Так сложилось, что я уже много лет руковожу научной группой, а с недавних пор лабораторией в МГУ. При этом львиная доля финансирования нашей лаборатории идет от компаний. Изначально она была создана в рамках контракта с Intel (совместная лаборатория), а позднее мы очень активно работали ещё и с RealNetworks (20+ проектов), Samsung (совместная лаборатория), Cisco, Huawei (до 5 контрактов параллельно) и другими. И так получилось, что большая часть наших контрактов (примерно 95% по количеству и 99% по деньгам) приходилась на иностранные компании, при этом взаимодействие с российскими компаниями в среднем заметно контрастировало.
Моим наилучшим примером отношения русских компаний к университетам является
любимый пример Олега Тинькова из его книги:
«Третий пример, мой любимый. Весной 2011 года я выступал на мехмате МГУ и с присущим мне эпатажем заявил: «Что такое фундаментальная наука. Ходить грязным, вонючим и в итоге стать нобелевским лауреатом? Так вот, это все булшит! Зарабатывайте деньги. Не думайте про фундаментальную науку, потому что это отстой».
Олег Тиньков, «Революция. Как построить крупнейший онлайн банк в мире»
С Тиньковым есть, о чем поспорить. Например,
Нобелевская премия за достижения в области математики не присуждается, а присуждаются
Филдсовская и
Абелевская премии. Впрочем, Тиньков этого мог и не знать. Важнее, что он явно приводил этот пример много раз, и в книге он дан в главе про найм специалистов.
Меня периодически спрашивают друзья из компаний: «Как там наука? Поднялась с колен? Я слышал — ситуация получше стала». Кому интересно,
как Тиньков развалил мехмат что происходит в науке в разрезе работы с компаниями (этюды в багровых тонах, вечерние зарисовки из окопа автора) — добро пожаловать под кат!


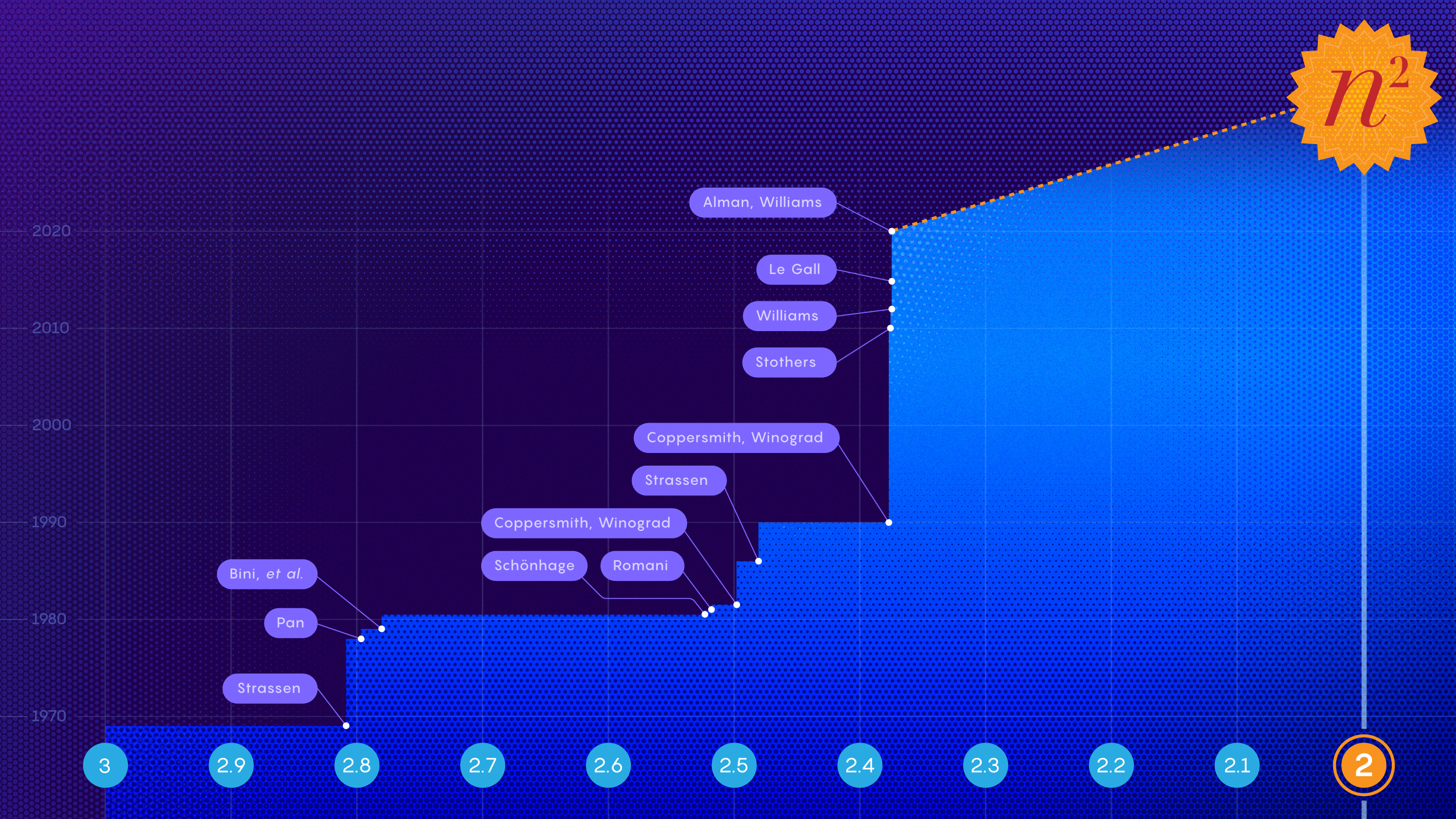
 Изображение предоставлено автором. Основано
Изображение предоставлено автором. Основано 








 .
. 

 Сначала я хотел честно и подробно написать о методах снижения размерности данных —
Сначала я хотел честно и подробно написать о методах снижения размерности данных —