Как известно, для обработки соединений NGINX использует асинхронный событийный подход. Вместо того, чтобы выделять на каждый запрос отдельный поток или процесс (как это делают серверы с традиционной архитектурой), NGINX мультиплексирует обработку множества соединений и запросов в одном рабочем процессе. Для этого применяются сокеты в неблокирующем режиме и такие эффективные методы работы с событиями, как epoll и kqueue.
За счет малого и постоянного количества полновесных потоков обработки (обычно по одному на ядро) достигается экономия памяти, а также ресурсов процессора на переключении контекстов. Все преимущества данного подхода вы можете хорошо наблюдать на примере самого NGINX, который способен обрабатывать миллионы запросов одновременно и хорошо масштабироваться.
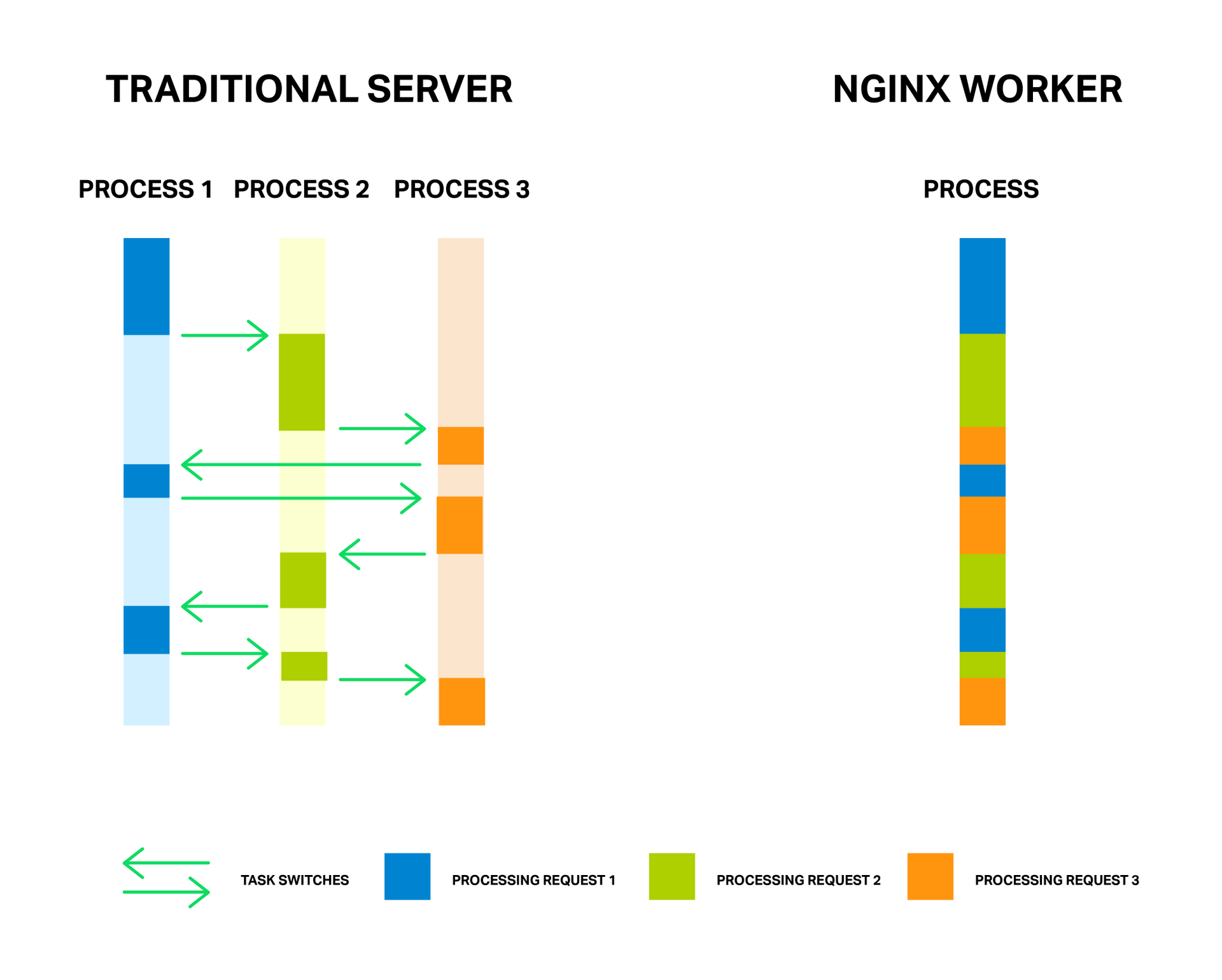 Каждый процесс расходует память и каждое переключение между ними требует дополнительных циклов процессора, а также приводит к вымыванию L-кэшей
Каждый процесс расходует память и каждое переключение между ними требует дополнительных циклов процессора, а также приводит к вымыванию L-кэшей
У медали есть и обратная сторона. Главной проблемой асинхронного подхода, а лучше даже сказать «врагом» — являются блокирующие операции. И, к сожалению, многие авторы сторонних модулей, не понимая принципов функционирования NGINX, пытаются выполнять блокирующие операции в своих модулях. Такие операции способны полностью убить производительность NGINX и их следует избегать любой ценой.
Но даже в текущей реализации NGINX не всегда возможно избежать блокировок. И для решения данной проблемы в NGINX версии 1.7.11 был представлен новый механизм «пулов потоков». Что это такое и как его применять разберем далее, а для начала познакомимся с нашим врагом в лицо.
За счет малого и постоянного количества полновесных потоков обработки (обычно по одному на ядро) достигается экономия памяти, а также ресурсов процессора на переключении контекстов. Все преимущества данного подхода вы можете хорошо наблюдать на примере самого NGINX, который способен обрабатывать миллионы запросов одновременно и хорошо масштабироваться.
У медали есть и обратная сторона. Главной проблемой асинхронного подхода, а лучше даже сказать «врагом» — являются блокирующие операции. И, к сожалению, многие авторы сторонних модулей, не понимая принципов функционирования NGINX, пытаются выполнять блокирующие операции в своих модулях. Такие операции способны полностью убить производительность NGINX и их следует избегать любой ценой.
Но даже в текущей реализации NGINX не всегда возможно избежать блокировок. И для решения данной проблемы в NGINX версии 1.7.11 был представлен новый механизм «пулов потоков». Что это такое и как его применять разберем далее, а для начала познакомимся с нашим врагом в лицо.
 Привет, Хабр!
Привет, Хабр!