Реализация физически корректных объемных облаков как в игре Horizon Zero Dawn
16 min
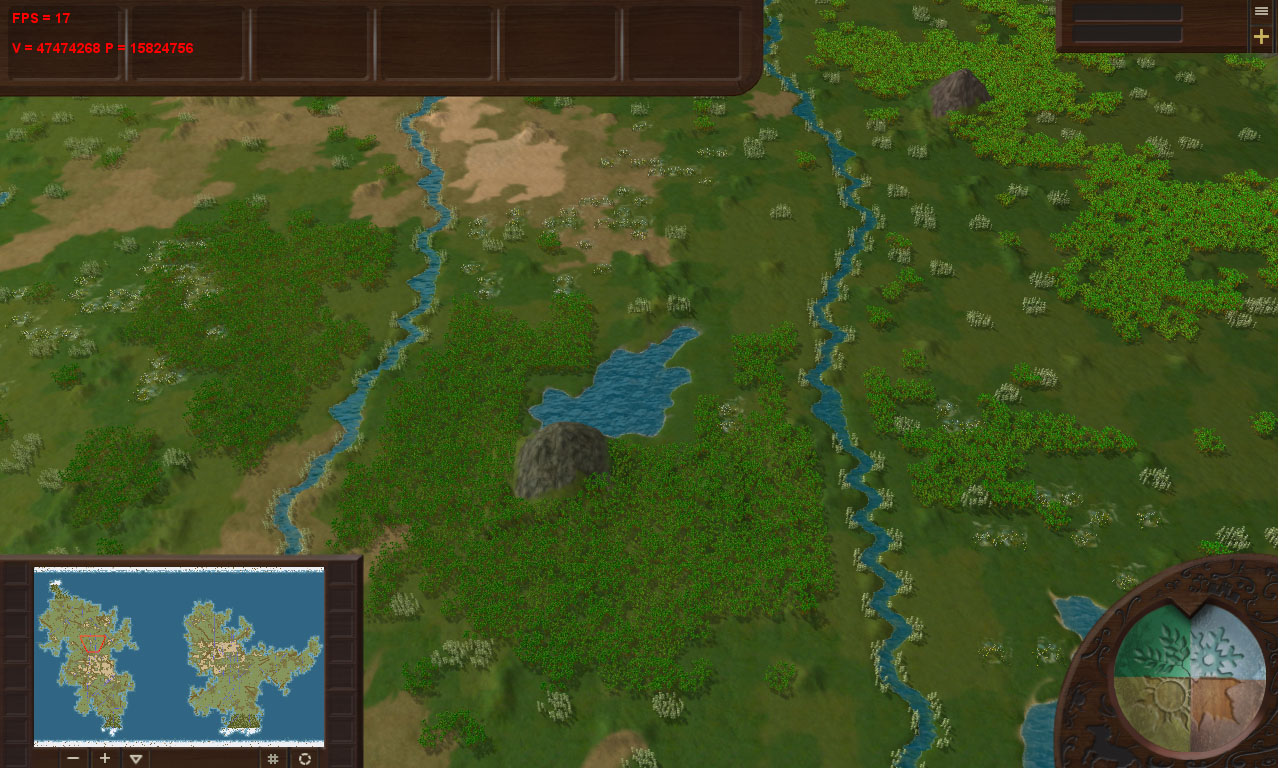
Раньше облака в играх рисовались обычными 2D спрайтами, которые всегда повернуты в направлении камеры, но последние годы новые модели видеокарт позволяют рисовать физически корректные облака без заметных потерь в производительности. Считается, что объемные облака в игры принесла студия Guerrilla Games вместе с игрой Horizon Zero Dawn. Конечно, такие облака умели рендерить и раньше, но студия сформировала что-то вроде промышленного стандарта на исходные ресурсы и используемые алгоритмы, и в настоящее время любая реализация объемных облаков так или иначе этому стандарту соответствует.
UPD. Картинка обновлена. Изменения описаны в конце статьи.

UPD. Картинка обновлена. Изменения описаны в конце статьи.