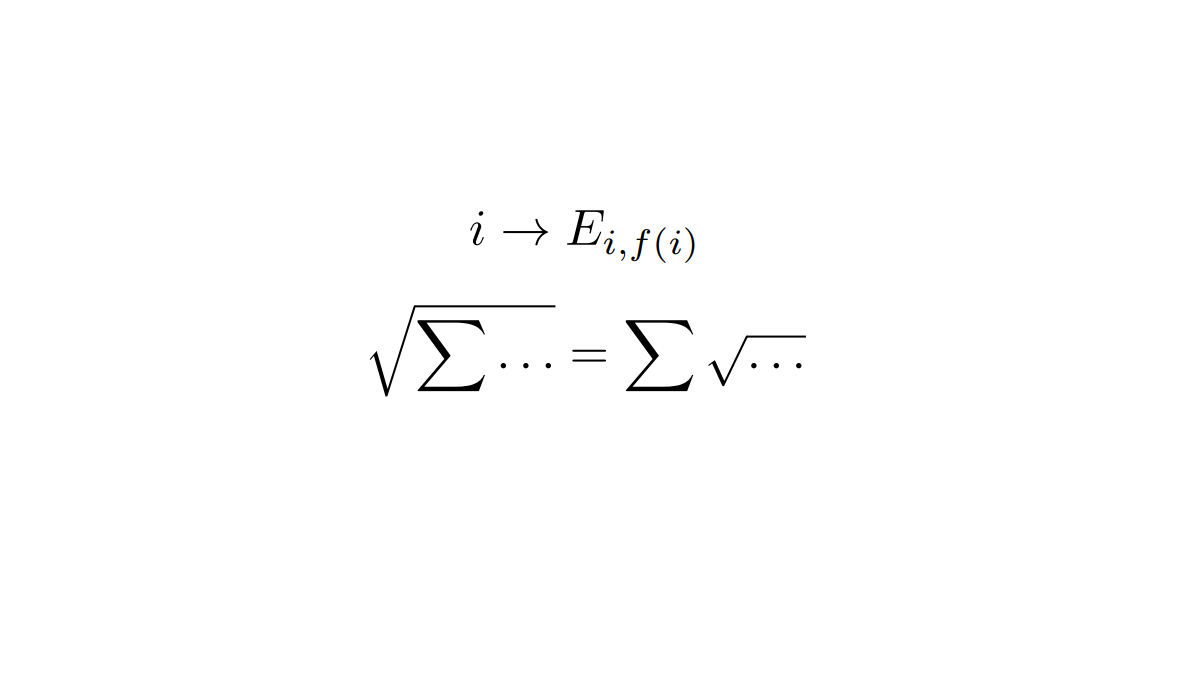Можно ли найти конкретного человека, жившего в XVII веке? Выражаясь современным языком «пробить по базам». Оказывается, архивные документы хранят массу информации об обычных людях того периода. Однако существует ряд сложностей, не позволяющих обычному исследователю добраться до этой информации. Во-первых, нужно пройти определённую процедуру по получению доступа в архив. Во-вторых, не всегда можно выйти на нужный документ, используя так называемый научно-справочный аппарат – различные описи и реестры документов, имеющиеся в архиве. Наконец, не имея навыков чтения документов XVII века, которые написаны скорописью, почти нереально ознакомиться с его содержанием.
Данные проблемы предполагается решить с помощью создания базы данных служилых людей XVII века. Об этом небольшая история.
Как всё начиналось.
Привет! Меня зовут Дмитрий и вот уже более 10 лет я изучаю историю южных уездов России XVII века. Территориально – это современные Белгородская, а также соседние Воронежская, Курская, Липецкая и другие области. Населены они были тогда так называемыми служилыми людьми – они получали здесь в качестве служебного жалования земельные наделы, которые сами и обрабатывали. В XVIII веке их потомки стали однодворцами, а затем государственными крестьянами. Большая часть населения Курской, Воронежской и соседних губерний XIX века происходят из тех самых служилых людей XVI–XVII веков.