В этой публикации речь пойдет о синтетических модулях и символах отладочного движка Windows (debugger engine). То есть о сущностях, которые можно искусственно добавить в отладчик для раскраски адресов памяти.


User
В этой публикации речь пойдет о синтетических модулях и символах отладочного движка Windows (debugger engine). То есть о сущностях, которые можно искусственно добавить в отладчик для раскраски адресов памяти.

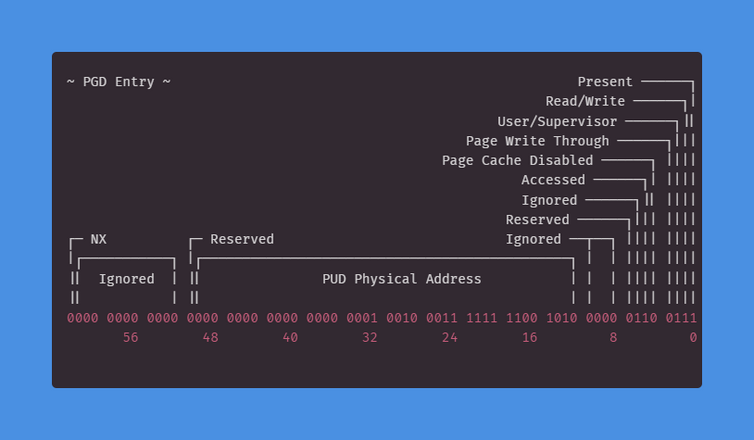
В этом посте я буду говорить о страничной организации только в контексте PML4 (Page Map Level 4), потому что на данный момент это доминирующая схема страничной организации x86_64 и, вероятно, останется таковой какое-то время.
Окружение
Это необязательно, но я рекомендую подготовить систему для отладки ядра Linux с QEMU + gdb. Если вы никогда этого не делали, то попробуйте такой репозиторий: easylkb (сам я им никогда не пользовался, но слышал о нём много хорошего), а если не хотите настраивать окружение самостоятельно, то подойдёт режим практики в любом из заданий по Kernel Security на pwn.college (вам нужно знать команды vm connect и vm debug).
Я рекомендую вам так поступить, потому что считаю, что самостоятельное выполнение команд вместе со мной и возможность просмотра страниц (page walk) на основании увиденного в gdb — хорошая проверка понимания.

Если у вас есть большая система, состоящая из множества микросервисов, то вы наверняка задавались вопросом: «Что сделать, чтобы архитектурная схема всей системы была всегда на 100% актуальной?».
Обычно, в компаниях есть свои практики формирования архитектурных схем и ведения документации, что частично решает поставленный вопрос. Но проблема такова, что часто схемы со временем начинают расходиться с реальностью: новые интеграции добавляются, а старые — уходят, а актуализация схем вручную происходит не всегда своевременно.
Чтобы решить проблему мы автоматизировали отрисовку схем опираясь на метаданные IT-систем. Мы создали отдельный микросервис, который этим занимается и назвали его «Architect». О том как это происходит и как работает Architect я расскажу в этой статье, а также дам несколько советов, которые помогут внедрить то же самое у вас в компании.


Вам когда-нибудь приходилось задаваться вопросом, как работает компилятор, но так руки и не дошли разобраться? Тогда этот текст для вас. Мне тоже не доводилось заглядывать под капот, но тут так случилось, что мне нужно прочитать курс лекций о компиляторах местным третьекурсникам. Кто встречался с некомпетентными преподавателями? Здравствуйте, это я :)
Итак, чтобы самому разобраться в теме, я собираюсь написать транслятор с эзотерического языка программирования wend (сокращение от week-end), который я только что сам придумал, в обычный ассемблер. Задача уложиться в несколько сотен строк питоновского кода. Основной репозиторий живёт на гитхабе (не забудьте заглянуть в мой профиль и посмотреть другие tiny* репозитории).

Всем салют!
Хочу рассказать вам историю о том, как я начинал с уровня — «не могу решить даже 1 easy задачу из 10» до уровня — «могу решить каждую вторую medium задачу» и прошел несколько coding сессий в таких компаниях как Meta, Booking, Careem, Avito...

Продолжаю публикацию расширенных транскриптов лекционного курса "PostgreSQL для начинающих", подготовленного мной в рамках "Школы backend-разработчика" в "Тензоре".
Сегодня поговорим о самых простых, но важных, возможностях команды SELECT, наиболее часто используемой при работе с базами данных - формировании выборок (VALUES), их ограничении (LIMIT/OFFSET/FETCH), фильтрации (WHERE/HAVING), сортировке (ORDER BY), уникализации (DISTINCT) и группировке (GROUP BY).
Как обычно, для предпочитающих смотреть и слушать, а не читать - доступна видеозапись и слайды.
Всем привет!
В рамках программы Google Summer of Code 2023 мы с моим студентом разработали плагин для Intellij IDEA, который является аналогом Parallel Stacks из Visual Studio, CLion и Rider для Kotlin coroutines. Плагин анализирует стек трейсы каждой корутины в приложении и строит граф, объединяя общие наборы стек фреймов в вершины. Таким образом, во время отладки вашего приложения вы можете проанализировать
потоки выполнения всех корутин в вашей программе.
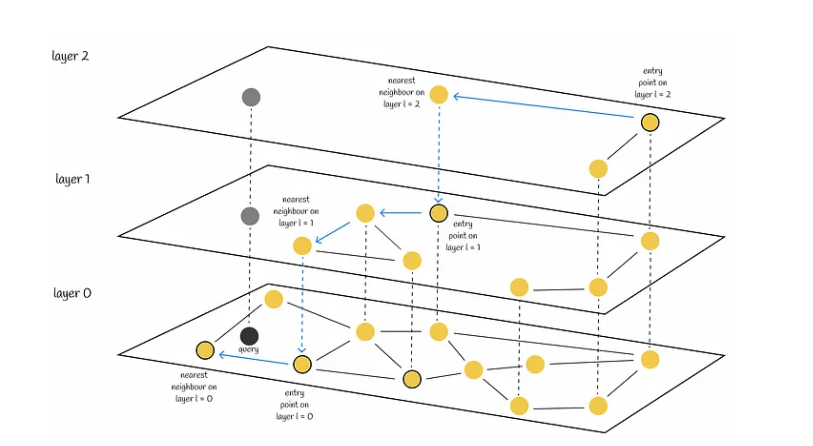
Если вы когда-нибудь использовали в работе retrieval augmentation generation (RAG) на базе векторного поиска и не лезли туда под капот, но были бы не прочь, я постараюсь погрузить вас в то, как устроена векторная база данных внутри.

Всем привет! С вами как всегда я, Аргентум. Сегодня я расскажу и поведаю вам древние тайны, которые хранят горные старцы-сисадмины — тайны об эльфах, и как они взаимодействуют с древним народцем пингвинов. Дамы и господа, встречайте — статья о работе ELF и двоичных файлов в Linux!
Что такое ELF? Чем он отличается от PE в Windows? И многие другие ответы на ваши вопросы.
Перед тем как погрузиться в технические детали, будет нелишним объяснить, почему понимание формата ELF полезно. Это позволяет изучить внутреннюю работу операционной системы. Когда что-то пошло не так, эти знания помогут лучше понять, что именно случилось, и по какой причине. Также возможность изучения ELF-файлов может быть ценна для поиска дыр в безопасности и обнаружения подозрительных файлов. И наконец, для лучшего понимания процесса разработки. Даже если вы программируете на высокоуровневом языке типа Go или Rust, вы всё равно будет лучше знать, что происходит за сценой.
Итак, зачем изучать ELF?
moz_places.sqlite содержатся все посещённые URL-адреса и адреса закладок (то есть moz_bookmarks.sqlite базы данных SQLite). У меня получилось около 2000 закладок. Это меньше, чем я предполагал, так как многие оказались нерабочими из-за битых ссылок. 
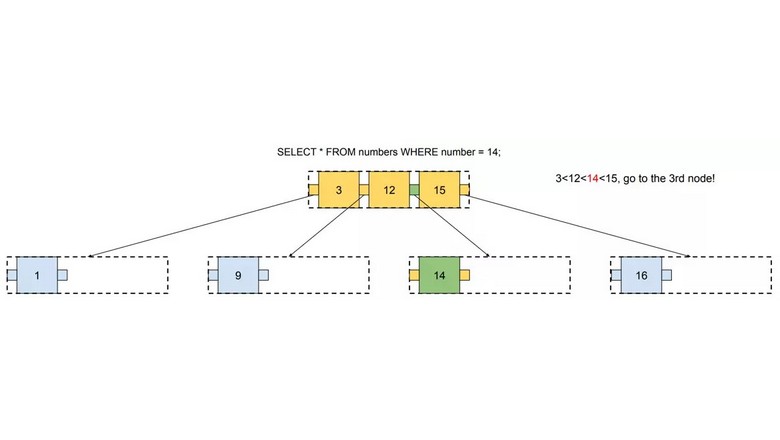
B-дерево — это структура, помогающая выполнять поиск в больших объёмах данных. Она была изобретена более сорока лет назад, однако по-прежнему используется в большинстве современных баз данных. Хотя существуют и более новые структуры индексов, например, LSM-деревья, B-дерево пока никто не победил в обработке большинства запросов баз данных.
После прочтения этого поста вы будете знать, как B-дерево упорядочивает данные и выполняет поисковые запросы.

Это перевод первой главы из поста How Async/Await Really Works in C#
Этот пост .Net блога является продолжением исходного поста, глубоко погружающим в историю, приведшую к созданию конструкций async/await и стоящие за этим дизайнерские решения и детали реализации async/await в C# и .NET.
Исходный пост What is .NET, and why should you choose it? предоставляет обзор платформы на высоком-уровне, перечисляя различные компоненты и решения на уровне дизайна, и предваряя последующие посты в глубину обозначенных тем.
Ссылки в развитие темы:
1. Часть 2 Артефакты от EAP шаблона, SynchronizationContext
2. Уроки по асинхронному программированию из первой половины работы
3. Параллельные вычисления — Все дело в контексте-синхронизации (SynchronizationContext)
4. Async/Await из C#. Головоломка для разработчиков компилятора и для нас
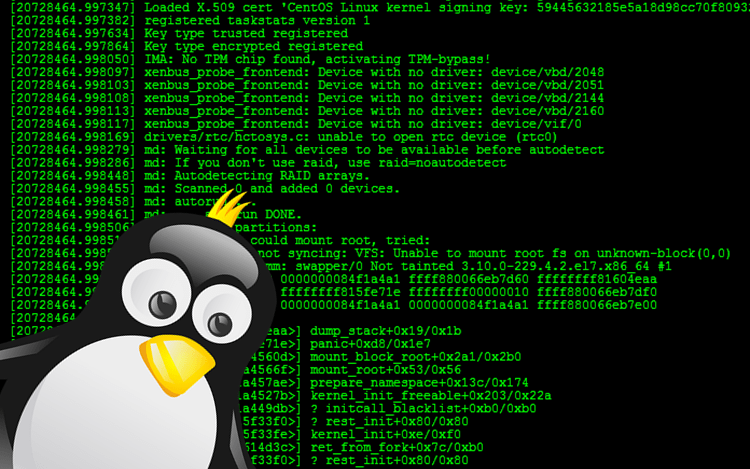
Привет, хабр! Моя прошлая статья о работе памяти в Linux вам понравилась. Сегодня мы разберем работу исключений и прерываний.
Что это, как они работают в ОС и Linux? Давайте разберемся вместе!
Всем привет! Я Ирина Матевосян, системный аналитик в направлении продуктового и системного анализа в отделе Tinkoff Mobile Core. Мы разрабатываем общие библиотеки, которые используют все мобильные приложения экосистемы Тинькофф.
Расскажу о протоколе gRPC. На Хабре много статей о тонкостях реализации, рассчитанных на разработчиков, я же хочу познакомить с ним своих коллег. Разберем, как работает протокол и как написать контракт так, чтобы вас поняли, но не будем погружаться в тонкости программной реализации, а скорее расширим кругозор. Возможно, для кого-то gRPC станет крутым решением в работе.
В 2023 году люди боятся многих новых для них вещей, например, systemd, SELinux, IPv6 и др. От этих вещей люди стараются избавиться, отключить, удалить. Об этом написано во множестве любительских мануалов в интернете, коим может являться и этот. Далее речь пойдёт о протоколе интернета IP версии 6, для краткости — IPv6.
Целью данной заметки показать, что IPv6 не намного страшней того IPv4, который вы сейчас используете. Он способен решить все те же ваши задачи, что вы решали с помощью старого протокола, а также упростить себе жизнь за счёт более простой настройки сети. Кроме того, возможно, даже сейчас используете новый протокол даже не подозревая об этом.
Текст я попытался написать максимально доступным языком. Это не технические руководство. Воспринимайте эту заметку как отправную точку, просто чтобы перестать бояться использовать IPv6 и познакомиться с его основными особенностями, которые отличают его от IPv4, но при этом дают заметные преимущества.

О сложных системах простыми словами.
В шпаргалке на высоком уровне рассматриваются такие вещи, как протоколы коммуникации, DevOps, CI/CD, архитектурные паттерны, базы данных, кэширование, микросервисы (и монолиты), платежные системы, Git, облачные сервисы etc. Особую ценность представляют диаграммы — рекомендую уделить им пристальное внимание. Полагаю, шпаргалка будет интересна всем, кто хоть как-то связан с разработкой программного обеспечения и, прежде всего, веб-приложений. Буду признателен за помощь в уточнении/исправлении понятий, терминологии, логики/алгоритмов работы систем (в рамках того, что по этому поводу содержится в оригинале), а также в обнаружении очепяток.
Выражаю благодарность Анне Неустроевой за помощь в редактировании материала.
Возможно, немного другой формат шпаргалки покажется вам более удобным.
