
Где Agile ужасен, особенно Scrum
15 min
Translation
Гибкость — без сомнения хорошая вещь, и в манифесте Agile есть смысл. По сравнению с хрупкой практикой под названием «водопад», Agile заметно лучше. Тем не менее, на практике гибкие подходы часто наносят глубокий вред, и в действительности вряд ли здесь уместна дихотомия Agile/Waterfall.
Я видел, как множество вариантов Agile, называемых Scrum, реально убивают компанию. Под «убивают» я имею в виду не «ухудшение культуры», а скорее когда акции компании падают почти на 90% за два года.
Agile вырос из среды веб-консалтинга, где он приносил определённую пользу: при работе с привередливыми клиентами, которые не знают, чего они хотят, обычно приходится выбирать из двух вариантов. Или одолеть клиента: установить ожидания, соответствующую оплату за переделки и поддерживать отношения равенства, а не подчинения. Или принять некорректное поведение клиента (как, скажем, приходится многим дизайнерам) и ориентировать рабочий поток вокруг клиентской дисфункции.
Я видел, как множество вариантов Agile, называемых Scrum, реально убивают компанию. Под «убивают» я имею в виду не «ухудшение культуры», а скорее когда акции компании падают почти на 90% за два года.
Что такое Agile?
Agile вырос из среды веб-консалтинга, где он приносил определённую пользу: при работе с привередливыми клиентами, которые не знают, чего они хотят, обычно приходится выбирать из двух вариантов. Или одолеть клиента: установить ожидания, соответствующую оплату за переделки и поддерживать отношения равенства, а не подчинения. Или принять некорректное поведение клиента (как, скажем, приходится многим дизайнерам) и ориентировать рабочий поток вокруг клиентской дисфункции.




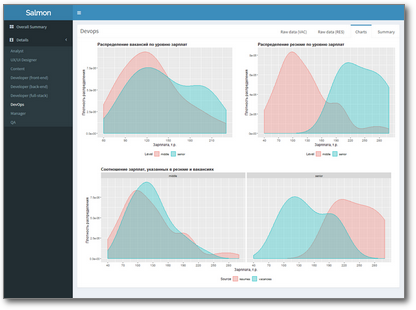
 Довольно давно являюсь обитателем Хабра, но так и не доводилось читать статьи на тему многомерных кубов, OLAP и MDX, хотя тема очень интересная и с каждым днем становится все более актуальной.
Довольно давно являюсь обитателем Хабра, но так и не доводилось читать статьи на тему многомерных кубов, OLAP и MDX, хотя тема очень интересная и с каждым днем становится все более актуальной.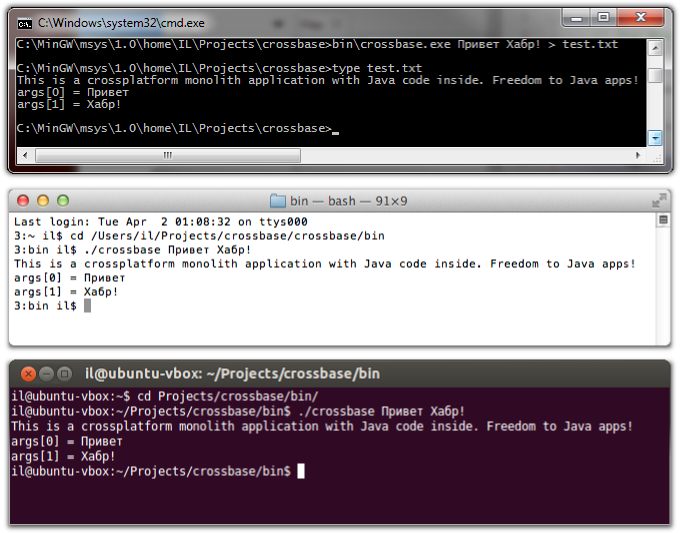






 Мы, дети 90-х, любим добавить в задания
Мы, дети 90-х, любим добавить в задания 
