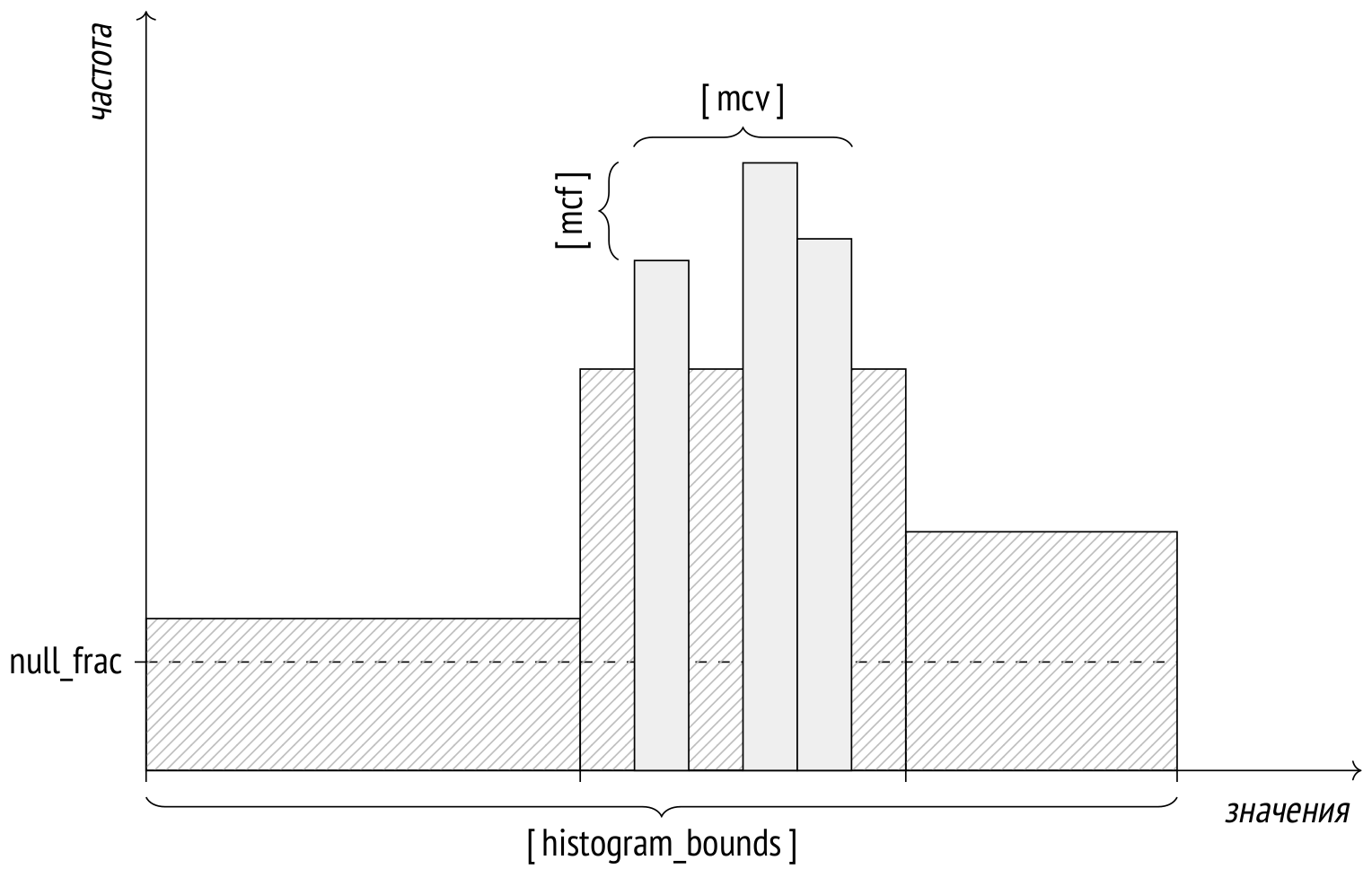
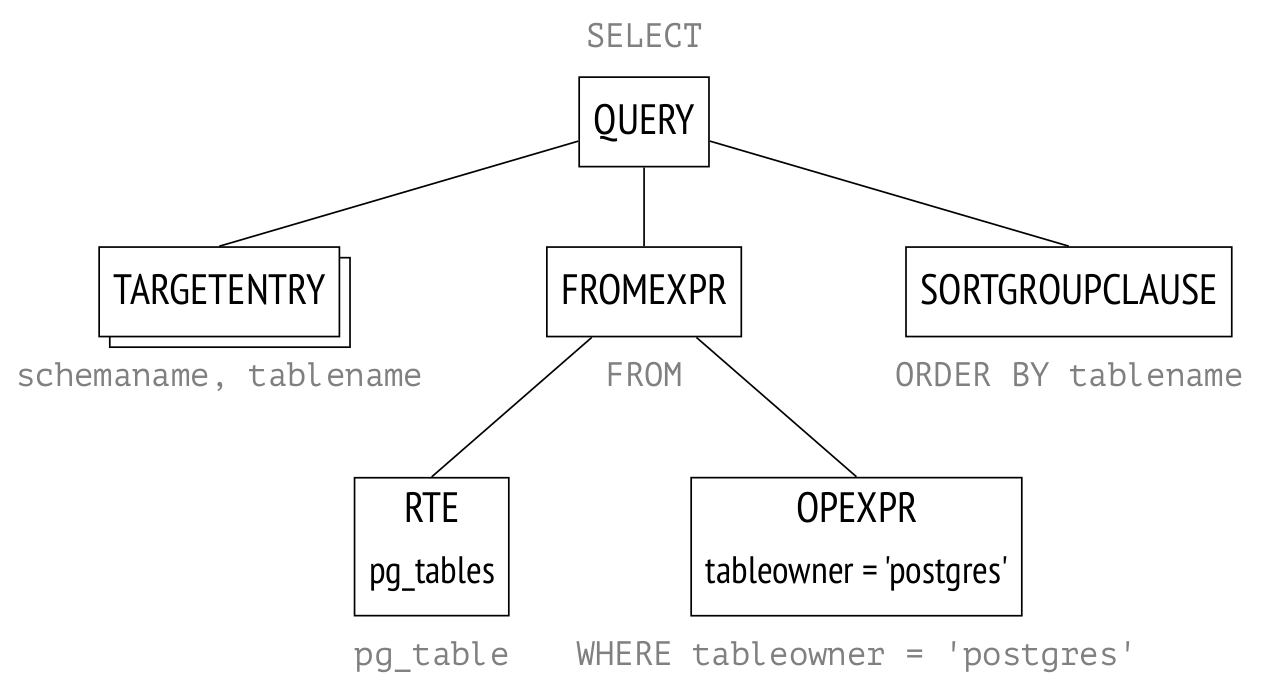
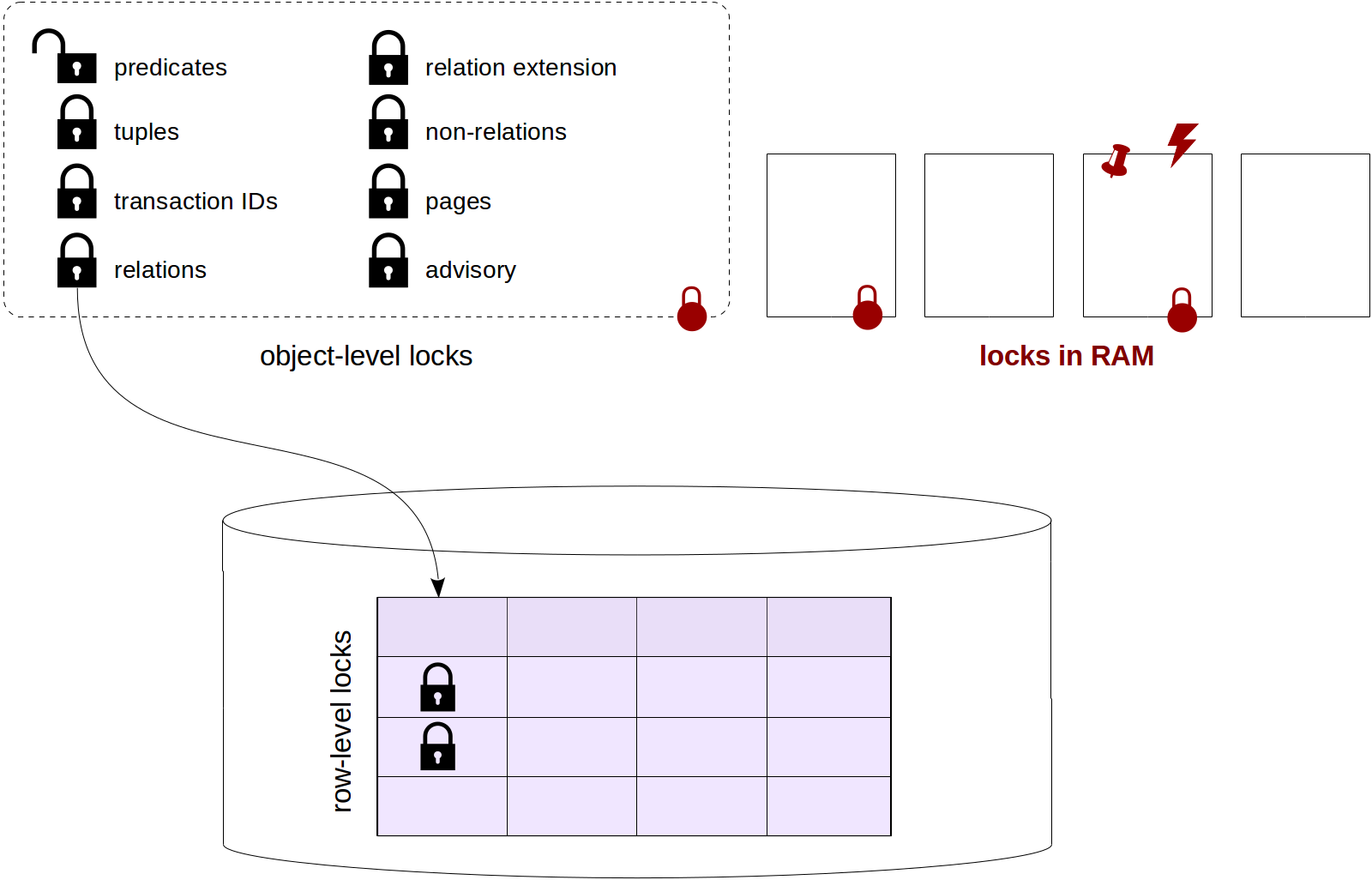
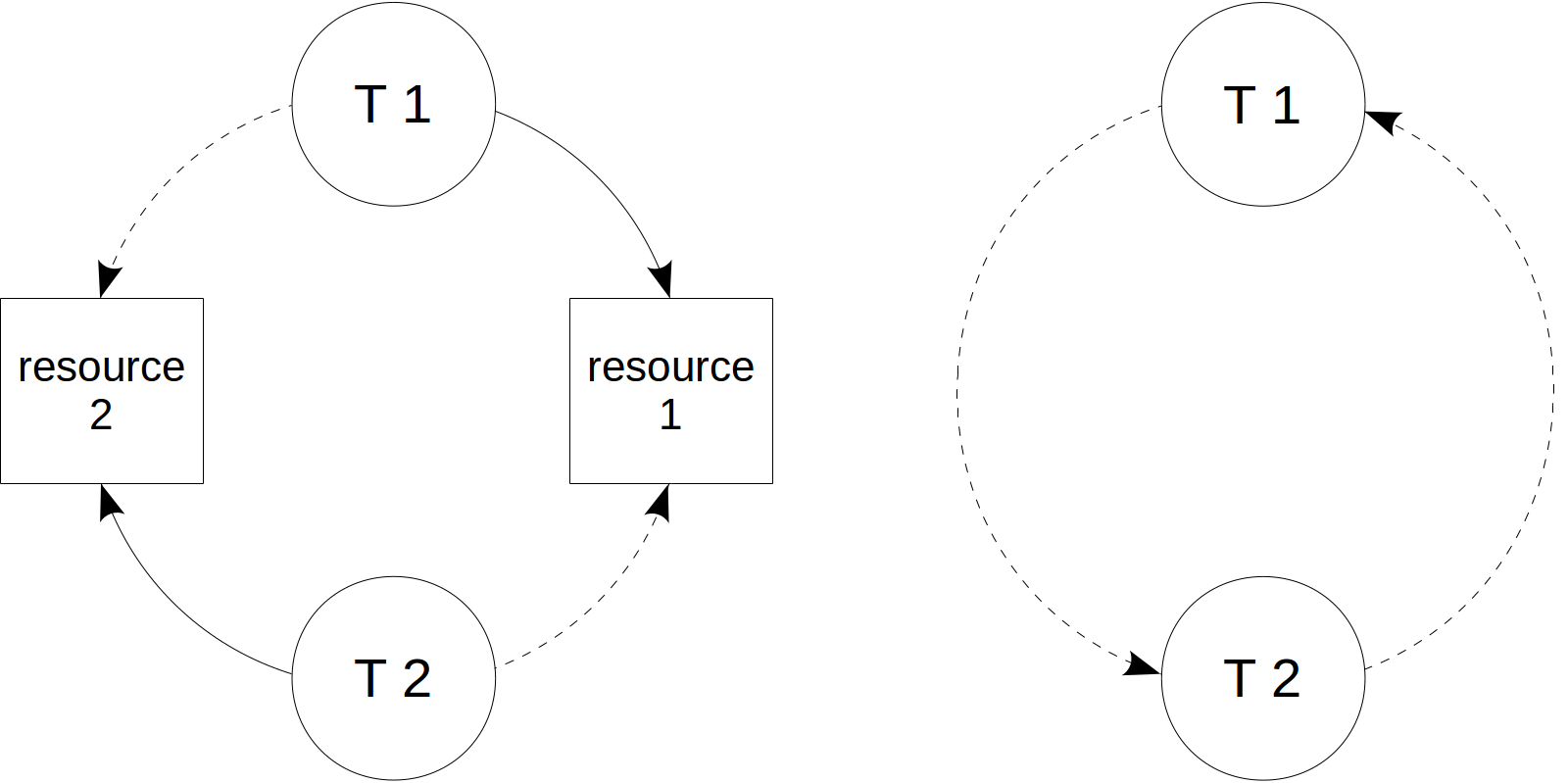
На третьем этапе олимпиады мы, как обычно, решали задачки на SQL, но в этом году надо было написать запрос не просто правильный, но и короткий. Чем короче — тем лучше результат. В детстве мы развлекались таким на микрокалькуляторах и на ассемблере, а сейчас я решил посмотреть, что получится, если попробовать то же на SQL. Получилось, на мой взгляд, интересно. Практического смысла в этом, конечно, никакого нет, но практики и на работе хватит, а тут мы развлекаемся.
Чтобы хорошо выступить, надо было — помимо прочего — выстроить правильную стратегию. Сразу писать максимально короткий запрос, без пробелов и с односимвольными именами не получится — легко самому запутаться. Поэтому сначала надо было решить задачу «по-человечески», а уже потом применить всякие микрооптимизации и получить заветные баллы. Но решить задачу, даже простую, всегда можно разными способами, и не всегда заранее понятно, какой из вариантов окажется короче после оптимизации. Поэтому нужно было не останавливаться, пробовать разные подходы, и при этом аккуратно хранить все версии, чтобы в любой момент можно было посмотреть на запрос еще раз и, чем Тьюринг не шутит, выиграть байтик-другой.
Мы традиционно разрешали пользоваться всеми благами интернета, включая ИИ. На эту тему многие сейчас переживают, но, честно говоря, я пока не вижу причин для беспокойства. Вот если бы все участники показали одинаково прекрасный результат, пришлось бы что-то придумывать. И то, конечно, не запрещать ИИ, а делать задачи более сложными. Но результаты у всех разные, и без собственной головы на плечах их не удалось бы получить (я попробовал), поэтому пока все хорошо. Если финалисты меня читают, было бы интересно услышать комментарии от первого лица: пользовались ли вы ИИ, насколько он вам помог или, может быть, наоборот, только отвлекал?