
Предположим, я заказываю буррито для двоих друзей и хочу рассчитать общую стоимость заказа:

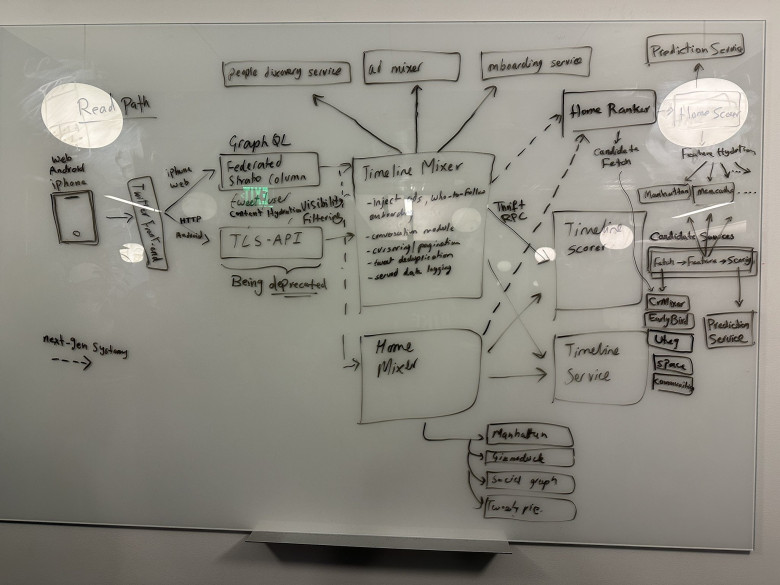
Поток данных в этой таблице немного сложно проследить, поэтому вот эквивалентная диаграмма, которая представляет таблицу в виде графа:

Округляем стоимость буррито El Farolito super vegi до 8 долларов, поэтому при доставке стоимостью 2 доллара общая сумма составит 20 долларов.
Поток данных в этой таблице немного сложно проследить, поэтому вот эквивалентная диаграмма, которая представляет таблицу в виде графа:
Округляем стоимость буррито El Farolito super vegi до 8 долларов, поэтому при доставке стоимостью 2 доллара общая сумма составит 20 долларов.













{kind=link}