
При использовании библиотеки pandas для анализа маленьких наборов данных, размер которых не превышает 100 мегабайт, производительность редко становится проблемой. Но когда речь идёт об исследовании наборов данных, размеры которых могут достигать нескольких гигабайт, проблемы с производительностью могут приводить к значительному увеличению длительности анализа данных и даже могут становиться причиной невозможности проведения анализа из-за нехватки памяти.
В то время как инструменты наподобие Spark могут эффективно обрабатывать большие наборы данных (от сотен гигабайт до нескольких терабайт), для того чтобы полноценно пользоваться их возможностями обычно нужно достаточно мощное и дорогое аппаратное обеспечение. И, в сравнении с pandas, они не отличаются богатыми наборами средств для качественного проведения очистки, исследования и анализа данных. Для наборов данных средних размеров лучше всего попытаться более эффективно использовать pandas, а не переходить на другие инструменты.

В материале, перевод которого мы публикуем сегодня, мы поговорим об особенностях работы с памятью при использовании pandas, и о том, как, просто подбирая подходящие типы данных, хранящихся в столбцах табличных структур данных
В то время как инструменты наподобие Spark могут эффективно обрабатывать большие наборы данных (от сотен гигабайт до нескольких терабайт), для того чтобы полноценно пользоваться их возможностями обычно нужно достаточно мощное и дорогое аппаратное обеспечение. И, в сравнении с pandas, они не отличаются богатыми наборами средств для качественного проведения очистки, исследования и анализа данных. Для наборов данных средних размеров лучше всего попытаться более эффективно использовать pandas, а не переходить на другие инструменты.
В материале, перевод которого мы публикуем сегодня, мы поговорим об особенностях работы с памятью при использовании pandas, и о том, как, просто подбирая подходящие типы данных, хранящихся в столбцах табличных структур данных
DataFrame, снизить потребление памяти почти на 90%.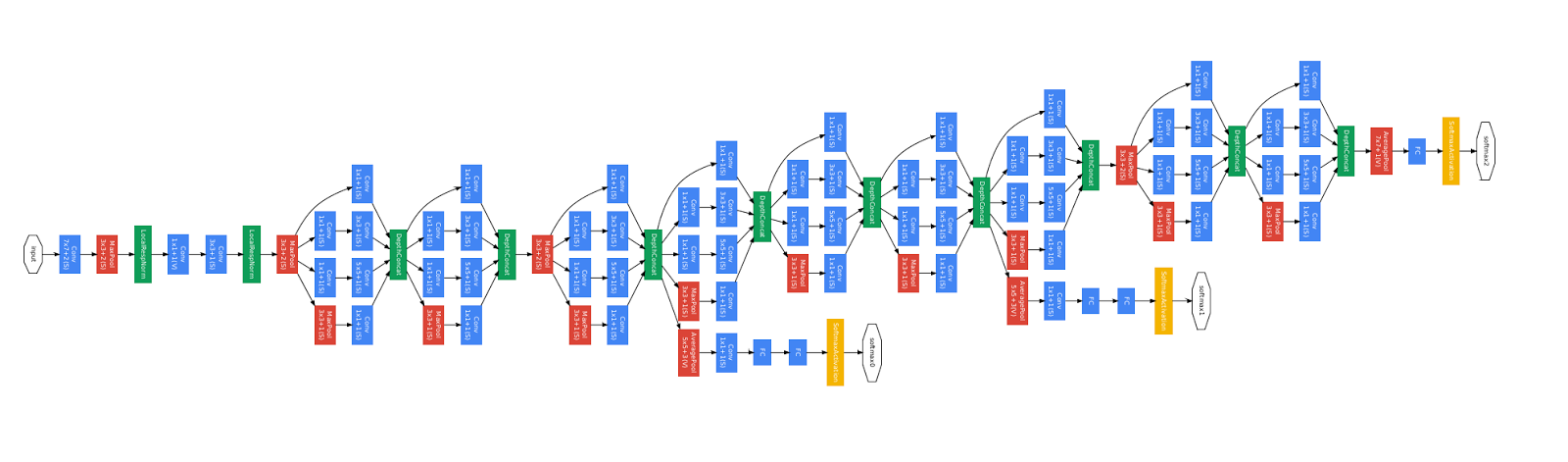




 CMake — кроcсплатформенная утилита для автоматической сборки программы из исходного кода. При этом сама CMake непосредственно сборкой не занимается, а представляет из себя front-end. В качестве back-end`a могут выступать различные версии make и Ninja. Так же CMake позволяет создавать проекты для CodeBlocks, Eclipse, KDevelop3, MS VC++ и Xcode. Стоит отметить, что большинство проектов создаются не нативных, а всё с теми же back-end`ами.
CMake — кроcсплатформенная утилита для автоматической сборки программы из исходного кода. При этом сама CMake непосредственно сборкой не занимается, а представляет из себя front-end. В качестве back-end`a могут выступать различные версии make и Ninja. Так же CMake позволяет создавать проекты для CodeBlocks, Eclipse, KDevelop3, MS VC++ и Xcode. Стоит отметить, что большинство проектов создаются не нативных, а всё с теми же back-end`ами.


{kind=link}