
Захотелось более детально разобраться и попробовать самостоятельно написать Transformer на PyTorch, а результатом поделиться здесь. Надеюсь, так же как и мне, это поможет ответить на какие-то вопросы в данной архитектуре.

image processing
Захотелось более детально разобраться и попробовать самостоятельно написать Transformer на PyTorch, а результатом поделиться здесь. Надеюсь, так же как и мне, это поможет ответить на какие-то вопросы в данной архитектуре.

Какой модели доверить свои задачи в 2025 году? От редактирования текста и кодинга до анализа видео с контекстным окном в 2+ миллиона слов — узнайте, какая модель решит именно ваши задачи и стоит ли платить за две подписки одновременно.

В данной статье описывается пошаговая методика развертывания виртуальной машины (ВМ) с установленной операционной системой Windows 10 на сервере с операционной системой Ubuntu. Решение предполагает установку всех необходимых компонентов, настройку виртуализации с помощью QEMU/KVM, а также организацию удалённого доступа к ВМ посредством noVNC.

Привет, Хабр! Меня зовут Нина, я работаю инженером исследователем в AIRI, где мы с моими коллегами активно исследуем возможности генеративного ИИ. Особое место в нашей рабочей повестке занимает применение диффузионных моделей к различным задачам.
Не так давно мы получили приятную новость: нашу статью по семантическое выравнивание при генерации 3D‑моделей приняли на ICLR. В ней мы нашли способ, как построить выровненную генерацию 3D‑объектов, используя гайданс предобученной диффузионной модели, чтобы сделать редактирование или гибридизацию более надёжными. В этой статье хотелось бы кратко пересказать суть нашей работы.


В последнее время технологии замены лиц находят все больше применений. Помимо использования в развлекательных целях, они стали особенно важны для индустрии фильмов и рекламы, позволяя существенно ускорить и удешевить производство. Однако в таком подходе, где мы заменяем лишь область лица, есть несколько существенных недостатков. Чтобы от них избавиться, мы начали смотреть в сторону создания технологии переноса головы целиком
В данной статье мы представляем нашу новую модель GHOST 2.0 — первую опенсорс модель переноса головы на изображениях. Давайте мы подробнее разберём составляющие модели и её архитектуру, а также углубимся в процесс обучения.

Недавно захотел вспомнить молодость и пересмотреть отличные лекции по машинному обучению из университета. Смотреть, конечно же, стало скучно уже на 5 минуте, и мне пришла в голову отличная идея. Что если перевести все лекции в текст и просто нажимать Ctrl Cmd+F про то, что мне интересно? Загуглил, какие есть варианты, есть огромная куча API от заграничных и российских разработчиков, есть удобные UI для локального развертывания, но это все не то. API - скучно (да и вдруг потом на этих лекциях модели будут тренировать), UI не поддерживают Apple Silicon, и все гоняют на процессоре. Хочется что-то, чтобы и видеокарту использовало, и работало быстро, и чтобы можно было восхититься высокой скоростью моего M1 (спойлер — не восхититься).

Исследуем свёрточные нейронные сети (CNN): полный гид
От основ нейронных сетей до кода: узнайте, как CNN обрабатывают изображения. Включает:
Основы: нейроны, слои, обучение.
Компоненты CNN: свёртка, пулинг, полносвязные слои.
Архитектуры: LeNet, AlexNet, VGG, GoogleNet, ResNet.
Практический пример на TensorFlow.
Сравнение с Vision Transformers. Идеально для новичков и экспертов

Диффузионные модели перевернули мир генеративного искусственного интеллекта, вытеснив GAN'ы и вариационные автоэнкодеры. Но как они работают? Чем отличаются друг от друга? И как научиться их использовать?
Эта статья — путеводитель для тех, кто хочет разобраться в диффузионных моделях с нуля. В ней вы найдете три подхода к изучению — теория, практика и продвинутая практика.


Всем привет! Меня зовут Александр Тюрин, я руководитель группы «Методы оптимизации в машинном обучении» в AIRI и старший преподаватель Сколтеха. Мы с коллегами занимается оптимизацией распределённого обучения — это довольно актуальная проблема, учитывая, что современные модели обучаются на многих тысячах GPU.
За последние 2 года нам удалось сделать несколько открытий в асинхронных методах оптимизации, которые мы изложили в 5 статьях [1–5] на NeurIPS и ICLR. В этой статье я расскажу, в чём заключаются особенности распределённого обучения и что нового привнесли в него мы с точки зрения теории.


LLM, или большая языковая модель, это нейронная сеть с крайне большим количеством изменяемых параметров, которая позволяет решать задачи по обработке и генерации текста. Чаще всего реализована в виде диалогового агента, с которым можно общаться в разговорной форме. Но это только определение, причём одно из. В статье — больше о понятиях LLM, из чего она состоит, а также возможность немного попрактиковаться.
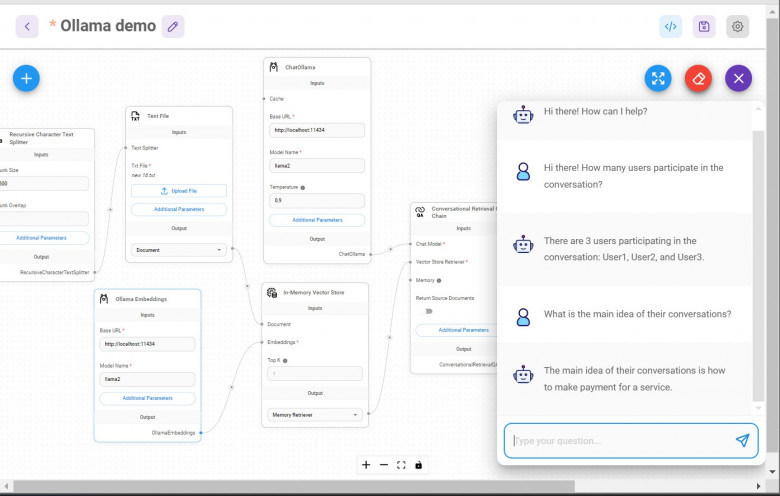
Привет, Хабр.
В этой статье о том, как без написания кода поставить себе локально и использовать LLM без подключения к сети. Для меня это удобный способ использования в самолёте или in the middle of nowhere. Заранее выгрузив себе нужные файлы, можно делать анализ бесед саппорта с клиентами, или получить саммарайз отзывов из стора на приложение, или оценить резюме/тестовое задание кандидата...





После первого поста на Хабре моя карьера сделала неожиданный поворот, и я оказался перед непростой задачей классификации, которая потребовала от меня изучения новых для себя архитектур и подходов. В этой статье я поделюсь опытом решения задачи классификации облака точек, имея лишь 10 примеров для каждого класса. Мы поговорим о том, как преобразование данных в воксельное представление и использование сиамских нейронных сетей с 3D свертками помогло достичь отличных результатов.


Наши реалии довольно суровы, сейчас даже стало сложно не то что зайти на какой нибудь chatGPT, но и посмотреть любимый ютюбчик. Если на пк и телефонах мы еще можем использовать VPN, то вот как обстоят дела с приставками, smartTV/android TV? Если на многих телеках иногда поддержка приложений заканчивается быстро, что уж тут говорить о ВПН или прокси, туда их вообще фиг пихнешь.
Дома у каждого из вас скорее всего есть проводной интернет, а значит роутер тоже есть. Для роутеров ведь тоже существует линукс, причем свободный и гибкий - это OpenWRT. В рамках данного гайда/проекта, я расскажу, как можно обеспечить в своем доме качественное интернет покрытие, используя ARM железяки и linux. Но нет, речь пойдет не о перепрошивке роутера, ибо это дело может во первых окирпичить ваш роутер, ну а во вторых - у многих из вас дома роутеры "бытового класса", как и у меня, которые просто нет смысла даже шить. ибо 64 мегабайта дискового пространства хватить конечно можно, но это будет впритык, а нам хотелось бы управлять всей системой через WEB-UI.
P.S. Конечно есть Keenetic и его фишки, но я таким добром не обладаю и рассказать на примере кинетик роутеров это не могу.
Данный гайд подойдет только на OrangePI zero или OrangePI zero 3, на версию 2 я не нашел прошивки, если у вас получится ее найти - все шаги будут аналогичны. Но так же использовать мощную плату под это дело будет скорее менее рационально, если вы конечно не собираетесь крутить на ней дополнительно докер, или же какой то веб хост. На 3й версии прошивка существует как снапшот(в активной разработке), поэтому проще прилечь к стабильной стороне ядра и выбрать чисто зеро-версию.

Современные технологии глубокого обучения проникают в самые разные области нашей жизни — от автономных автомобилей до систем видеонаблюдения. Однако высокая вычислительная сложность традиционных нейронных сетей остается серьёзным препятствием на пути к их широкому применению на мобильных устройствах и встраиваемых системах.
Группа исследователей из Smart Engines представила на международной конференции ICMV 2023 инновационное решение — биполярную морфологическую нейронную сеть YOLO (Bipolar Morphological YOLO, BM YOLO), которая сочетает в себе энергоэффективные вычислительные подходы и проверенную временем архитектуру YOLO для детектирования объектов.