D3.js — это библиотека JavaScript для управления документами, в основе которых лежат данные. D3 помогает претворить данные в жизнь, используя HTML, SVG и CSS. D3 позволяет привязывать произвольные данные к DOM, и затем применять результаты манипуляций с ними к документу.
Для понимания статьи пригодится знание основ D3, и в ней мы рассмотрим реализацию алгоритмов визуализации графа на основе сил (Force-directed graph drawing algorithms), которая в D3 (version 3) имеет название Force Layout. Это класс алгоритмов визуализации графов, которые вычисляют позицию каждого узла, моделируя силу притяжения между каждой парой связанных узлов, а также отталкивающую силу между узлами.








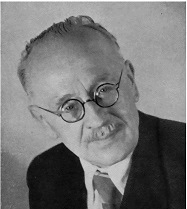 А еще сегодня 16 декабря, день рождения
А еще сегодня 16 декабря, день рождения