Праздничная неделя подходит к концу, но мы продолжаем публиковать лекции от Школы анализа данных Яндекса для тех, кто хочет провести время с пользой. Сегодня очередь курса, важность которого в наше время сложно переоценить – «Параллельные и распределенные вычисления».
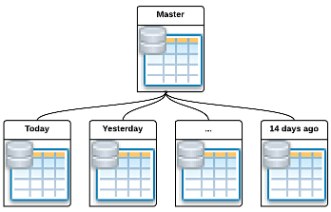
Что внутри: знакомство с параллельными вычислениями и распределёнными системами обработки и хранения данных, а также выработка навыков практического использования соответствующих технологий. Курс состоит из четырех основных блоков: concurrence, параллельные вычисления, параллельная обработка больших массивов данных и распределенные вычисления.
Лекции читает Олег Викторович Сухорослов, старший научный сотрудник Центра грид-технологий и распределенных вычислений ИСА РАН. Доцент кафедры распределенных вычислений ФИВТ МФТИ. Кандидат технических наук.
Что внутри: знакомство с параллельными вычислениями и распределёнными системами обработки и хранения данных, а также выработка навыков практического использования соответствующих технологий. Курс состоит из четырех основных блоков: concurrence, параллельные вычисления, параллельная обработка больших массивов данных и распределенные вычисления.
Лекции читает Олег Викторович Сухорослов, старший научный сотрудник Центра грид-технологий и распределенных вычислений ИСА РАН. Доцент кафедры распределенных вычислений ФИВТ МФТИ. Кандидат технических наук.
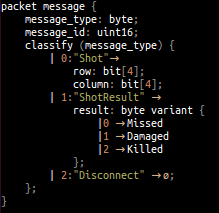 Всем программистам рано или поздно приходится передавать данные. Ни для кого не секрет, что библиотек сериализации в Java существует примерно >9000, а в C++ они вроде и есть, а вроде их и нет. К счастью для большинства, несколько лет назад появился Google Protobuf, который принёс достаточно удобный способ определять структуры данных и быстро завоевал всенародную любовь. Это была фактически первая, доступная широким массам библиотека, позволяющая гонять по сети готовые структуры данных, не связываясь при этом с чем-то вроде XML. На дворе был 2008 год.
Всем программистам рано или поздно приходится передавать данные. Ни для кого не секрет, что библиотек сериализации в Java существует примерно >9000, а в C++ они вроде и есть, а вроде их и нет. К счастью для большинства, несколько лет назад появился Google Protobuf, который принёс достаточно удобный способ определять структуры данных и быстро завоевал всенародную любовь. Это была фактически первая, доступная широким массам библиотека, позволяющая гонять по сети готовые структуры данных, не связываясь при этом с чем-то вроде XML. На дворе был 2008 год.