Оглавление
Часть 1 — линейная регрессия
Часть 2 — градиентный спуск
Часть 3 — градиентный спуск продолжение
Введение
Этим постом я начну цикл «Нейронные сети для новичков». Он посвящен искусственным нейронным сетям (внезапно). Целью цикла является объяснение данной математической модели. Часто после прочтения подобных статей у меня оставалось чувство недосказанности, недопонимания — НС по-прежнему оставались «черным ящиком» — в общих чертах известно, как они устроены, известно, что делают, известны входные и выходные данные. Но тем не менее полное, всестороннее понимание отсутствует. А современные библиотеки с очень приятными и удобными абстракциями только усиливают ощущение «черного ящика». Не могу сказать, что это однозначно плохо, но и разобраться в используемых инструментах тоже никогда не поздно. Поэтому моей первичной целью является подробное объяснение устройства нейронных сетей так, чтобы абсолютно ни у кого не осталось вопросов об их устройстве; так, чтобы НС не казались волшебством. Так как это не математический трактат, я ограничусь описанием нескольких методов простым языком (но не исключая формул, конечно же), предоставляя поясняющие иллюстрации и примеры.
Цикл рассчитан на базовый ВУЗовский математический уровень читающего. Код будет написан на Python3.5 с numpy 1.11. Список остальных вспомогательных библиотек будет в конце каждого поста. Абсолютно все будет написано с нуля. В качестве подопытного выбрана база MNIST — это черно-белые, центрированные изображения рукописных цифр размером 28*28 пикселей. По-умолчанию, 60000 изображений отмечены для обучения, а 10000 для тестирования. В примерах я не буду изменять распределения по-умолчанию.











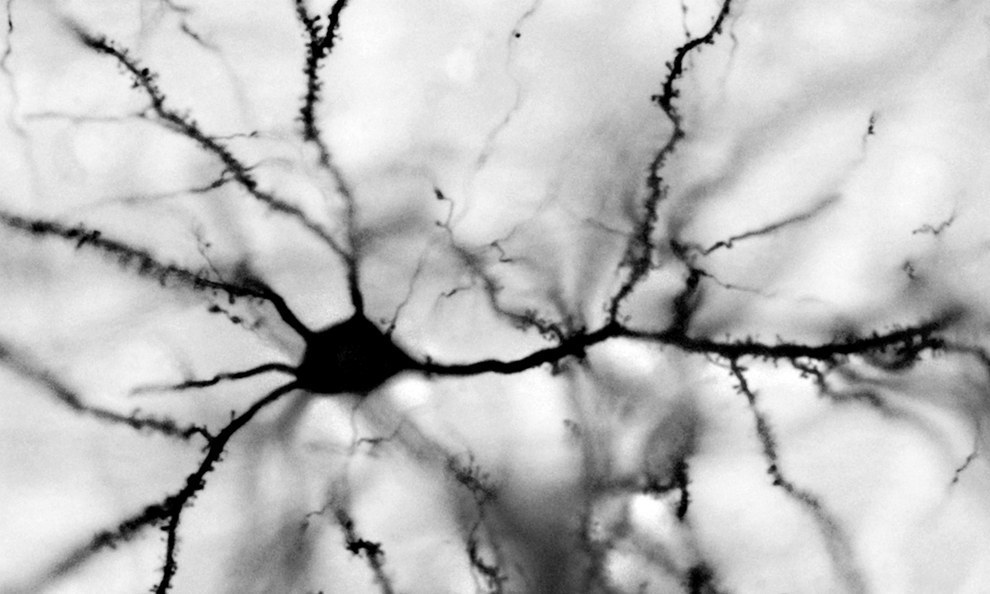 В предыдущей части мы показали, что в клеточном автомате могут возникать волны, имеющие специфический внутренний узор. Такие волны могут запускаться из любого места клеточного автомата и распространяться по всему пространству клеток автомата, перенося информацию. Соблазнительно предположить, что реальный мозг может использовать схожие принципы. Чтобы понять возможность аналогии, немного разберемся с тем, как работают нейроны реального мозга.
В предыдущей части мы показали, что в клеточном автомате могут возникать волны, имеющие специфический внутренний узор. Такие волны могут запускаться из любого места клеточного автомата и распространяться по всему пространству клеток автомата, перенося информацию. Соблазнительно предположить, что реальный мозг может использовать схожие принципы. Чтобы понять возможность аналогии, немного разберемся с тем, как работают нейроны реального мозга.