложение для андроида, чтобы пользоваться сервисами гугла в забаненном гуглом регионе (Крым, например). А куда ведёт ссылка на установку с вашего сайта? В Гугл-плэй, который в этом случае недоступен. Такое "тонкое" издевательство в итоге получается?
Спасибо. Но, тем не менее, надо сделать это более очевидным, т.к. я даже при запасе позитивного настроя и желании установить найти где скачать и установить на андроид-устройство так и не смог. Кнопка "скачать" просто никак не реагировала на нажатия. Беглый анализ ajax-запросов, к сожалению, ничего полезного не дал.
p.s. Господа, желающие минусануть в карму, эти мои комментарии на текущий момент являются самым полезным, что получила компания Hola из своих постов c конкурсом – обратную связь от реального потенциального пользователя.
если открывать с устройства, то ссылок нет.
Андроид 6.0, Nexus 5:

Конкурс по программированию на JS: Классификатор слов