
Быстрая, экономная, устойчивая…
10 мин
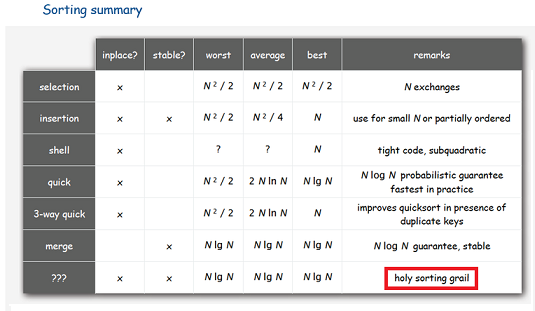
Если вам понадобится алгоритм сортировки массива, который:
- Работал бы гарантированно за O(N*log(N)) операций (обменов и сравнений);
- Требовал бы O(1) дополнительной памяти;
- Был бы устойчивым (то есть, не менял порядок элементов с одинаковыми ключами)
то вам, скорее всего, предложат ограничиться любыми двумя из этих трёх пунктов. И, в зависимости от вашего выбора, вы получите, например, либо сортировку слиянием (требует O(N) дополнительной памяти), либо пирамидальную сортировку (неустойчив), либо сортировку пузырьком (работает за O(N2)). Если вы ослабите требование на память до O(log(N)) («на рекурсию»), то для вас найдётся алгоритм со сложностью O(N*(log(N)2) — довольно малоизвестный, хотя именно его версия используется в реализации метода std::stable_sort().
На вопрос, можно ли добиться выполнения одновременно всех трёх условий, большинство скажет «вряд ли». Википедия о таких алгоритмах не знает. Среди программистов ходят слухи, что вроде бы, что-то такое существует. Некоторые говорят, что есть «устойчивая быстрая сортировка» — но у той реализации, которую я видел, сложность была всё те же O(N*(log(N)2) (по таймеру). И только в одном обсуждении на StackOverflow дали ссылку на статью B-C. Huang и M. A. Langston, Fast Stable Merging and Sorting in Constant Extra Space (1989-1992), в которой описан алгоритм со всеми тремя свойствами.



 Теперь статей и проектов стало больше — включены новости с pycoders, pythonplanet и по-прежнему мониторятся новые пакеты и релизы уже популярных проектов на PyPI и github.
Теперь статей и проектов стало больше — включены новости с pycoders, pythonplanet и по-прежнему мониторятся новые пакеты и релизы уже популярных проектов на PyPI и github. Лет семь назад попал в руки крякеров архив с сорцом генератора ключей для протектора под названием Armadillo. Просто кое-кому из благодарных пользователей продукта захотелось проверить его на прочность. А где еще получишь бесплатный аудит такого интересного кода, как не на крякерском форуме.
Лет семь назад попал в руки крякеров архив с сорцом генератора ключей для протектора под названием Armadillo. Просто кое-кому из благодарных пользователей продукта захотелось проверить его на прочность. А где еще получишь бесплатный аудит такого интересного кода, как не на крякерском форуме.






