Читать дальше →

Александр Бобров @Syra
User

Гоночка на JavaScript (30 строк кода)
2 min
В продолжение недели ненормального программирования (как заметил phpcmsdev) решил написать игру в 30 строк кода. Так как тетрис, змейка и арканоид уже были сделаны, выбор пал на гоночки, которые входили в стандартный набор портативной игры.

Ссылка на fiddle.
{kind=link}
Ссылка на fiddle.
Крошечная змейка на JavaScript (30 строк кода)
2 min
Прочитав статью про excel в 30 строк, я загорелся глупой идеей — написать что-нибудь на 30 строк. Не долго думая остановился на змейке.
Особенности:

Особенности:
- 30 строк необычного JavaScript (задача была уместить в 30 строк, так что код похлеще чем на ночных хакатонах)
- Использованные библиотеки: отсутствуют
Графы для самых маленьких: Dijkstra или как я не ходил на собеседование в Twitter
6 min
Не так давно наткнулся на статью о том, как Michael Kozakov не смог решить алгоритмическую задачу на собеседовании в Twitter. Решение этой задачи — почти в чистом виде один из самых стандартных алгоритмов на графах, а именно, алгоритм Дейкстры.
В этой статье я постараюсь рассказать алгоритм Дейкстры на примере решения этой задачи в несколько усложненном виде. Всех, кому интересно, прошу под кат.
В этой статье я постараюсь рассказать алгоритм Дейкстры на примере решения этой задачи в несколько усложненном виде. Всех, кому интересно, прошу под кат.
Крошечный Excel на чистом JavaScript (30 строк кода)
2 min
Translation
Особенности:
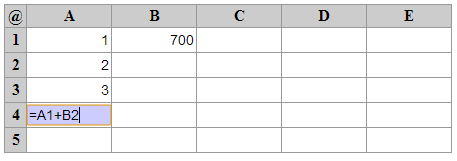
- Около 30 строк обычного JavaScript
- Использованные библиотеки: отсутствуют
- Синтаксис как в Excel (формулы начинаются с "=")
- Поддерживаются произвольные выражения(=A1+B2*C3)
- Обнаруживаются циклические ссылки
- Автоматическое сохранение в localStorage
Постмортем: как умудриться совершить 14 ошибок, разработав одну социальную игру
9 min
Tutorial
В феврале 2012 года было принято решение сделать компьютерную игру самостоятельно. Исходя из смешанного опыта, замахиваться на величайшие вершины геймдева я не стал, сконцентрировавшись на достижимых целях: небольшая социальная игра на паре крупнейших российских платформ. Все условия этому способствовали: желание разрабатывать игры, опыт ведения проекта от идеи до релиза и поддержки, знание специфики социалок, опыт работы с инвесторами, хорошие знакомые, у которых всегда можно спросить если и не помощи, то хотя бы совета.

Поэтому следующие полтора года разработка прошла все стадии: концепт, поиск постоянных участников команды, разработка альфы, беты, релиз, поддержка — всё это время мы двигали разработку в нужном направлении, так или иначе решили все возникшие проблемы и… Игра «не выстрелила». Да, такое случается, игры не выстреливают гораздо чаще, чем наоборот. После того как я отвлёкся от бесконечных фиксов, планов на развитие, обсуждений с коллегами и прочих сотен неотложных вопросов, отошёл от проекта, послушал умных людей и попросту отдохнул — я понял, что этот опыт можно формализовать и даже поделиться с такими же независимыми разработчиками. Всех таковых, а также просто заинтересованных — жду под кат.
КДПВ: текущее распределение проектов в геймдеве, одна Белоснежка и семь гномов.
Поэтому следующие полтора года разработка прошла все стадии: концепт, поиск постоянных участников команды, разработка альфы, беты, релиз, поддержка — всё это время мы двигали разработку в нужном направлении, так или иначе решили все возникшие проблемы и… Игра «не выстрелила». Да, такое случается, игры не выстреливают гораздо чаще, чем наоборот. После того как я отвлёкся от бесконечных фиксов, планов на развитие, обсуждений с коллегами и прочих сотен неотложных вопросов, отошёл от проекта, послушал умных людей и попросту отдохнул — я понял, что этот опыт можно формализовать и даже поделиться с такими же независимыми разработчиками. Всех таковых, а также просто заинтересованных — жду под кат.
КДПВ: текущее распределение проектов в геймдеве, одна Белоснежка и семь гномов.
И снова Vertica на HighLoad++
2 min
Как и в прошлом году, выступил на HighLoad++. На этот раз мой доклад шел в секции «Базы данных», я рассказывал о том, какие системы хранения рационально использовать для задач многомерного анализа больших данных. Слайдов на сайте организаторов пока нет, как только появятся — я добавлю ссылку. Вкратце, презентация была построена так:
Вертика была представлена как один из вариантов, но про нее я рассказывал подробнее всего, показывая, как и за счет каких архитектурных решений она хорошо подходит под аналитические задачи и обгоняет всех конкурентов.
- Постановка задачи, то есть что такое многомерный анализ больших данных
- Функциональные требования, которые следуют из постановки задачи
- Технические сложности
- Как их можно решать, при помощи каких архитектурных решений и систем
Вертика была представлена как один из вариантов, но про нее я рассказывал подробнее всего, показывая, как и за счет каких архитектурных решений она хорошо подходит под аналитические задачи и обгоняет всех конкурентов.
История ошибок: как мы построили и потеряли бизнес с оборотом 500 000 долларов в год
4 min
В 2009 году я рассказывал, как мы строим наш маленький семейный бизнес с оборотом 1500 долларов в месяц. Прошло четыре года. Бизнес вырос до оборота 500 000 долларов в год, и мы его потеряли. Самое время рассказать о допущенных ошибках.
Публикация на хабре позволила нам познакомиться с разными людьми, наш бизнес многим понравился. Так в 2010 году мы продали 50% компании частным инвесторам. После успешной трехлетней совместной жизни в сентябре 2013 года наши партнеры отжали бизнес. Мы остались ни с чем.
Как говорил Франклин, “Опыт — это чудесное умение распознавать ошибку, которую ты допускаешь снова”. Возможно, для кого-то все, написанное ниже, знакомо и понятно. Для нас это было впервые и, оглядываясь назад, я вижу множество ошибок, которые привели к такой ситуации. Буду рад ими поделиться с вами.
Что же произошло?
Публикация на хабре позволила нам познакомиться с разными людьми, наш бизнес многим понравился. Так в 2010 году мы продали 50% компании частным инвесторам. После успешной трехлетней совместной жизни в сентябре 2013 года наши партнеры отжали бизнес. Мы остались ни с чем.
Как говорил Франклин, “Опыт — это чудесное умение распознавать ошибку, которую ты допускаешь снова”. Возможно, для кого-то все, написанное ниже, знакомо и понятно. Для нас это было впервые и, оглядываясь назад, я вижу множество ошибок, которые привели к такой ситуации. Буду рад ими поделиться с вами.
Active Record против Data Mapper-а для сохранения данных
4 min
Эти 2 шаблона проектирования описаны в книге Мартина Фаулера «Шаблоны корпоративных приложений» и представляют собой способы работы с сохранением данных в объектно-ориентированном программировании.
В этом упрощенном примере, дескриптор базы данных вводится в конструкторе Foo (Использование инъекции зависимостей здесь позволяет тестировать объект без использования реальной базы данных), и Foo использует его, чтобы сохранять свои данные. Do_something — просто метод-заглушка, заменяющий бизнес логику.
Пример шаблона Active Record
class Foo
{
protected $db;
public $id;
public $bar;
public function __construct(PDO $db)
{
$this->db = $db;
}
public function do_something()
{
$this->bar .= uniqid();
}
public function save()
{
if ($this->id) {
$sql = "UPDATE foo SET bar = :bar WHERE id = :id";
$statement = $this->db->prepare($sql);
$statement->bindParam("bar", $this->bar);
$statement->bindParam("id", $this->id);
$statement->execute();
}
else {
$sql = "INSERT INTO foo (bar) VALUES (:bar)";
$statement = $this->db->prepare($sql);
$statement->bindParam("bar", $this->bar);
$statement->execute();
$this->id = $this->db->lastInsertId();
}
}
}
//Insert
$foo = new Foo($db);
$foo->bar = 'baz';
$foo->save();
В этом упрощенном примере, дескриптор базы данных вводится в конструкторе Foo (Использование инъекции зависимостей здесь позволяет тестировать объект без использования реальной базы данных), и Foo использует его, чтобы сохранять свои данные. Do_something — просто метод-заглушка, заменяющий бизнес логику.
Из опыта создания кружка программирования для детей
6 min
Появление кружка
Предыстория этого кружка началась два года назад. К тому времени я уже несколько лет подрабатывал репетитором информатики и программирования, в основном ученики по информатике программировали на Pascal, он больше распространен в школах.
А осенью 2011 года у меня появился необычный ученик: ребенок в 4 классе очень хотел заниматься программированием, и узнав что я обучаю Delphi мы с его мамой договорились что попробуем обучить на нём. Ребенок оказался очень одарённым, и у нас получилось очень хорошие и плодотворные занятия. И многие идеи появились только благодаря его постоянному интересу к программированию.
К тому времени я работал в кружке робототехники Дворца Молодёжи Свердловской области. И у меня появилась мысль организовать такой кружок программирования у нас. Для создания этого кружка прежде всего надо было определить несколько вещей:
- на какой возраст рассчитываем. Дело в том что я много изучал психологию (закончил психфак УрГПУ), и знаю что логическое мышление начинает развиваться (и наиболее хорошо развивается) начиная с младшего подросткового возраста. И занятия программированием будут в плане развития наиболее ценны для подростков. Это прежде всего это развитие способности держать в голове большие объёмы информации, и выстроенные между ними логические связи. Итак возраст был определён минимум от 11 лет и старше (рекомендуемый возраст 13-15 лет);
- цели обучения программированию (особенно учитывая возраст детей). Первая цель как написано выше — развивающая. Вторая цель — заинтересовать, приобщить детей к этому занятию. Именно поэтому (да простят меня сторонники традиционного обучения, требующие сначала обучать на обычном языке, а потом уже на объектно-ориентированном) было четкое понимание, что именно программы с графическим интерфейсом будут интересны детям. Итак мы переходим к третьему аспекту:
- в какой среде программируем. В качестве такой среды был выбран Lazarus. Во-первых синтаксис Pascal куда проще для детей, поэтому я решил отказаться от того же С#. От Delphi пришлось отказаться, потому что учреждение областного уровня не может позволить поставить пиратский софт, а на покупку софта для нового кружка скорее всего денег бы не нашлось. Поэтому был выбран бесплатный Lazarus
Хабраинтервью с бывшим сценером
Easy
7 min

Интервью с бывшим сценером, русским, участником топовой crack-группы в середине 2000-х. Вопросов было задано не слишком много, поэтому он ответил на все. Похожие вопросы я объединил, если что потерялось — пишите, добавлю. Структура и принципы работы сцены уже давно известны, поэтому здесь мы их почти не касались, но чтобы заполнить возможные пробелы в ближайшее время я продолжу перевод сайта «aboutthescene», первую часть которого публиковал ранее. Несмотря на то, что было уже много статей про сцену, практически в каждой из них всплывает вопрос, получают ли сценеры какую-то прибыль от своей деятельности. И в этом интервью он снова был задан. Ответ на него и все остальные — под катом.
Базы знаний. Часть 1 — введение
5 min
Одной из причин слабого использования Linked Data-баз знаний в обычных, ненаучных приложениях является то, что мы не привыкли придумывать юзкейсы, видя перед собой только данные. Трудно спорить с тем, что сейчас в России производится крайне мало взаимосвязанных данных. Однако это не значит, что разработчик, создающий приложение для русскоязычной аудитории совсем уж отрезан от мира семантического веба: кое-что всё-таки у нас есть.
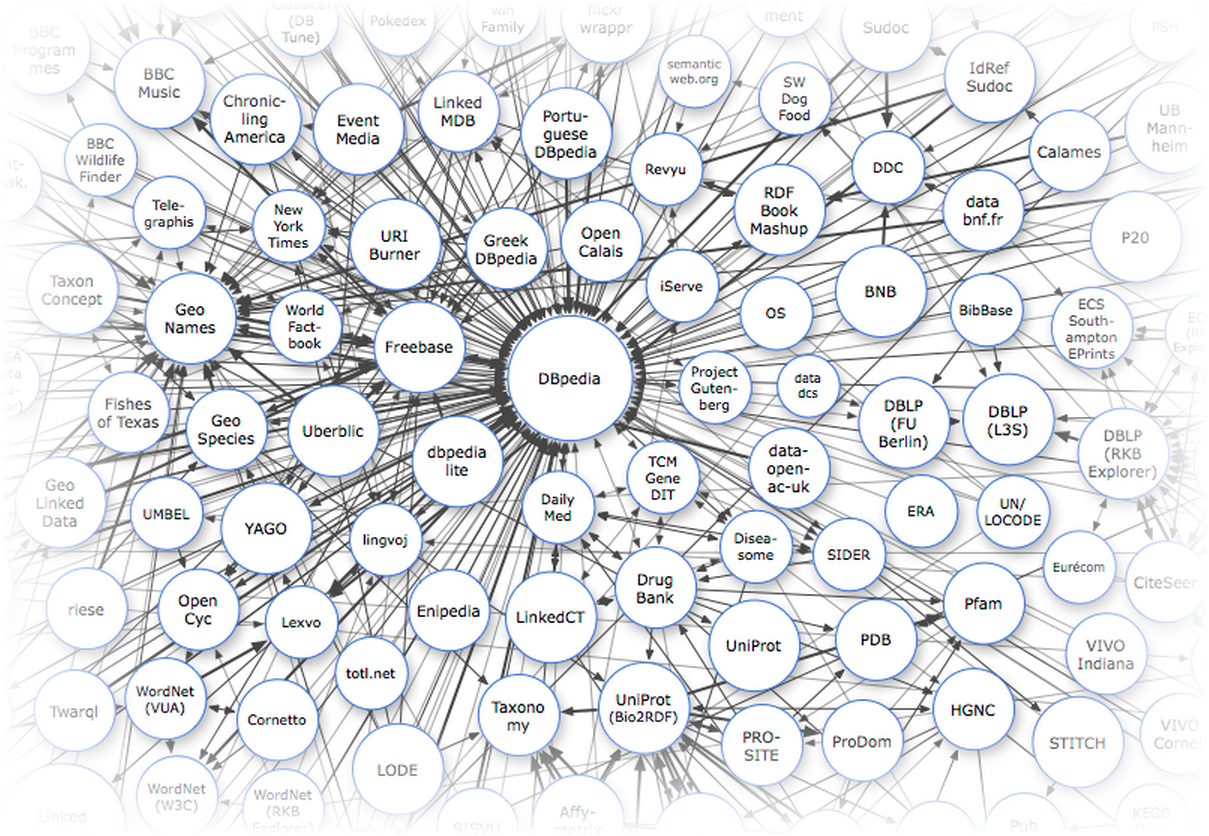
Основными источниками данных для нас являются международные базы знаний, включающие русскоязычный контент: DBpedia, Freebase и Wikidata. В первую очередь это справочные, лингвистические и энциклопедические данные. Каждый раз когда вам в голову приходит мысль распарсить кусочек википедии или викисловаря — ущипните себя как следует и вспомните о том, что всё, что хранится в категориях, инфобоксах или таблицах, уже распарсено и доступно через API с помощью SPARQL или MQL-интерфейса.
Я попробую привести несколько примеров полезных энциклопедических данных, которые вы не найдете нигде, кроме Linked Data.
Эта статья — первая из цикла Базы знаний. Следите за обновлениями.
Основными источниками данных для нас являются международные базы знаний, включающие русскоязычный контент: DBpedia, Freebase и Wikidata. В первую очередь это справочные, лингвистические и энциклопедические данные. Каждый раз когда вам в голову приходит мысль распарсить кусочек википедии или викисловаря — ущипните себя как следует и вспомните о том, что всё, что хранится в категориях, инфобоксах или таблицах, уже распарсено и доступно через API с помощью SPARQL или MQL-интерфейса.
Я попробую привести несколько примеров полезных энциклопедических данных, которые вы не найдете нигде, кроме Linked Data.
Эта статья — первая из цикла Базы знаний. Следите за обновлениями.
- Часть 1 — Введение
- Часть 2 — Freebase: делаем запросы к Google Knowledge Graph
- Часть 3 — Dbpedia — ядро мира Linked Data
- Часть 4 — Wikidata — семантическая википедия
Парадоксы теории множеств и их философская интерпретация
22 min
Tutorial
Краткий синопсис
По образованию я физик-теоретик, однако имею неплохую математическую базу. В магистратуре одним из предметов была философия, необходимо было выбрать тему и сдать по ней работу. Поскольку большинство вариантов не единожды было обмусолено, то решил выбрать что-то более экзотическое. На новизну не претендую, просто получилось аккумулировать всю/почти всю доступную литературу по этой теме. Философы и математики могут кидаться в меня камнями, буду лишь благодарен за конструктивную критику.
P.S. Весьма «сухой язык», но вполне читабельно после университетской программы. По большей части определения парадоксов брались из Википедии (упрощённая формулировка и готовая TeX-разметка).
Введение
Как сама теория множеств, так и парадоксы, ей присущие, появились не так уж и давно, чуть более ста лет назад. Однако за этот период был пройден большой путь, теория множеств так или иначе фактически стала основой большинства разделов математики. Парадоксы же её, связанные с бесконечностью Кантора, были успешно объяснены буквально за половину столетия.
Следует начать с определения.
Что есть множество? Вопрос достаточно простой, ответ на него вполне интуитивен. Множество это некий набор элементов, представляемый единым объектом. Кантор в своей работе Beiträge zur Begründung der transfiniten Mengenlehre даёт определение: под «множеством» мы понимаем соединение в некое целое M определённых хорошо различимых предметов m нашего созерцания или нашего мышления (которые будут называться «элементами» множества M)[1]. Как видим, суть не изменилась, разница лишь в той части, которая зависит от мировоззрения определяющего. История же теории множеств как в логике так и в математике весьма противоречива. Фактически начало ей положил Кантор в XIX веке, далее Рассел и остальные продолжили работу.
Парадоксы (логики и теории множеств) — (греч.
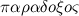 — неожиданный) — формально-логические противоречия, которые возникают в содержательной множеств теории и формальной логике при сохранении логической правильности рассуждения. Парадоксы возникают тогда, когда два взаимоисключающих (противоречащих) суждения оказываются в равной мере доказуемыми. Парадоксы могут появиться как в пределах научной теории, так и в обычных рассуждениях (например, приводимая Расселом перифраза его парадокса о множестве всех нормальных множеств: «Деревенский парикмахер бреет всех тех и только тех жителей своей деревни, которые не бреются сами. Должен ли он брить самого себя?»). Поскольку формально-логическое противоречие разрушает рассуждение как средство обнаружения и доказательства истины (в теории, в которой появляется парадокс, доказуемо любое, как истинное, так и ложное, предложение), возникает задача выявления источников подобных противоречий и нахождения способов их устранения. Проблема философского осмысления конкретных решений парадоксов — одна из важных методологических проблем формальной логики и логических оснований математики.
— неожиданный) — формально-логические противоречия, которые возникают в содержательной множеств теории и формальной логике при сохранении логической правильности рассуждения. Парадоксы возникают тогда, когда два взаимоисключающих (противоречащих) суждения оказываются в равной мере доказуемыми. Парадоксы могут появиться как в пределах научной теории, так и в обычных рассуждениях (например, приводимая Расселом перифраза его парадокса о множестве всех нормальных множеств: «Деревенский парикмахер бреет всех тех и только тех жителей своей деревни, которые не бреются сами. Должен ли он брить самого себя?»). Поскольку формально-логическое противоречие разрушает рассуждение как средство обнаружения и доказательства истины (в теории, в которой появляется парадокс, доказуемо любое, как истинное, так и ложное, предложение), возникает задача выявления источников подобных противоречий и нахождения способов их устранения. Проблема философского осмысления конкретных решений парадоксов — одна из важных методологических проблем формальной логики и логических оснований математики.Целью данной работы является изучение парадоксов теории множеств как наследников античных антиномий и вполне логичных следствий перехода к новому уровню абстракции — бесконечности. Задача — рассмотреть основные парадоксы, их философскую интерпретацию.
Об одной особенности теоремы Котельникова
3 min
Написать данную статью меня вдохновила следующая задача:
Как известно из теоремы Котельникова, для того, чтобы аналоговый сигнал мог быть оцифрован а затем восстановлен, необходимо и достаточно, чтобы частота дискретизации была больше или равна удвоенной верхней частоте аналогого сигнала. Предположим, у нас есть синус с периодом 1 секунда. Тогда f = 1∕T = 1 герц, sin((2 ∗ π∕T) ∗ t) = sin(2 ∗ π ∗ t), частота дискретизации 2 герца, период дискретизации 0,5 секунды. Подставляем значения, кратные 0,5 секунды в формулу для синуса sin(2 ∗ π ∗ 0) = sin(2 ∗ π ∗ 0,5) = sin(2 ∗ π ∗ 1) = 0
Везде получаются нули. Как же тогда можно восстановить этот синус?
Как известно из теоремы Котельникова, для того, чтобы аналоговый сигнал мог быть оцифрован а затем восстановлен, необходимо и достаточно, чтобы частота дискретизации была больше или равна удвоенной верхней частоте аналогого сигнала. Предположим, у нас есть синус с периодом 1 секунда. Тогда f = 1∕T = 1 герц, sin((2 ∗ π∕T) ∗ t) = sin(2 ∗ π ∗ t), частота дискретизации 2 герца, период дискретизации 0,5 секунды. Подставляем значения, кратные 0,5 секунды в формулу для синуса sin(2 ∗ π ∗ 0) = sin(2 ∗ π ∗ 0,5) = sin(2 ∗ π ∗ 1) = 0
Везде получаются нули. Как же тогда можно восстановить этот синус?
Вы можете развить свой интеллект: 5 способов максимально улучшить свои когнитивные способности
17 min
Translation

Не стоит преследовать цели, которые легко достичь. Стоит нацеливаться на то, что удается сделать с трудом, приложив немалые усилия — Альберт Эйнштейн
Несмотря на то, что Эйнштейн не был нейробиологом, он точно знал все, когда говорил о способности человека добиваться чего-либо. Он интуитивно догадывался о том, что лишь сегодня нам удалось подтвердить с помощью данных, а именно: что заставляет когнитивные способности работать на максимально высоком уровне. По существу: То, что тебя не убивает, делает тебя умнее.
Как устроено оповещение о чрезвычайных ситуациях
6 min

Масштабное наводнение на Дальнем Востоке стало темой №1 начала осени. Это уже второе катастрофическое наводнение за два года, если вспомнить Крымск. И как всегда в таких ситуациях возникает вопрос оповещения населения. «МегаФон» порой упрекают, что его тревожные SMS доходят не всем и не всегда — однако «есть нюанс», который заключается в том, что «МегаФон» — единственный оператор сотовой связи, занимающийся точечным оповещением населения в сотрудничестве с МЧС. Как устроено это сотрудничество, по какому принципу рассылаются сообщения, можно ли получить SMS о чрезвычайной ситуации с отрицательным балансом на счету, о каких происшествиях приходится оповещать чаще всего — я отправился выяснять в Федеральный центр управления и мониторинга (ФЦУМ) ОАО «МегаФон».
Я знаю, что ты знаешь, что я знаю, что ты знаешь…
3 min
Translation
Вольный перевод одного из ответов с mathoverflow. Ответ, в принципе, такой самодостаточный и интересный, что вполне может быть прочитан и без усвоения сути вопроса. Поэтому, если по каким-либо причинам вы застопорились на прочтении вопроса, я вам советую перейти сразу к ответу.
Иногда в жизни бывают ситуации, которые описываются предложениями типа: «я знаю, что ты знаешь, что я знаю… что-то». Представьте себе, что вы испекли вишневый пирог и положили его остывать на подоконнике, а я потом втихаря его съел. Приведем список все более и более сложных предложений, которые все ближе и ближе подводят нас к полному знанию о происходящем. Например,
 : «Я знаю, что вы испекли пирог и положили его остывать на подоконник; но вы не знаете, что я знаю». В таком случае, если я съем пирог, то об этом скорее всего никто и не узнает.
: «Я знаю, что вы испекли пирог и положили его остывать на подоконник; но вы не знаете, что я знаю». В таком случае, если я съем пирог, то об этом скорее всего никто и не узнает.
 : «Я знаю, что вы испекли пирог и положили его остывать на подоконник; вы знаете, что я знаю; но я не знаю, что вы знаете, что я знаю». Если я съем пирог, то это может привести к довольно к щекотливой ситуации для меня.
: «Я знаю, что вы испекли пирог и положили его остывать на подоконник; вы знаете, что я знаю; но я не знаю, что вы знаете, что я знаю». Если я съем пирог, то это может привести к довольно к щекотливой ситуации для меня.
 : «Я знаю, что вы испекли пирог и положили его остывать на подоконник; вы знаете, что я знаю; я знаю, что вы знаете, что я знаю; но вы не знаете, что я знаю. что вы знаете, что я знаю». В таком случае после того как я съем пирог у меня останется надежда вывернуть ситуацию так, что вы не узнаете о моем преступлении.
: «Я знаю, что вы испекли пирог и положили его остывать на подоконник; вы знаете, что я знаю; я знаю, что вы знаете, что я знаю; но вы не знаете, что я знаю. что вы знаете, что я знаю». В таком случае после того как я съем пирог у меня останется надежда вывернуть ситуацию так, что вы не узнаете о моем преступлении.
…
Для маленьких значений , я еще могу вообразить, как при переходе от предложения
, я еще могу вообразить, как при переходе от предложения  к
к  действительно меняется суть происходящего. Но я совершенно не могу вообразить, как, скажем, переход от
действительно меняется суть происходящего. Но я совершенно не могу вообразить, как, скажем, переход от  к
к  может повлиять на мою стратегию действий после того, как я съем пирог.
может повлиять на мою стратегию действий после того, как я съем пирог.
Есть ли какие-либо ситуации в жизни, будь-то реальные или искусственные, где переход от к  для больших значений может реально повлиять на стратегию действий? А что насчет
для больших значений может реально повлиять на стратегию действий? А что насчет  ? Как такие ситуации моделируются в математике?
? Как такие ситуации моделируются в математике?
Вопрос
Иногда в жизни бывают ситуации, которые описываются предложениями типа: «я знаю, что ты знаешь, что я знаю… что-то». Представьте себе, что вы испекли вишневый пирог и положили его остывать на подоконнике, а я потом втихаря его съел. Приведем список все более и более сложных предложений, которые все ближе и ближе подводят нас к полному знанию о происходящем. Например,
: «Я знаю, что вы испекли пирог и положили его остывать на подоконник; но вы не знаете, что я знаю». В таком случае, если я съем пирог, то об этом скорее всего никто и не узнает. : «Я знаю, что вы испекли пирог и положили его остывать на подоконник; вы знаете, что я знаю; но я не знаю, что вы знаете, что я знаю». Если я съем пирог, то это может привести к довольно к щекотливой ситуации для меня.: «Я знаю, что вы испекли пирог и положили его остывать на подоконник; вы знаете, что я знаю; я знаю, что вы знаете, что я знаю; но вы не знаете, что я знаю. что вы знаете, что я знаю». В таком случае после того как я съем пирог у меня останется надежда вывернуть ситуацию так, что вы не узнаете о моем преступлении.…
Для маленьких значений
, я еще могу вообразить, как при переходе от предложения к действительно меняется суть происходящего. Но я совершенно не могу вообразить, как, скажем, переход от к может повлиять на мою стратегию действий после того, как я съем пирог.Есть ли какие-либо ситуации в жизни, будь-то реальные или искусственные, где переход от
к для больших значений может реально повлиять на стратегию действий? А что насчет ? Как такие ситуации моделируются в математике?Lock-free структуры данных. Основы: Атомарность и атомарные примитивы
15 min

Построение lock-free структур данных зиждется на двух китах – атомарных операциях и способах упорядочения доступа к памяти. В этой статье речь пойдет об атомарности и атомарных примитивах.
Анонс. Спасибо за теплый прием Начал! Вижу, что тема lock-free интересна хабрасообществу, это меня радует. Я планировал построить цикл по академическому принципу, плавно переходя от основ к алгоритмам, попутно иллюстрируя текст кодом из libcds. Но часть читателей требует
А пока я судорожно готовлю начало Извне, — первая часть Основ. Статья во многом не о C++ (хотя и о нем тоже) и даже не о lock-free (хотя без atomic lock-free алгоритмы неработоспособны), а о реализации атомарных примитивов в современных процессорах и о базовых проблемах, возникающих при использовании таких примитивов.
Атомарность — это первый
Введение в анализ сложности алгоритмов (часть 3)
6 min
Tutorial
Translation
От переводчика: данный текст даётся с незначительными сокращениями по причине местами излишней «разжёванности» материала. Автор абсолютно справедливо предупреждает, что отдельные темы могут показаться читателю чересчур простыми или общеизвестными. Тем не менее, лично мне этот текст помог упорядочить имеющиеся знания по анализу сложности алгоритмов. Надеюсь, что он окажется полезен и кому-то ещё.
Из-за большого объёма оригинальной статьи я разбила её на части, которых в общей сложности будет четыре.
Я (как всегда) буду крайне признательна за любые замечания в личку по улучшению качества перевода.
Опубликовано ранее:
Часть 1
Часть 2

Если вы знаете, что такое логарифмы, то можете спокойно пропустить этот раздел. Глава предназначается тем, кто незнаком с данным понятием или пользуется им настолько редко, что уже забыл что там к чему. Логарифмы важны, поскольку они очень часто встречаются при анализе сложности. Логарифм — это операция, которая при применении её к числу делает его гораздо меньше (подобно взятию квадратного корня). Итак, первая вещь, которую вы должны запомнить: логарифм возвращает число, меньшее, чем оригинал. На рисунке справа зелёный график — линейная функция
Из-за большого объёма оригинальной статьи я разбила её на части, которых в общей сложности будет четыре.
Я (как всегда) буду крайне признательна за любые замечания в личку по улучшению качества перевода.
Опубликовано ранее:
Часть 1
Часть 2
Логарифмы
Если вы знаете, что такое логарифмы, то можете спокойно пропустить этот раздел. Глава предназначается тем, кто незнаком с данным понятием или пользуется им настолько редко, что уже забыл что там к чему. Логарифмы важны, поскольку они очень часто встречаются при анализе сложности. Логарифм — это операция, которая при применении её к числу делает его гораздо меньше (подобно взятию квадратного корня). Итак, первая вещь, которую вы должны запомнить: логарифм возвращает число, меньшее, чем оригинал. На рисунке справа зелёный график — линейная функция
f(n) = n, красный — f(n) = sqrt(n), а наименее быстро возрастающий — f(n) = log(n). Далее: подобно тому, как взятие квадратного корня является операцией, обратной возведению в квадрат, логарифм — обратная операция возведению чего-либо в степень. Аппаратная виртуализация. Теория, реальность и поддержка в архитектурах процессоров
23 min
Tutorial
В данном посте я попытаюсь описать основания и особенности использования аппаратной поддержки виртуализации компьютеров. Начну с определения трёх необходимых условий виртуализации и формулировки теоретических оснований для их достижения. Затем перейду к описанию того, какое отражение теория находит в суровой реальности. В качестве иллюстраций будет кратко описано, как различные вендоры процессоров различных архитектур реализовали виртуализацию в своей продукции. В конце будет затронут вопрос рекурсивной виртуализации.