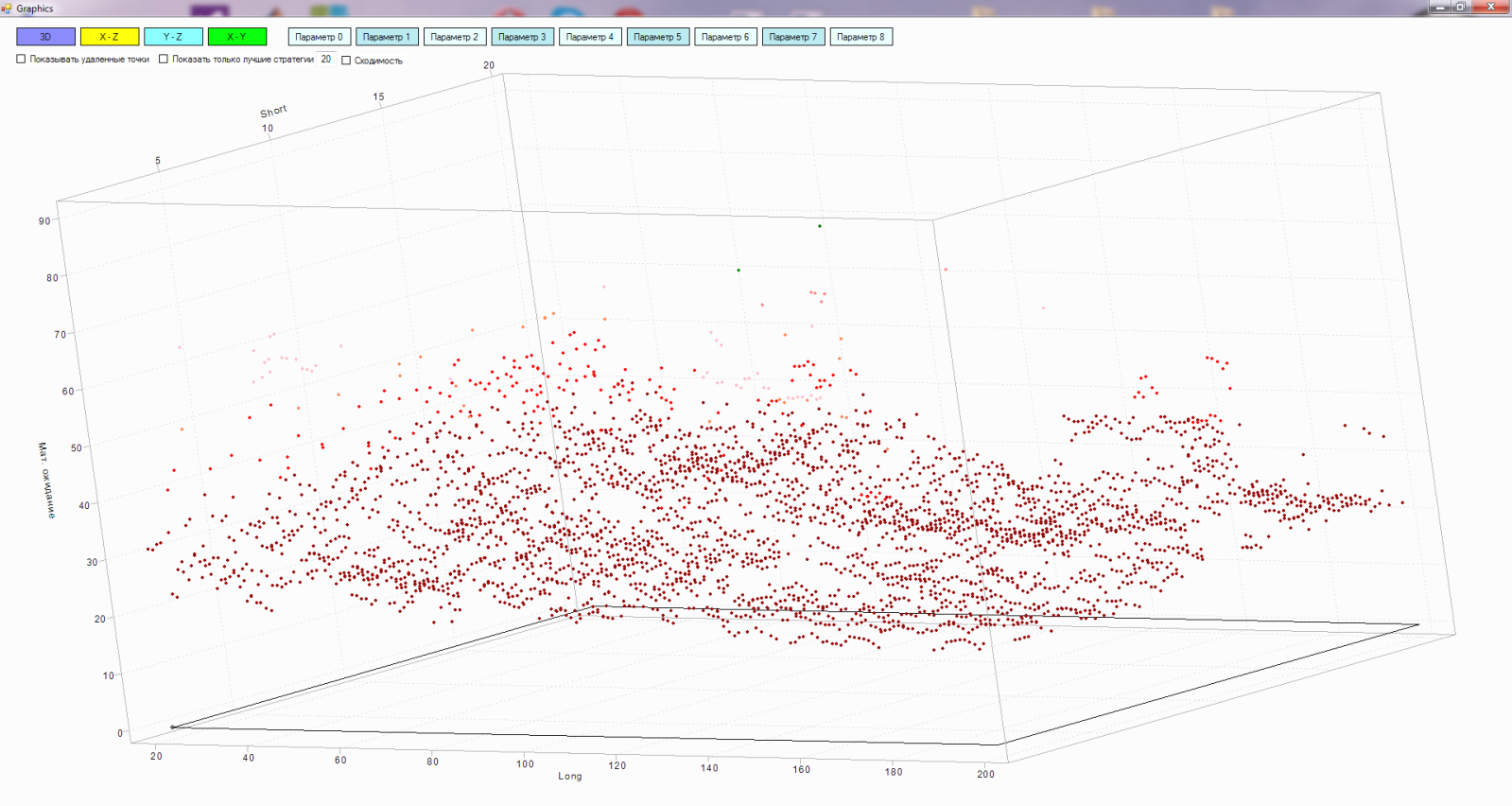
Через серию статей попробую разобрать движок на webgl.
Основным требованием будет минимальный ввод данных. Ведь, грубо говоря, движок — это модель, созданная для упрощения задачи. Материал рассчитан на начинающий уровень, для тех, кто прочитал основы webgl и хочет попробовать начать работать. Таких как я.
Необходимо создать классы объектов (примитивы), которые из себя представляют набор точек. При этом примитивы должны быть независимы друг от друга. Каждый примитив можно перемещать, поворачивать вокруг центра или вокруг произвольной точки.
Необходимо создать механизм обрисовки этих объектов.
И напоследок необходимо создать что то вроде карты на которой можно установить наши объекты и по которой можно свободно перемещаться.
Основным требованием будет минимальный ввод данных. Ведь, грубо говоря, движок — это модель, созданная для упрощения задачи. Материал рассчитан на начинающий уровень, для тех, кто прочитал основы webgl и хочет попробовать начать работать. Таких как я.
Первое. Описание задачи на пальцах
Необходимо создать классы объектов (примитивы), которые из себя представляют набор точек. При этом примитивы должны быть независимы друг от друга. Каждый примитив можно перемещать, поворачивать вокруг центра или вокруг произвольной точки.
Необходимо создать механизм обрисовки этих объектов.
И напоследок необходимо создать что то вроде карты на которой можно установить наши объекты и по которой можно свободно перемещаться.


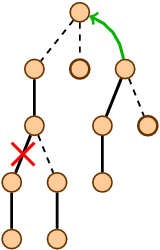 Динамические деревья (link/cut trees) мало освещены в русскоязычном интернете. Я нашел только краткое описание на алголисте. Тем не менее эта структура данных очень интересна. Она находится на стыке двух областей: потоки и динамические графы.
Динамические деревья (link/cut trees) мало освещены в русскоязычном интернете. Я нашел только краткое описание на алголисте. Тем не менее эта структура данных очень интересна. Она находится на стыке двух областей: потоки и динамические графы. 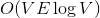 и
и 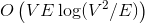 соответственно. Если вы не знаете, что такое поток, и на лекциях у вас такого не было, спешите пополнить свои знания в Кормене.
соответственно. Если вы не знаете, что такое поток, и на лекциях у вас такого не было, спешите пополнить свои знания в Кормене.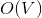 памяти и
памяти и 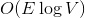 времени. По прочтении статьи вы поймете, как легко и просто можно решить эту задачу, используя динамические деревья.
времени. По прочтении статьи вы поймете, как легко и просто можно решить эту задачу, используя динамические деревья.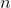 ключах и теперь нам нужно отвечать на запросы, лежит ли заданный ключ в дереве. Может так оказаться, что пользователя интересует в основном один ключ, и остальные он запрашивает только время от времени. Если ключ лежит далеко от корня, то
ключах и теперь нам нужно отвечать на запросы, лежит ли заданный ключ в дереве. Может так оказаться, что пользователя интересует в основном один ключ, и остальные он запрашивает только время от времени. Если ключ лежит далеко от корня, то  запросов могут отнять
запросов могут отнять 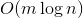 времени. Здравый смысл подсказывает, что оценку можно оптимизировать до
времени. Здравый смысл подсказывает, что оценку можно оптимизировать до 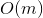 , надстроив над деревом кэш. Но этот подход имеет некоторый недостаток гибкости и элегантности.
, надстроив над деревом кэш. Но этот подход имеет некоторый недостаток гибкости и элегантности. , что делает splay-деревья хорошей альтернативой для перманентно сбалансированных собратьев.
, что делает splay-деревья хорошей альтернативой для перманентно сбалансированных собратьев.