
За последнее время, наш сайт часто подвергается достаточно мощным DDOS атакам, к слову последняя атака была самой крупной за последнее время, размер ботнета по нашим оценкам — около 10 тысяч машин, мощность — 100 Mbits/s.
Атаку заметила даже Лаборатория Касперского, и предложила свою помощь в отражении, за что им спасибо. Правда к тому времени мы самостоятельно нашли решение, которое блокирует атаку. Собственно про это решение и пойдет речь.
Все началось в прошлую пятницу в пять часов вечера, и продолжалось до обеда в понедельник. Выходные прошли, за увлекательным занятием по отстрелу ботов. Пришлось немного попотеть, пока нашлось рабочее решение для противодействия атаке.
Атака была типа HTTP Flood. Система на которой у нас работает сайт — Apache под Linux. Мы написали несколько скриптов, которые будут приведены в тексте статьи. В принципе аналогичный подход можно применять и для Windows/IIS.
Попытаюсь рассказать, какие основные шаги мы сделали для отражения атаки, и какие проблемы возникали по ходу:
Атаку заметила даже Лаборатория Касперского, и предложила свою помощь в отражении, за что им спасибо. Правда к тому времени мы самостоятельно нашли решение, которое блокирует атаку. Собственно про это решение и пойдет речь.
Все началось в прошлую пятницу в пять часов вечера, и продолжалось до обеда в понедельник. Выходные прошли, за увлекательным занятием по отстрелу ботов. Пришлось немного попотеть, пока нашлось рабочее решение для противодействия атаке.
Атака была типа HTTP Flood. Система на которой у нас работает сайт — Apache под Linux. Мы написали несколько скриптов, которые будут приведены в тексте статьи. В принципе аналогичный подход можно применять и для Windows/IIS.
Попытаюсь рассказать, какие основные шаги мы сделали для отражения атаки, и какие проблемы возникали по ходу:


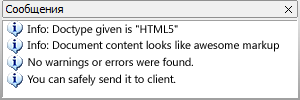 Вы PM. Как узнать – готова ли вёрстка к реальному использованию?
Вы PM. Как узнать – готова ли вёрстка к реальному использованию?