Осенью‑зимой 2021–2022 годов был проведён опрос среди выпускников МГТУ имени Н.Э. Баумана о том, как люди устраиваются, в каких сферах, какие зарплаты, условия работы и так далее. Было получено множество пожеланий к вузу, выпускникам и поступающим, которые могут показаться интересными и можно понять какие настроения были в среде выпускников в 21–22 годах. Как и в основном опросе рекламу никому не делаю, публикую и ВСЕ отзывы кроме личных обращений. Орфография и пунктуация отзывов сохранены.

User
Управление временем жизни объектов: почему это важно и почему для этого пришлось создать новый язык «Аргентум»
Medium
8 min
Аргентум - язык программирования, построенный на новой ссылочной модели, которая не использует сборщик мусора и гарантирует отсутствие утечек памяти.
«Событие Кэррингтона» 1859 года разрушило телеграфные линии. «Событие Мияке» может стать намного хуже
9 min

В конце лета 1859 года, сразу после полуночи, золотоискатели, дремавшие в Скалистых горах Колорадо, проснулись от полярного сияния. Они описывали его «Такое яркое, что можно было легко видеть друг друга». В своем репортаже об этом, опубликованном в The Rocky Mountain News, газета утверждала, что «некоторые настаивали на том, что это был дневной свет, и начали готовить завтрак».
В тысячах километров оттуда, толпа собралась на улицах Сан-Франциско, тоже глядя наверх. «Все небо, казалось, покрылось волнами, что-то вроде полей зерна на сильном ветре. Воды залива отразили блестящие оттенки Авроры», — написал один журналист из San Francisco Herald 5 сентября 1859 года. — « Ничто не может превысить величие и красоту этого зрелища. Эффект почти сбивает с толку своей невероятностью, и тысячи испытывают смешанное чувство страха и восторга». Похожим опытом в те дни поделились жители всего мира, но больше всего явление было заметно на западе США.
Linux с двойным дном
Medium
13 min
Кулхацкеры всех стран — соединяйтесь!
Если у вас паранойя, это не значит, что за вами не следят.
В этой статье я расскажу как сделать так, чтобы ваша линуксовая машинка выглядела невинной игрушкой, но при вводе нескольких команд превращалась в настоящую боевую единицу. Конечно, у вас могут найти на диске сектора с необычно высокой энтропией, несколько подозрительных системных настроек, но никаких явных зашифрованных разделов, файлов, или сторонних шифровалок. Конечно, вас могут спросить - "а для чего тебе cryptsetup, сынок?", на что вы ответите - "это же Linux Mint, это всё искаропки!" Хуже, если бы вас спросили: зачем ты используешь LUKS, или, что ещё хуже, зачем ты поставил VeraCrypt или Shufflecake.
В любом случае как отмазываться - не тема этой статьи. В комментариях расскажут всё, и даже гораздо больше. Я лишь описываю способ со всеми его достоинствами и недостатками, а уж анализ рисков - на ваше усмотрение.
Главное в системе с двойным дном - это, конечно же, секретные зашифрованные разделы, которые нигде не отсвечивают. Мой способ - это...
Про школу и продуктивное мышление
Easy
10 min
Opinion

Звонок в два часа ночи.
— Марьиванна, это Вы?
— Да!
— Это папа Вашего ученика. Вы спите?
— Да!!
— А мы, блин, учим!!!
Когда руководитель у нас может сам прийти к вам с повышением зарплаты
Easy
5 min
Case

Представим, что ваше желание уволиться можно описать одним числом. Что будет влиять на него? Понятно, соответствие зарплаты ожиданиям. Потом — ваш комфорт в коллективе, адекватность руководителя. Расстояние до офиса, если вы ездите в офис, или до ЦОДа, если вы ездите в ЦОД, возраст, срок последнего повышения и так далее.
В этой модели всегда было слабое место — сложно посчитать совокупность влияния людей на вас. В целом-то всё просто: если вы работаете с теми, кто вам неприятен, то в зависимости от частоты взаимодействий желание уволиться растёт.
Следующий фактор: когда на новое место работы уходит кто-то, с кем вы сработались, ваш шанс на увольнение также резко растёт. Потому что он позовёт к себе — или потому что у вас уменьшится число людей, с кем вам было комфортно.
Мы не можем сказать, кто и с кем сработался. Таких источников данных у нас просто нет. Но мы сделали допущение о том, что если сотрудники плотно друг с другом взаимодействуют, то уход одного сотрудника увеличит вероятность ухода другого. И дальше на основании этого допущения составили граф всех сотрудников, в котором учли плотность взаимодействия между ними.
И знаете что? Наша модель начала предсказывать увольнения за 3 месяца с точностью около 70%. В смысле, из тех, кого модель разметила на месяц вперёд подтвердилось 73% случаев (точность), при этом модель находит 40% от всех увольнений (полнота).
Теперь мы можем с этим что-то делать.
Естественно, у этой модели огромное количество ограничений. Сейчас мы с DVAMM про всё это расскажем.
KeyDB и Redis: в поисках серебряной пули — in-memory replicated DB (Replicated IMDB)
Medium
19 min

На кластерах клиентов, которые мы обслуживаем, есть как «одноголовые» инсталляции Redis (обычно для кэшей, которые не страшно потерять), так и более отказоустойчивые решения — Redis Sentinel или Redis Cluster. По нашему опыту, во всех трех вариантах можно безболезненно переключиться с Redis на KeyDB и получить прирост производительности. Точнее, избавиться от бутылочного горлышка Redis в одно ядро. Хотя в новых версиях Redis(r) появилась обработка I/O в отдельных тредах, иногда этого бывает недостаточно.
В то же время, если мы хотим использовать отказоустойчивые решениями вроде Sentinel и Cluster, нам понадобится поддержка этих технологий на уровне библиотеки, которую приложение использует для подключения в Redis. Причем лишь немногие библиотеки умеют читать из реплик Redis — в обоих вариантах (Sentinel и Cluster) чтение, как правило, происходит с мастеров. И запись, естественно, тоже происходит в мастеры.
В итоге у нас есть несколько реплик довольно дорогого in-memory-хранилища, а в рабочем процессе используется только часть из них. Остальные — на подхвате. Хотя в большинстве кейсов операции с in-memory NoSQL DB — это именно операции чтения.
Однако если посмотреть в сторону KeyDB, то можно увидеть, что там есть киллер-фича — и даже две: я говорю о режимах Active Replica и Multi-Master. Использование этих режимов позволяет получить распределенный отказоустойчивый KeyDB, совместимый с Redis, писать в любую ноду, читать из любой ноды. И все это с точки зрения приложения выглядит как один экземпляр Redis без всяких Sentinel — то есть в коде приложения ничего менять не придется.
Звучит как фантастика?
Как построить систему, способную выдерживать нагрузку в 5 млн rps
Medium
12 min

Всем привет!
Меня зовут Владимир Олохтонов, я руковожу командой разработки в отделе Message Bus, который является частью платформы Ozon. Мы занимаемся разработкой самых разных систем вокруг Kafka, etcd и Vault. В этой статье я расскажу о том, как мы строили линейно масштабируемую gRPC-прокси перед Kafka, способную обслуживать миллионы запросов в секунду, используя Go.
Бóльшая часть технического контента — дерьмо
Easy
4 min
Opinion
Translation
За последние несколько лет, при работе и разговорах со многими разработчиками, я заметила один повторяющийся шаблон поведения. Он начал меня сильно беспокоить, и я продолжаю постоянно говорить и думать о нем, пытаюсь его понять или даже оправдать.
Данный шаблон поведения - это потребление, а не созидание. Потребление без каких-либо вопросов. Потребление прикрывающиеся мнением авторитетов.
Как писать про свой DIY-проект, чтобы его полюбили тысячи?
Easy
3 min
Tutorial

Что относится к DIY? Любой завершённый проект, при создании которого использованы лучшие ресурсы человека: руки и мозг, фантазия и изобретательность, инженерная мысль и рабочий дизайн. Это может быть что угодно: от бумажной настолки с необычной логикой до самодельного автомобиля. Проект может реализовать самоучка или топовый инженер, программист или просто очень хороший родитель — важно, что такие проекты реализуются для целей обучения, развлечения, реализации своих способностей и для пользы людей (а как показывает Хабр, ещё и котов).
Но, к сожалению, не каждый изобретатель готов рассказать о своём проекте — нередко причина кроется в страхе сесть и начать писать, непонимании, как это — говорить буквами о технике (хотя, по нашему опыту, все с этим отлично справляются). Мы подготовили для вас крошечный гайд, почти план — как писать о DIY-проекте на Хабр.
Страшные истории про SWIFT: инструкция, как профукать $100500 на переводе
11 min

В этой статье мы детально разбираемся: как на самом деле работает этот ваш SWIFT, каким образом россияне теряют огромные суммы денег в недрах зарубежных банков из-за неудачных переводов, и, самое главное, – что конкретно нужно делать, чтобы ваш перевод долетел куда надо в сухости и комфорте?
Самое сложное в ПО — не кодинг, а требования, или Почему разработчикам не стоит бояться ИИ
Easy
7 min
Opinion
Translation

Из-за всех этих статей о том, насколько потрясающ прогресс ИИ, у многих возникло отчаяние в связи с возможностью скорой замены разработчиков ПО искусственным интеллектом. Люди представляют, что руководители и исследователи продуктов передадут всю работу по созданию ПО искусственному интеллекту. Так как я уже пятнадцать лет пишу ПО по спецификациям, созданным этими людьми, то не могу воспринимать серьёзно подобное беспокойство.
Кодинг может быть сложным, но мне никогда не требовалось больше двух недель, чтобы разобраться с проблемами в коде. Если освоить синтаксис, логику и методики, то процесс оказывается довольно прямолинейным. Настоящие проблемы обычно связаны с тем, что ПО должно делать. Самое сложное в создании ПО — не написание кода, а создание требований, а требования к ПО по-прежнему определяют люди.
В этой статье я расскажу о связи между требованиями и ПО, а также о том, что необходимо ИИ для создания хороших результатов.
Simba: Симуляция десятков тысяч частиц в потенциале Леннарда-Джонса на чистом Python с GPU-ускорением
9 min

Добрый день, уважаемые хабровчане.
Примерно год назад я начал проект симулятора динамики частиц на Python, используя библиотеку Numba для проведения параллельных расчетов на видеокарте. Сейчас, добравшись до определенной вехи в его развитии, я решил открыть исходный код и выложить его на GitHub для всех, кому интересны подобного рода эксперименты.
Самостоятельно потыркать проект можно вот тут: https://github.com/r-aristov/simba-ps
В этой статье я кратко опишу суть проекта, пройдусь по прилагающимся к нему примерам и расскажу почему вообще начал работу над ним.
Хозяйке на заметку: автоматизируем рутинные процессы и экономим время
Medium
5 min
Review

Каждый день разработчики и тестировщики сталкиваются с рутиной, которая отнимает время и энергию. А ведь хочется заниматься более творческими задачами. К счастью, технологии сегодня позволяют автоматизировать многие рутинные процессы, что значительно экономит время и повышает эффективность работы.
В этой статье я расскажу о неочевидных автоматизациях, которые сделали нашу жизнь проще, и покажу, как реализовать их. В большинстве случаев нужна только техническая учётка для баг-трекера или DevOps-платформы.
Как работает хэширование
Medium
12 min
Tutorial
Translation

Если вы программист, то пользуетесь хэш-функциями каждый день. Они применяются в базах данных для оптимизации запросов, в структурах данных для ускорения работы, в безопасности для защиты данных. Почти каждое ваше взаимодействие с технологией тем или иным образом включает в себя хэш-функции.
Хэш-функции фундаментальны и используются повсюду.
Но что же такое хэш-функции и как они работают?
В этом посте я собираюсь развенчать мифы вокруг этих функций. Мы начнём с простой хэш-функции, узнаем, как проверить, хороша ли хэш-функция, а затем рассмотрим реальный пример применения хэш-функции: хэш-таблицу.
Первые шаги в импульсных нейронных сетях
Medium
21 min
Translation
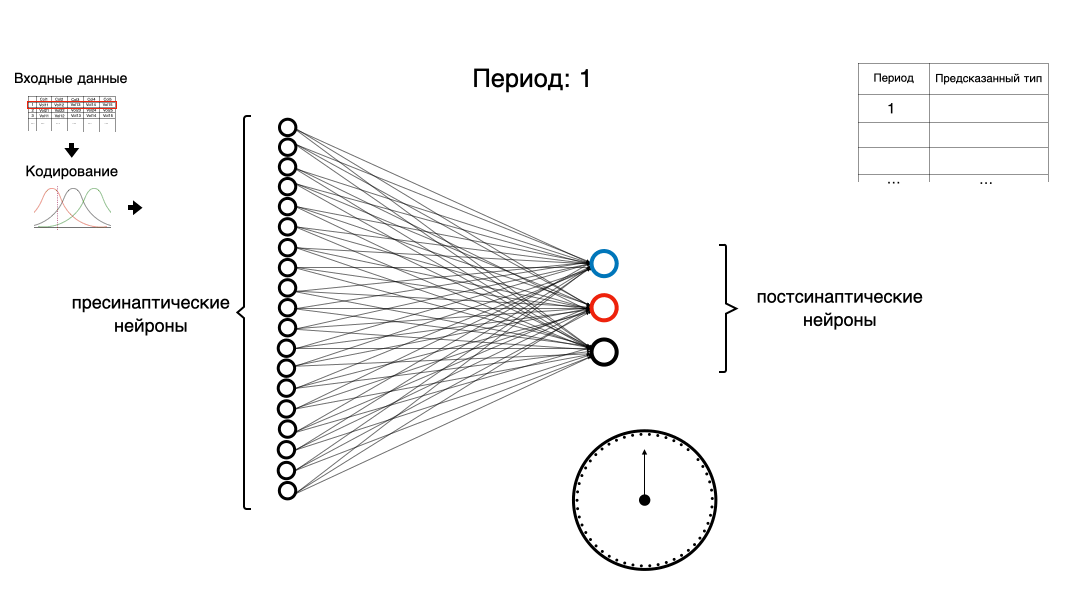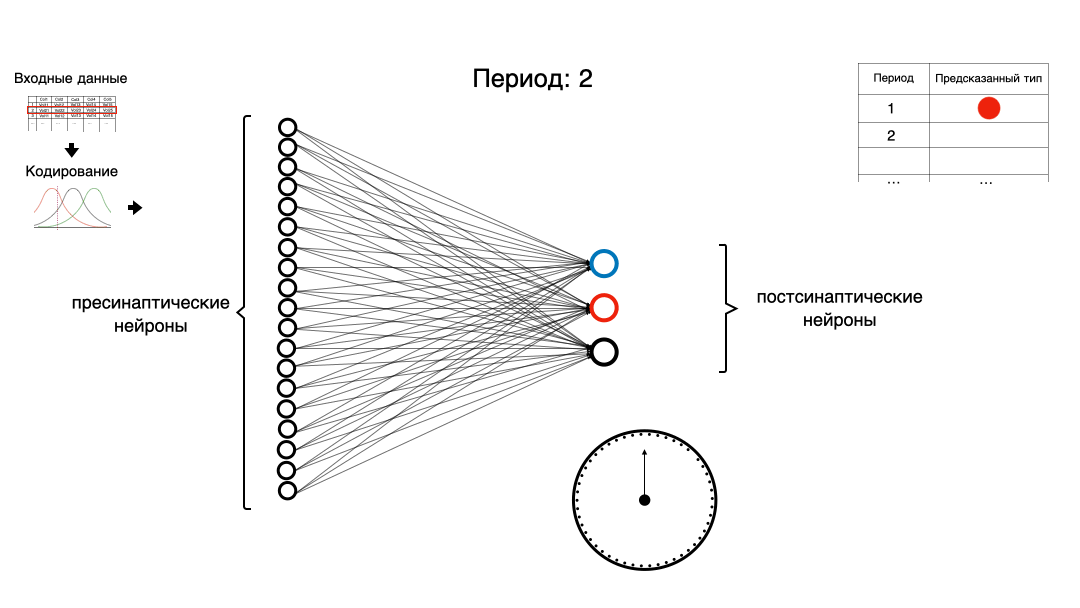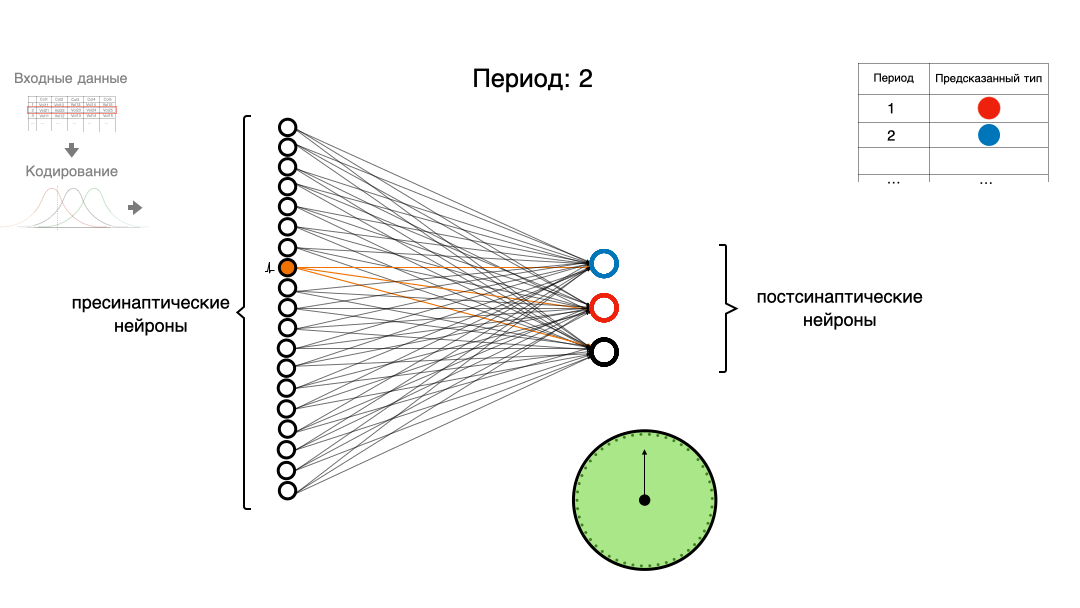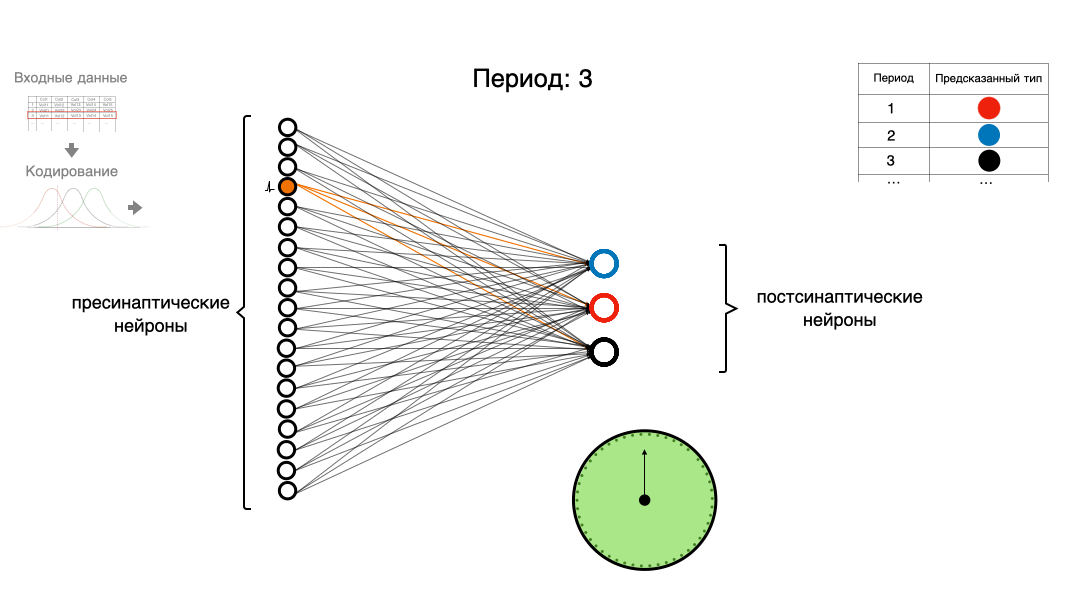
Давайте попробуем немного разобраться в теме импульсных нейронных сетей (spiking neural network, SNN). Напишем простую импульсную нейронную сеть, используя только NumPy и Pandas, для классической задачи машинного обучения с использованием кодирования рецептивными полями.
[Пятничный вызов] Надоело программировать
2 min
Я не писатель, извините, если криво изложил, но суть должна быть понятна...
В общем, когда я только учился программированию, мне было очень интересно. Особенно ковыряться в коде на C++, изучать, как там устроена память, загрузка модулей DLL, или внутренности операционной системы. Но работы особо не было по этой тематике, поэтому со временем приходилось двигаться на уровень абстракции всё выше и выше.
Но штука в том, что по мере того, как я получал больше опыта и наблюдал за индустрией, после изучения разных технологий и фреймворков начала накапливаться какая-то усталость от всего происходящего в мире разработки. Сейчас постараюсь объяснить.
Встроенные фикстуры Pytest
Easy
8 min

Всем привет! Я Никита Вандышев, ведущий QA-инженер в Тинькофф Мессенджере.
Во время собеседований QA-инженеров я заметил, что многие знают про то, как создавать фикстуры, но мало кто знает про существование встроенных фикстур в Pytest.
Встроенные фикстуры — хороший инструмент, чтобы не создавать свои велосипеды и эффективно использовать мощь фреймворка, которую хотели передать авторы. Фикстуры помогают в разных случаях: при работе с выводом ошибок, логировании, создании отчетов и так далее. В статье разберем основные встроенные фикстуры и их применение в Pytest.
Как сделать быстрый дашборд по таблице из 150 млн строк с помощью Yandex DataLens и ClickHouse
Medium
6 min
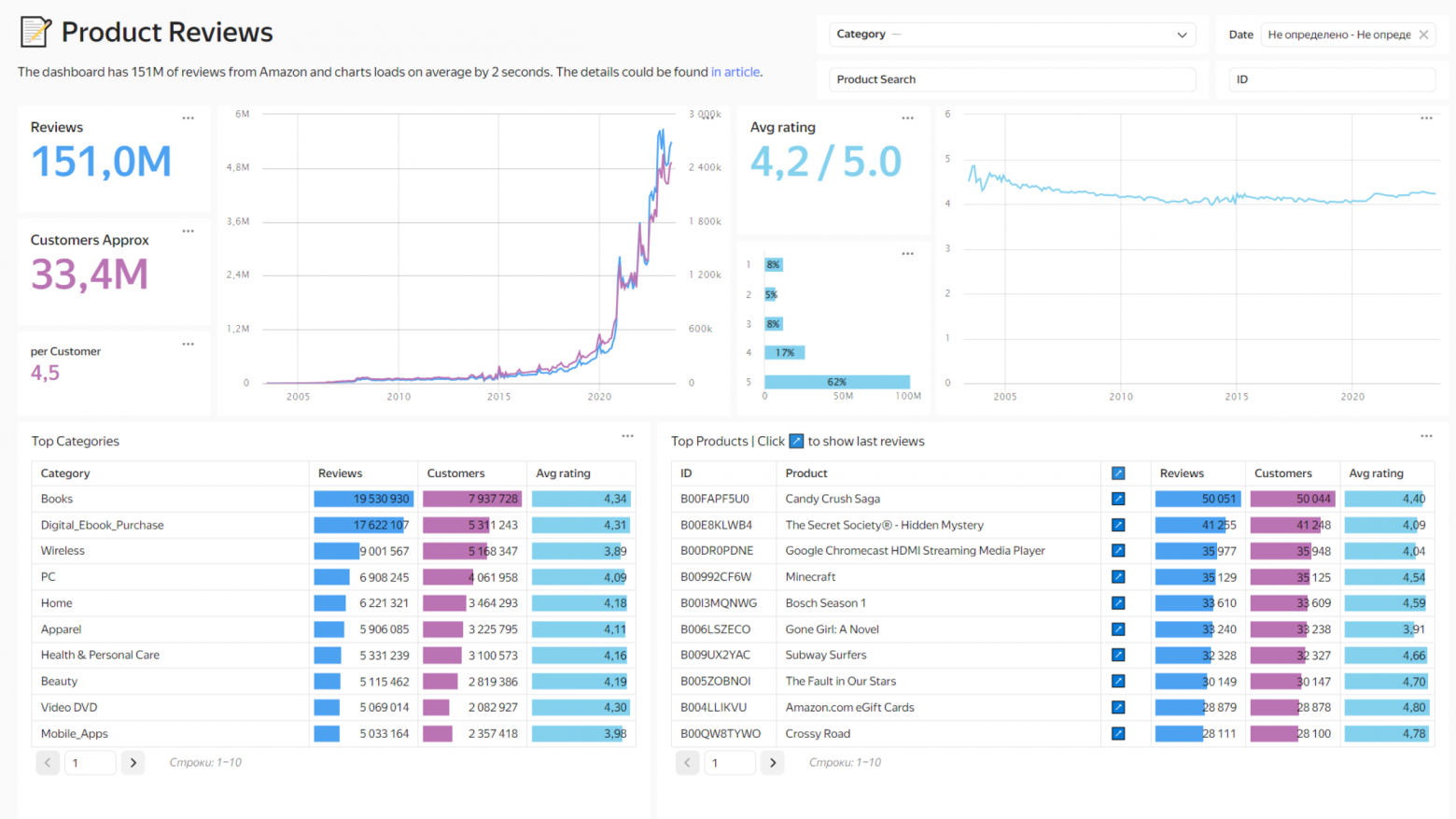
Привет! Меня зовут Роман Бунин, я BI-евангелист Yandex DataLens. При росте объёма данных, что неизбежно для любой компании, загрузка дашбордов может замедляться до десятков секунд. И чем больше появляется данных, тем медленнее становятся дашборды, особенно если вы хотите строить их по детализированным таблицам.Связка базы данных ClickHouse и BI-системы Yandex DataLens — популярное решение для анализа данных: эти инструменты нативно интегрируются и быстро работают вместе. В этой статье вместе с моим коллегой, архитектором Yandex Cloud Игорем Путятиным, покажем, как на основе таблицы из 150 миллионов строк построить максимально быстрый дашборд, и расскажем о технических ограничениях.
Шпаргалка по SQL (postgres), которая выручает меня на собесах
Easy
8 min

Привет, Хабр!
Я решил посвятить свою первую статью SQL. Вопросы, рассмотренные ниже мне задавали на собеседованиях на позицию python-разработчика. Естественно отвечать правильно получалось не всегда, а если точнее то чаще не правильно, однако проведя N часов в рефлексии я составил перечень ответов, которыми пользуюсь до сих пор.
Данная информация предполагает знание основ языка запросов и я надеюсь, она окажется полезной для разработчиков, которые сейчас активно ищут работу а также, что ты прочитаешь этот текст до конца и добавишь свой вопрос к перечню (ну или поправишь неточности в существующих)