Предвидя комментарии бывалых по поводу этой статьи, что все из написанного давно уже известно, и ничего нового в ней не сказано, спешу сказать, что это не абстрактная статья о том, каковы стандартные приемы и методы продвижения на мобильном рынке. Статья о том, как мы использовали эти методы, и какие результаты получили в итоге. Все это сопровождается реальными цифрами и графиками. Мы готовы поделиться такой информацией. Думаю, даже бывалым будет интересно почитать и сравнить со своим опытом, и, возможно, даже обсудить его в комментариях к статье.
История такова, что наша команда программистов в связи с отсутствием перспективы в основном направлении разработки из-за достаточного количества больших конкурентов (.NET компоненты для репортинга и визуализации данных) решила пойти совершенно в другую сторону — разработку мобильных приложений. Благо, есть инструменты, позволяющие использовать предыдущий накопленный опыт разработки, а не начинать с нуля.
Чего не скажешь об отделе маркетинга и продвижении мобильных приложений. Продвижение компонентов для разработчиков, несомненно, отличается от маркетинга мобильных приложений.
Флагманским продуктом в этом направлении стало приложение для создания и управления базами данных для Android устройств.
Все статьи, прочитанные на эту тему (а их было немало), англо- и русскоязычные, в один голос утверждали, что необходимо в первые дни после публикации (1-3 дня) нагнать как можно больше посетителей на вашу страничку в магазине и заставить посетителей установить приложение. Приложение, показавшее быстрый рост в первые дни после публикации, привлекает внимание издателей, и есть шанс, что оно попадет в список Featured Apps в своей категории или даже в целом в магазине, что несомненно принесет еще больше пользователей и, как следствие, прибыли (вы же для этого разрабатывали свое мобильное приложение). Такая стратегия была оправдана, когда приложений в магазине было не так много и новые появлялись не со скоростью света.
Результат такого подхода выглядит примерно так:
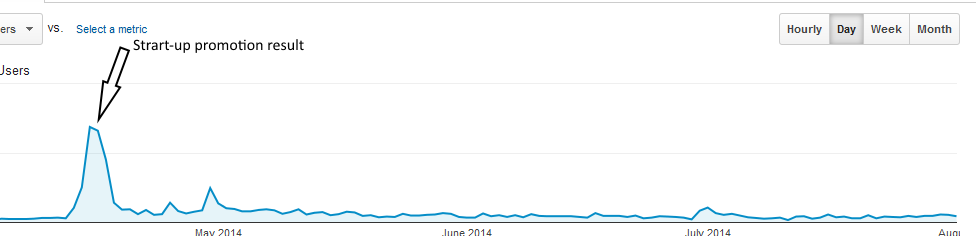
Эффект кратковременный, и если за 3 дня вы не попали в желаемый список Featured apps, считайте, что усилия и затраты не оправдались. Количество установок неминуемо снизится в разы.
Хочу рассказать о способах продвижения, о которых мы узнали из статей, и о том, как они работают и работают ли.



 Частой темой среди Go программистов, особенно тех, которые только познакомились с языком, является вопрос о том, как обрабатывать ошибки. Разговор часто сводится к жалобам на то, что последовательность
Частой темой среди Go программистов, особенно тех, которые только познакомились с языком, является вопрос о том, как обрабатывать ошибки. Разговор часто сводится к жалобам на то, что последовательность


 В мире все примерно распределяется в соответствии с принципом Паретто. Меньшая часть — богатые, большая часть — бедные (читающий, ты входишь в золотой миллиард). Тоже касается и материалов о программировании. Порой очень сложно найти хоть что-нибудь не начального уровня.
В мире все примерно распределяется в соответствии с принципом Паретто. Меньшая часть — богатые, большая часть — бедные (читающий, ты входишь в золотой миллиард). Тоже касается и материалов о программировании. Порой очень сложно найти хоть что-нибудь не начального уровня.