Comments 1280
те языки и подходы, которые в итоге оказывались самыми практичными и популярными
Популярность — продукт рекламы и продвижения крупными компаниями. Качество при этом и рядом не валялось. Только финансовые интересы.
А с учетом такой популярности про практичность говорить бессмысленно.
Всё-таки между академическим программированием и прикладным есть большая разница.
Прикладное программирование — это когда школота лепит быдлокод? Для них и придуман был ООП.
Один мой знакомый в давние времена сказал такую умную вещь: объектное программирование должно быть в голове, а не в языке.
А большинству современных программистов до Дейкстры, как до Шанхая…
Прикладное программирование — это когда школота лепит быдлокод?
Ну, если школота прямо сейчас решит задачу, которая позволит уже завтра продать продукт, то почему нет? У меня есть один коллега, все ворчит, что код не тот. Но когда ему говоришь «ОК. У тебя появляются возможность 2 дня писать код без оплаты». Он вдруг задает вопрос, а почему это?
Академический интерес это очень занятная штука. Заставляет шевелить мозгами и это очень даже хорошо. Но проблема в том, что она не всегда приносит денег! А деньги люди очень любят, думаю и вы тоже!
Хотим мы с вами или нет, но мы решаем задачи бизнеса. А пользователь на бизнес стороне, как правило, понятия не имее про ООП или BDD или синглтон. Ему наплевать что там в кишках! Он просто тыкает кнопку и если она не решает его задачу он не платит денег. И хоть вы там идеальную архитектуру наколбасите ему будет пофиг, лишь бы кнопка делала то что надо!
Когда вас просят «добавить рюшечку» и вы это делаете — без плана и дизайна, то получается пресловутый Дом Винчестеров.

Автор же, совершенно справедливо, отмечает, что нормальные, удобные дома — так не строят. Но до этого индустрия разработки ПО — пока не доросла.
На самом деле методы написания хороших программ были придуманы и стандартизованы ещё во времена первых Space Shuttle. Просто до сих пор мало кто в это умеет: из-за холиварщиков типа Дейкстры программисты уже три десятка лет занимаются поиском самого "правильного" языка программирования и обсиранием "неправильных" языков: это как если бы электронщики каждые 5-10 лет придумывали новый набор обозначений на схемах для отображения всё тех же резисторов, транзисторов и конденсаторов.
А решение проблемы находится на более высоком уровне: на уровне организации, методик и подходов.
А решение проблемы находится на более высоком уровне: на уровне организации, методик и подходов.… которые не позволяют даже NASA избежать ошибок…
Обозначения тоже важны, просто в последнее время им уделяется куда больше внимания, чем следует.
Это уже скорее аналог добавления новых функций в библиотеку: никто не пересматривает обозначения резистора, например, или сложения в математике.
Навскидку.
Всё в порядке с диодами, просто не надо путать направление тока и направление движения электронов!
Если вы желаете исправить "ошибку" — надо начинать с пересмотра определения электрического заряда, чтобы он стал у электрона положительным. Но не думаю что физики такой пересмотр поддержат.
Есть 2 обозначения резисторов, «советский» прямоугольником и «западный» пилой.
Есть примеры и в математике: tg и tan, скажем. Или десятичная запятая/точка.
Диоды следовало бы пересмотреть — когда рисовали их значок, думали что ток течёт в другую сторону, а дальше «так исторически сложилось».
А вот тут никакой проблемы нет. Направление тока (туда же, куда электроны, или в противоположную сторону) вообще не имеет особого значения на практике для расчёта цепей. Надо просто один раз договориться. И договорились: от плюса к минусу.
На самом деле методы написания хороших программ были придуманы и стандартизованы ещё во времена первых Space Shuttle.И сколько такие методы будут стоить компаниям? В том-то и проблема что хорошесть программ может определяться очень разными способами, не существует универсального параметра качества. И стоимость разработки решения практически всегда вносит определенный вклад в то, насколько программа хороша для ее заказчика.
И именно эту проблему как раз помогает если не решать, то слегка уменьшать ООП. Каждая новая рюшечка более-менее отдельный монстр
1. Пользователь решил проблему. Больше не пришел
2. Кроме одного пользователя эту сделанную фичу больше никто не использовал
3. Пользователь решил проблему. Пришел с багой\предложением
…
и еще 100500 вариантов развития будущего.
Вы уверены, что в написанном коде вам действительно придется ковыряться и что-то переделывать? Да, можно вспомнить закон Мерфи про то что худшее по-любому случится, если оно может случиться. Но на практике вариаций развития будущего масса! Как надо будет переписывать так и не надо, а иногда и оказалось не надо и лучше удалить код, нет кода — нет багов!
Мы же когда пишем код мы же обычно так поступаем:
Встретилась задача просто пишем код. Встретилась второй раз тупо копи-пастим. Встретилась в третий — выносим в отдельную функцию. Втретилась в четвертый — выносим в библиотеку.
Ну так и тут надо также! Сначала вы просто пишете код. Да, стараетесь написать по-лучше. Но слишком заморачиваться не стоит, т.к. «лучшее враг хорошего». И уж если потом потребуется тогда и сделаете как надо, т.е. тогда, когда это действительно будет оправдано.
Другими словами: Если значимость и ценность кода еще не доказана требованиями бизнеса, то тратить на него слишком много времени и усилий не следует. Исходить нужно из математической фразы «необходимо и достаточно»
Исходить нужно из математической фразы «необходимо и достаточно»
Я всё же предпочитаю делать небольшой "запас прочности", да хотя бы чтобы удалить больше ненужный код было просто без особых рисков сломать что-то.
Чтобы написать хороший код вы должно понимать (и желательно хорошо так понимать) — что за код вы пишите и как он долежн работать.
Чтобы написать плохой код… вам не нужно ничего. Тяп-ляп и в продакшн.
То есть написать какой-то плохой код — гораздо быстрее, написать отлаженный плохой код… на самом деле даже дольше, чем хороший… но кого это волнует?
Посмотрите вокруг: «потерявшиеся» кортинки, неработающие кнопки и так далее и тому подобное… это же норма! Никто не доводит код до безошибочного состояния.
Мы, программисты, всегда почему-то свято верим в то, что пользователь придет и по-любому попросит что-то поменять\добавить. А это не так! Да, приходят и просят, но не всегда! Очень часто решат свою задачу и забудут, то у вас в принципе есть такая хорошая программа.
Как я в прошлом году пошел в гугл, нашел youtube-видео-даулодер, поставил, скачал видео и все! Больше я НИ РАЗУ с прошлого года эту прогу не запускал. Мне абсолютно наплевать насколько там идеально хорошо продумана архитектура.
Вот вы напишите сразу «хорошо» потратите на 5 часов больше времени, а пользователь больше ни разу не обратиться по поводу вами разработанной фичи. А из какого кармана эти допольнительные 5 часов будут оплачиваться? Из вашего? Согласны, чтоб из вашего, а не работодателя?
Слово "клиент" подразумевает несколько другую модель разработки по сравнению с публичными небольшими программами. В разработке на заказ или длительной продуктовой очень часто просьбы что-то изменить приходят ещё до того как работа доведена до какого-то логического конца. Да и вы один раз воспользовались, а, возможно десятки тысяч людей пользуются регулярно и просят авторв что-то улучшить, чтобы пользоваться было удобнее.
Во второй половине XX века во время холодной войны наука и технология бурно развивались за счет заказов от военно-промышленного комплекса. Ну и в виде побочного продукта доставалось гражданке.
Сейчас военные расслабились, вместо реальной работы придуряются, активно пилят огромные бюджеты. Результат на лицо.
А бизнесу нужны только деньги, ничего кроме денег. В программировании деньги в основном зарабатываются на рекламе. Все эти поисковики, мессенджены и пр. заточены на втюхивание китайских товаров.
Правильные языки никому не нужны, энтузиасты без финансирования даже если сделают, без агрессивного продвижения никто не будет такой язык использовать.
И еще, популярность Java Scrip обусловлена саботажем разработчиков браузеров. Почему нельзя сделать нормальный вменяемый язык для фронтенда с контролем типов? Вот и выросло поколение горе-программистов, не понимающих, зачем нужен статический контроль типов, проверка используемости процедур (или, как сейчас модно говорить, методов). Объяснять таким полезность контроля равносильно попытке объяснять глухому от рождения величие классической музыки. И это не их вина, это их беда.
Почему нельзя сделать нормальный вменяемый язык для фронтенда с контролем типов
А разве таковым не был Dart который не взлетел?
Другое дело, что оказалось не так-то просто добавить статическую типизацию в LISP и не потерять его выразительности…
Самая лучшая апологетика динамической типизации (не с ура-пофигистских позиций типа «а нафига типы?»), которую я видел, здесь:
youtu.be/YR5WdGrpoug
youtu.be/2V1FtfBDsLU?t=1143 (можно даже отсюда начать: youtu.be/2V1FtfBDsLU?t=1639)
Расшифровка есть?
Текст выступления? Или перевод на русский?
Насколько я знаю, ни того, ни другого нет.
Ни разу не использовал void* даже в C++, ЧЯДНТ?
Прекрасная позиция, ведь за Вас его используют авторы библиотек. )) Вот пусть они и отдуваются)))
А void* — да, с ним авторы библиотек пусть возятся. Это их работа.
Я, если что, писал свой any и свой variant. Даже там как-то удалось обойтись без void*.
Было бы занятно взглянуть. Это возможно?
Если Вы используете такой срез C++, где не нужно явно использовать просто машинный адрес и/или взаимодействовать с C — почему нет. Но я бы не стал этим гордится)))
А так — указатель на базовый класс, от которого наследуется шаблонный производный класс. Всё. Никаких void*, всё очень типобезопасно.
И указатель на этот самый базовый класс и оказывается нижней гранью выбранной «подсистемы» типов. Но C++ не ограничивается только этой «подсистемой», поэтому void* в нем необходим.
Я понял, что Вы имеете в виду. Согласен, для каждого конкретного случая можно обойтись без void*, зафиксировав нужные типы в параметрах шаблонов.
Но не согласен, что void* не является полноценным элементом системы типов. Как и просто void, в шаблонах он тоже вылазит и, по слухам, там без него не обойтись. То, что void* можно использовать для обхода типизации — следствие наличия в языке низкоуровневых средств и особенностей типа «указатель на» (преобразование T*->void*->T* безопасно). Именно это средство C++ делает возможным «бескомпромиссную совместимость» с миром C и с аппаратурой, например.
Так что гордится тем, что ни разу не использовал void* не стоит: просто повезло запереть себя в «чистой комнате». Как-то так)
Впрочем, давайте с другой стороны. Почему при работе с железом нельзя обойтись без void*?
Возможно, это просто историсеское наследие, но думаю, что преобразование беззнаковых целых в указатели так или иначе включает «создание» void* из целого. Указатель ведь, по сути, структура с битовыми полями и кучей атрибутов, и на низком уровне на него накладываются ограничения, которые, ну, скажем, невыразимы в языке, по крайней мере в текущем виде. Нужен какой-то тип данных, который позволит все это делать. Я так думаю. Это может быть и не видно явно, для C и даже C++ такая спрятанная в компилятор неявность — дело обычное.
И да, указатель на байт может заменить указатель на void. Но что это даст в плане типобезопасности? Те же яйца, вид сбоку, в gnuc void* ведет себя, как byte*.
Вон сколько уже ISO/IEC TR 18037 все не примут, так и нужда пройдет.
Остался в языке для совместимости с C, видимо.
Сколько безобразного кода люди готовы написать только для того, чтобы гордо заявлять «мне void* не нужен!»… )))
И Алан Кей и Рич Хики говорят, что ещё не видели системы типов, которая бы помогала, а не мешала, и не причиняла бы боль.
Ну вы не ровняйте всех программистов с Кеем и Хикки. Им, может, и не помогает, а программистам ниже уровня — помогает вполне.
Я вот дурачок, самому думать трудно, по-этому мне часто проще, когда за меня думает тайпчекер.
Самая лучшая апологетика динамической типизации
Рассуждать о динамике вс статике сейчас имеет смысл исключительно в контексте тайскрипта. С-но, значительную часть проблем тс решает, из оставшейся части значительную часть — не решает, но оно в принципе решаемо.
Ну, если школота прямо сейчас решит задачу, которая позволит уже завтра продать продукт, то почему нет?
Потому что предпочтительнее считается смотреть не только на один день вперед, но ещё и на два, а иногда и ещё больше, например?
Если вы конечно не фрилансер, или не аутсорс контора которая не заботиться о своей репутации и стремиться выжать из заказчика денег любым способом и распрощаться
Потому что предпочтительнее считается смотреть не только на один день вперед, но ещё и на два, а иногда и ещё больше, например?Далеко не всегда. Стандартная ситуация с начинающей компанией — есть предположение что наше решение решит чью-то проблему. Можно долго создавать крутое решение, потратить кучу денег на него, а можно быстро накидать МВП и выкатить его. В случае если решение действительно нужное — да, первый вариант, скорее всего, в итоге окажется выгоднее. Если не совсем и нужно допиливать — возможно и так, и так. Если совсем нет, то, очевидно что второй вариант потратит заметно меньше ресурсов. И даже в первом случае выкатить что-то на говнокоде и допиливать потом имеет смысл. Потому что оно принесет денег вот сейчас — тех самых денег, которые нужны чтобы таки сделать хороший продукт. Совсем не факт что такие деньги на старте вообще есть.
Я что пытаюсь сказать на самом деле — заглядывать в будущее конечно хорошо и правильно, вот только никто не умеет это делать надежно. И в условиях ограниченных ресурсов вариант делать сейчас как кажется правильным, а что будет потом — будет потом, вполне может оказаться выгоднее.
Стандартная ситуация с начинающей компанией — есть предположение что наше решение решит чью-то проблему. Можно долго создавать крутое решение, потратить кучу денег на него, а можно быстро накидать МВП и выкатить его.
А речи про крутое решение за куччу денег не было, можно и MVP накидать нормально, а можно сделать уже абсолютно нерасширяемую программку.
очевидно что второй вариант потратит заметно меньше ресурсов
martinfowler.com/bliki/DesignStaminaHypothesis.html
И даже в первом случае выкатить что-то на говнокоде и допиливать потом имеет смысл
Много проектов фейлится и после этапа MVP, и при оценке рисков не стоит забывать, что после MVP мы не попадаем в сказочную страну где мы монополист на огромном рынке и гребем деньги лопатой, мы попадаем в реальность, где рядышком уже существуют 10 копий вашего бизнеса заметивших что к теме есть интерес, и пока вы будете тратить кучу времени на рефакторинг вашего MVP в попытках приспособить его к новым требованиям ловя баги с каждым релизом, конкуренты будут делать качественный и стабильный продукт, выкатывая новые фичи в срок и не ломая старый фукционал.
И в условиях ограниченных ресурсов вариант делать сейчас как кажется правильным, а что будет потом — будет потом, вполне может оказаться выгоднее.
А может совсем и не оказаться. Вопрос в том, происходит ли оценка рисков, или higest payed person/product owner считает что «так выгоднее», потому что ни капли не программист и далёк от критериев качества ПО.
Если конкуренты начинают с нуля, то и мы можем начать с нуля, уже имея своих пользователей.
Легко можно продать:
пока вы будете тратить кучу времени на рефакторинг вашего MVP в попытках приспособить его к новым требованиям ловя баги с каждым релизом, конкуренты будут делать качественный и стабильный продукт, выкатывая новые фичи в срок и не ломая старый фукционал.
:)
Может, как я и писал, можно, но я не слышал о таких success story, возможно потому что объяснять уже нужно будет не только бизнесу, а ещё и юзерам/инвесторам как-то сознаться что в продукте все не так радужно.
Возможно потому, что, опять же, дорого, конкурентов надо как-то обгонять.
Я понимаю, потому и смайлик поставил. На самом деле при разработке чего-то вроде MVP и его дальнейшем развитии я стараюсь искать баланс между скоростью и поддерживаемостью/расширяемостью/… Благо веб-разработка позволяет относительно малой кровью совмещать старый и новый код даже на разных фреймворках, языках, ОС и прочих платформах, часто всего лишь изменением конфига реверс-прокси.
конкуренты будут делать качественный и стабильный продукт, выкатывая новые фичи в срок и не ломая старый фукционал.Чтобы получилось как вы говорите нужно чтобы конкуренты умели сделать быстро и качественно то, что мы умеем либо быстро, либо качественно. В рельности же скорее всего конкуренты после нашего MVP будут все же на шаг позади. И если они начнут долго и упорно пилить идеальный продукт, то о них можно вообще не думать, к тому моменту как они закончат рынок уже будет поделен среди тех кто выкатывал быстро но не очень качественно.
Вопрос в том, происходит ли оценка рисков, или higest payed person/product owner считает что «так выгоднее», потому что ни капли не программист и далёк от критериев качества ПО.А этот вопрос вообще за рамками текущего обсуждения. То же самое может произойти в любом случае.
Ну и обычно MVP всё же часть будущего продукта, а не вещь которую скоро выкинут
Дело в том что проект и с кучей неизвестных можно сделать более менее качественным и расширяемым, и не иметь необходимости его переписывать.Я в этом не уверен. В каких-то частных случаях — наверняка. Но мне не сложно представить случай когда расширяемость будет сделана не для того и не туда для чего и куда она будет нужна. Можно попробовать запланировать расширяемость во все возможные направления, но результат будет так себе выглядеть и работать будет, скорее всего, совсем не просто. И даже так для меня не очевидно что это в принципе всегда возможно.
Анализ потока изменений имеет место быть, но при грамотном проектировании не должно происходить ситуаций требующих переписывания значительной части приложения, а в «написанном школниками на коленке» MVP — вполне себе.
Изменения изменениям рознь. И ошибки могут быть не только в проектировании, но и в постановках.
Невозможность архитектуры приспособиться к каким-либо изменениям говорит об ошибках в проектированииКонечно это ошибки. Но не потому что плохо подумали, а потому что предположили другое будущее. Невозможно создать архитектуру которую будет одновременно легко поддерживать и легко расширять вообще в любую сторону. По-крайней мере я такой архитектуры никогда не встречал. А если мы выбираем сторону куда мы предполагаем что будет расширяться приложение, то мы всегда можем ошибиться. Люди не умеют видеть будущее.
Но не потому что плохо подумали, а потому что предположили другое будущее.
Предполагать будущее — так себе затея.
Если мы пока что не предполагаем, например, что наше приложение будет использовать другие устройства ввода/вывода, это вовсе не повод забыть про абстрагирование от них, и лепить прямую зависимость из всех модулей что с i/o работают.
Я не спорю что ошибки будут всегда, проектированием мы стараемся сократить их количество, и упростить процесс их исправления.
Между случаем когда опытные разработчики хоть немного задумываются об архитектуре на MVP, и случаем, когда проект делают, как выше было сказано, «школьники на коленке», разница огромна.
Ну и время на создание MVP все же оптимизируется сокращением и упрощением фич, а не выкидыванием этапа проектирования/рефакторинга.
Предполагать будущее — так себе затея.Конечно. Именно об этом я и говорю. Но не предполагая будущего вы не сможете построить расширяемую систему. Потому что вам необходимо знать куда она должна уметь расширяться.
не выкидыванием этапа проектирования/рефакторинга.Никто не говорит про выкидывание. Но очевидно что на этот этап можно потратить разное количество времени. И достаточно очевидно что с какого-то момента дополнительное затраченное на него время будет приносить все меньше и меньше пользы, а потом даже начнет работать во вред. Вы про overengeneering когда-нибудь слышали? Термин не на пустом месте появился, его не маркетологи придумали.
Но не предполагая будущего вы не сможете построить расширяемую систему. Потому что вам необходимо знать куда она должна уметь расширяться.
Так ведь суть проектирования в том чтобы при появлении новых / изменении требований менять как можно меньше кода, для этого ведь нужны всякие DI, OCP, ISP. Подготовить почту для каки-то определыннх вариантов развития, и совершенно не учитывать другие сродни игры в русскую рулетку в которой при удаче проигрыш лишь отложиться на некоторое время.
Вы про overengeneering когда-нибудь слышали? Термин не на пустом месте появился, его не маркетологи придумали.
Да, но я не считаю что посадить на проект разработчиков, а не «школьников на коленке» — оверинжиниринг.
Так ведь суть проектирования в том чтобы при появлении новых / изменении требований менять как можно меньше кода, для этого ведь нужны всякие DI, OCP, ISP.Я не очень понимаю — вы пытаетесь сказать что всегда можно спроектировать так чтобы потом не было проблем с расширением? Или с чем именно вы спорите?
Быстро сделав прототип «тяп-ляп», мы получаем:
— возможность рекламировать что-то относительно реальное, а не «вот через 10 лет будет вау»
— Инвесторы гораздо легче одобрят что-то прототипное прямо сейчас, чем графики-картинки и сказки как будет круто
— можно набирать пользователей, получать реальную обратную связь, действительно полезные замечания внедрять сразу
— В конце концов, это даст возможность оценивать реальную нужность идеи.
Потом, когда будет первая версия, есть дизайн, некий костяк пользователей, понятно что на самом деле нужно а что шелуха, тогда нужно будет заново провести оценку решения, если надо — сменить язык, и написать нормально. Но пока нет «нормально» — придётся поддерживать прототип.
Один мой знакомый в давние времена сказал такую умную вещь: объектное программирование должно быть в голове, а не в языке.Можно ли мыслить не на языке, тем более измысливать программы и структуры данных? Просто обычно мыслят на языках программирования более высокого уровня, чем пишут код.
Много используете программ, написанных Дейкстрой? Я — ни одной.
Алгоритм Дейкстры мы все используем, когда пользуемся интернетом.
Но вообще так бывает, что гениальный человек оказывается не способен до конца понять и отвергает какие-то идеи из субъективных соображений. Вон Эйнштейн так до конца и не принял квантовую механику, хоть и сам сыграл ключевую роль в ее зарождении.
те языки и подходы, которые в итоге оказывались самыми практичными и популярными
А, например, COBOL вы в ту же категорию относите?
На COBOL крутится очень много бизнес-логики, на нём до сих пор пишут ПО. Раз его используют спецы в этой области — значит для своих задач он хорош. Мнение человека вроде Дейкстры, не имеющего опыта в энтерпрайзе, годится лишь для холиваров. Для меня вообще удивительно, что он допускал такие резкие высказывания — видимо в академической среде какая-то своя атмосфера: не шарящим студентам, лижущим тебе задницу ради оценки, всегда можно навешать на уши х*ету.
Раз его используют спецы в этой области — значит для своих задач он хорош.
Нет, не значит. Скорее это значит что так 'исторически сложилось'
Во всяком случае это решать спецам, а не холиварщикам со стороны.
То есть это очень опасный процесс, способный даже бизнесу нанести огромные проблемы, при этом профит возможен только на длинном отрезке времени, в виде ускорения разработки (но без гарантий) и в виде более «простого» рекрутинга.
Мне кажется, что ET все-таки скорее средство «быстрой разработки» численных расчетов, дающий вполне достойную, но не пиковую производительность. Может быть, требования к срокам и стоимости разработки стали жестче и теперь нельзя шлифовать код до идеала?
Я не зря написал «удобный и быстрый». Expression templates в C++ это просто кошмар какой то. Чтобы их использовать в реальных задачах нужен настоящий эксперт в С++, который потратил годы на обучение и изучение всех тонкостей языка. Это реально эзотерическое программирование. А отладка? Сообщения об ошибках в шаблонах способны заставить рыдать даже закалённого бородатого кодера. Нет, это не подходит для программирования научного кода, который обычно пишется учёными, а не профессиональными программистами. Конечно, можно нанять и их. Например у нас в организации на каждый десяток physical scientists есть один или пара computer scientists. Но оказалось, что их усилия гораздо эффективнее направить на другие методы оптимизации, например переписать под многопоточность или векторные операции, ручную оптимизацию кода наконец.
Expression templates в C++ это просто кошмар
А это вообще в реальности кто-то использует? В чем проблема использовать внешний кодогенератор?
И, спасибо clang, сообщения об ошибках уже давно весьма хороши.Они, кстати, вполне неплохи и в последних версиях gcc… но это потому что их clang заставил…
в 16 реакте мы наблюдаем феерический разворот от классов к функциональному стилю )Вы хотели сказать «к процедурному»? Тот феерический ужас, который они реализовали с useState не имеет ничего общего с фп, а просто какая-то хрень от современных ооп-хейтеров, чтобы не писать гадкое слово class
Вы хотели сказать «к процедурному»? Тот феерический ужас, который они реализовали с useState не имеет ничего общего с фп, а просто какая-то хрень от современных ооп-хейтеров, чтобы не писать гадкое слово class
Самое смешно в данной ситуации то, что useState — это, по факту, бедная реализация методов классов на замыканиях из SICP :)
То есть, вместо того, чтобы использовать нативные классы, ребята просто сделали свою параллельную костыльную ООП-подсистему.
Люди вечно путают тьюринг-полноту с возможностями языка. Так-то можно сказать что любой язык с
eval поддерживает любую, мыслимую и немыслимую, парадигму — просто потому, что он полон по Тьюрингу.В энтерпрайзе одни подходы, в академии — другие. А ещё вспоминается поговорка про плохого танцора.
Как уже написали, аргумент «раз на нем пишут, значит он хорош» очень спорный. Дейкстра может быть прав или нет по поводу COBOL, ваше право с ним не соглашаться, но для критики языка программирования не обязательно иметь какой-то особый «опыт в энтерпрайзе».Для критики вообще — да. Для критики языка применительно к энтерпрайзу, то есть критики того, насколько он этому энтерпрайзу может быть полезен — такой опыт все же необходим. Неважно насколько язык хорош или плох в его фундаментальных решениях, в бизнесе важно насколько хорошо он позволяет решать поставленные задачи и описывать бизнес процессы. И это включает в себя стоимость специалистов необходимого уровня.
На коболе просто написанно много плохого кода, который переписывать очень страшно и чревато большими простоями и рисками. Одновременно с этим на этом не лучшем языке люди не хотят писать, поэтому их заманивают большими деньгами. Ну примерно как кроссовер платит 50 баксов в час за проекты в стиле Delphi + .Net 1.1. Знаю из первых рук.
Вот так и складывается "стоимость специалистов необходимого уровня".
Много занимался корпоративным ПО на Java и все никак не могу понять о каком таком особом энтерпрайзе идет речь. Зато видел тонны плохо кода, подходов и инструментов, которые можно смело критиковать после одного взгляда ни них.Суть в том, что бизнес не очень волнует качество кода само по себе. Его волнует стоимость получения результата и, иногда, стоимость последующей поддержки и развития. И если нужен сайт визитка, который будет таким и оставаться, а при необходимости чего-то более крутого просто перепишется, то совершенно неважно какой там отстойный код напишет нанятый джун. И нанятый джун на «плохом» JS, например, будет гораздо дешевле чем нанятый джун с плюсами. Хотя бы потому что первый получит результат куда быстрее. При этом его код может быть максимально отвратителен — но кого это волнует? То есть приоритеты другие, академичность и правильность by the book могут легко быть неприменимы в бизнесе. Это не значит что обязательно будут, просто нужно понимать когда и почему они все-таки применимы. А это очень сложно сделать без опыта работы на собственно бизнес.
Сроки бизнес часто волнуют куда сильнее стоимости (в разумных пределах). Откладывание реальной эксплуатации продукта, фичи, визитки, любого ПО, разрабатываемого с коммерческими целями обычно означает откладывание увеличения доходов и(или) уменьшения расходов. С джуном же очень велики неопределенности по срокам готовности к эксплуатации, они могут стремиться к бесконечности, если джун взялся решать теоретически неразрешимую задачу :)
бизнес не очень волнует качество кода само по себе. Его волнует стоимость получения результата и, иногда, стоимость последующей поддержки и развития.Согласен.
То есть приоритеты другие, академичность и правильность by the book могут легко быть неприменимы в бизнесе.В некотором смысле да, но в то же время, в бизнесе используются инструменты и подходы рожденные в академической среде. То есть, если кто-то для простой разовой задачи начнет использовать некий академический подход требующий избыточного количества времени, то это конечно ошибка. Но вроде бы подобной массовой проблемы и нет, когда академики ломают бизнес. Зато, например, тот же джун может с пользой для себя и своей продуктивности потратить время на изучение какой-то «академической» литературы.
В некотором смысле да, но в то же время, в бизнесе используются инструменты и подходы рожденные в академической среде. То есть, если кто-то для простой разовой задачи начнет использовать некий академический подход требующий избыточного количества времени, то это конечно ошибка.Вот мой комментарий именно о том, что вот этот вот подход, на мой взгляд, и подразумевается когда говорится про отличие энтерпрайза от академических рассуждений и решений. При этом задача необязательно разовая или простая (хотя вероятнее всего именно так, но бывают разные ситуации все же). Просто иногда могут случаться всякие обстоятельства когда академический подход не сработает из-за недостатка ресурсов — времени и всего из него вытекающего (наывыка, количества рук) или денег. Например если в компании кризис и нужно срочно что-то выкатывать максимально быстро или закрываться. В таком случае выкатить что-то что внутри будет выглядеть отвратительно и будет очень тяжело поддерживать и расширять, но вот прямо сегодня, а не через месяц — вполне может оказаться лучше.
А с учётом того, что он внёс значительный вклад в разработку Алгола, который является предком подавляющего большинства современных ЯП…
Самое смешное, что goto так никуда и не делся, поскольку выходить из вложенного цикла без него ещё не научились.
Для этого перед break нужно присвоить переменную указывающую куда нужно выйти, а во внешних циклах ловить значение этой переменной, и делать break в зависимости от её значения.
А потом посчитать, насколько уродливее и тяжелее та кажущаяся «красота» на уровне human-readable абстракций…
)))
А еще можно сравнить итоговый код в машинных командах и офигеть, насколько короче и быстрее тот некошерный goto, чем Ъ и обобренный брейк… )))
Борьба с goto велась всегда с оговоркой «не используйте его без надобности». Выход из вложенных циклов — это один из немногих осмысленных кейсов goto.
Не всегда. Видел я кандидата наук, которая считала break разновидностью goto и снижала за него баллы на ЕГЭ...
Да и тут на Хабре похожие кадры попадаются.
Видел я кандидата наук, которая считала break разновидностью goto и снижала за него баллы на ЕГЭ...
Это — клиника и не лечится. Я тоже таких к.т.н. видел.
Препод зачем-то вела уравнения мат. физики. При этом ни хрена в этом не соображала. Было забавно, когда студенты исправляли косяки в ее лекциях, потому что она не втыкала где у нее ошибка.
Это — клиника и не лечится.
Может, какие светила медицины попробуют? Готов стать подопытным.
Чем break не разновидность goto?
Чем break не разновидность goto?
Тем, что бездумное использование goto — резко снижает читаемость кода. Использование break — зачастую необходимость.
Но исходно речь шла про то, что занижать оценки за использование break — глупость. Хотя остается вариант, что это интерпретация студента, и оценка была занижена за что-то осмысленное, а не за break.
Оценка была занижена потому что использование break нарушает теорему Дейкстры. Это не интерпретация, это точная цитата с апелляции.
Оценка была занижена потому что использование break нарушает теорему Дейкстры. Это не интерпретация, это точная цитата с апелляции.
Ну так вы текст программы приведите — посмотрим. Судя по всему, break как таковой ни при чем.
Там был обычный цикл с выходом по-середине:
repeat
{foo}
if {some_condition} then break;
{bar}
until false; Написать его по-другому без дублирования кода невозможно (а за дублирование кода тоже штрафуют).
Чтобы не быть голословным пример из моего солидити кода
for (uint64 i = uint64(dates.length - 1); ; i--) {
if ((!latestStatusIndex.hasValue || dates[i] > dates[latestStatusIndex.value]) && isDistributionStatus(statusCodes[i])) {
latestStatusIndex = Types.OptionU64(true, i);
}
if (i == 0) {
break;
}
}переменная i — unsigned, поэтому проверять на i < 0 в условии цикла нельзя.
uint64 i = uint64(dates.length);
do
{
--i;
if ((!latestStatusIndex.hasValue || dates[i] > dates[latestStatusIndex.value]) && isDistributionStatus(statusCodes[i])) {
latestStatusIndex = Types.OptionU64(true, i);
}
}
while (i > 0);
Если что, я не против break (и не против goto, честно говоря).
Во-первых в солидити (как и многих других языках) нет do циклов.
Во-вторых этот код сломается если dates пустой массив.
until — это противоположность while. Так что until false — это while(1).
Заданием на ЕГЭ в части С всегда является написание работающего кода, без перерасхода памяти, времени и строчек программы.
По задумке, в основном задания должны либо содержать очевидные оптимальные решения, либо возможные решения должны быть явно перечислены как правильные.
Условно, всем должно быть очевидно, что лучше добавить три строчки в программу, но выиграть в 100 раз по памяти. А если есть какая-то неоднозначность — существует апелляция.
А на самом деле на апелляции сидит "кандидат наук", сравнивающая текст программы посимвольно.
Вот это:
использование break нарушает теорему Дейкстры.
я могу трактовать как «преждевременный выход из цикла нарушает теорему Дейкстры». Т.е. претензия не к break'у, а к алгоритму. Чтобы это проверить — нужен текст программы, а вы его не привели.
Вы издеваетесь или как? Как я вам вспомню какую задачу я решал на экзамене 12 лет назад и какой код при этом написал?
И ладно бы это был самый сложный экзамен всей моей жизни, так ведь нет, это был очередной экзамен на внимательность при заполнении бланка...
я могу трактовать как «преждевременный выход из цикла нарушает теорему Дейкстры». Т.е. претензия не к break'у, а к алгоритму.
Во-первых, теорема Дейкстры на самом деле называется теоремой Бёма — Якопини.
Во-вторых, эта теорема говорит лишь о возможности приведения программы к некоторому виду, но никак не запрещает иной вид программы. Теорему невозможно "нарушить".
В-третьих, в соответствии с теоремой, любой алгоритм можно выразить в указанной форме. В том числе мой. Поэтому в этой фразе не может быть никакой претензии к алгоритму, есть лишь претензия к оператору break.
Вы издеваетесь или как? Как я вам вспомню какую задачу я решал на экзамене 12 лет назад и какой код при этом написал?
Почему издеваюсь?
1) Да, тупые преподы бывают.
2) Да, бывают студенты, которые считают, что их незаслуженно обидели.
3) При этом бывает, что обидели студента заслуженно.
4) Как я могу определить, что имело место быть на самом деле без текста программы?
5) Поскольку название алгоритма непонятное, непонятно и к чему придрался препод.
6) break используется повсеместно.
7) Наезда на языковую конструкцию в вашей цитате я не увидел.
8) Иногда преждевременный выход из цикла покрывает не все кейсы алгоритма и поэтому некорректен.
Как я могу определить, что имело место быть на самом деле без текста программы?
А слов разработчика с 8-летним стажем олимпиад и 10-летним стажем разработки вам недостаточно? Почему вы вообще взялись проводить какое-то расследование в комментариях на Хабре?
Поскольку название алгоритма непонятное, непонятно и к чему придрался препод.
А где вы вообще увидели название алгоритма?
Наезда на языковую конструкцию в вашей цитате я не увидел.
Для кого я писал комментарий выше? Эта фраза не может быть ничем кроме как наездом на языковую конструкцию.
Иногда преждевременный выход из цикла покрывает не все кейсы алгоритма и поэтому некорректен.
В таком случае мне бы сказали "алгоритм некорректно работает в таком-то случае", а не то что я цитировал выше.
А слов разработчика с 8-летним стажем олимпиад и 10-летним стажем разработки вам недостаточно?
Конечно, нет. Во первых, ошибаться / преднамеренно вводить в заблуждение может кто угодно. Во вторых, у вас на лице ваш стаж / квалификация не написаны. В третьих, на просьбу показать код последовало гениальное «begin… end», что в середине — не помню.
В четвертых, мне непонятно, чего вас колбасить начинает. Я высказал свое мнение. Не устраивает — пройдите дальше. Чего кипятиться-то?
Почему вы вообще взялись проводить какое-то расследование в комментариях на Хабре?
С того, что после моей фразы (безобидной вполне):
Хотя остается вариант, что это интерпретация студента, и оценка была занижена за что-то осмысленное, а не за break.
последовала какая-то бурная деятельность с вашей стороны.
А где вы вообще увидели название алгоритма?
«теорема Дейкстры». До букв докапываться не будем, ок? :)
Для кого я писал комментарий выше? Эта фраза не может быть ничем кроме как наездом на языковую конструкцию.
Позвольте на слово вам не поверить. Как хотите. Бодаться я не хочу, а что-то содержательное без текста программы выдать не получится.
В таком случае мне бы сказали «алгоритм некорректно работает в таком-то случае», а не то что я цитировал выше.
Ну это ВАШЕ понимание, что нужно говорить. У других людей оно может несколько отличаться. И еще раз повторю: да, я видел тупых преподов. Море. Равно как видел нормальных преподов и тупых студентов, которые считают препода тупым.
Типичный пример полезного брейка:
let user_input: u32 = loop {
if let Ok(user_input) = read_line().parse() {
break user_input;
}
println!("Неверный ввод: ожидалось беззнаковое число");
}Эксепшены забыли. :) Ну и всякие штуки вроде setjmp, отправка сигнала самому себе, прерывания и т.д.
Ну, чтобы следовать евангеле Дейкстры достатоно скопипастить весь код до брейка, а после этого запустить обычный while. Но как мне кажется, когнитивная нагрузка от такого решения вряд ли снизится. Особенно если брейков может быть больше одного. Например на каждой строчке цикла мы проверяем, что результат корректный, и если нет, то прерываем.
Вечный цикл покинуть нельзя. Если используется break это значит цикл не вечный, но условие выхода находится где-то унутре
Goto — безусловный переход.
Break — безусловный переход к любому оператору после определённого цикла.
Бездумное использование break снижает читаемость
Бездумное программирование снижает читаемость.
goto (jmp) — зачастую необходимость.
Примеры, конечно можно привести. Но, «зачастую»… В своей практике, вообще ни разу не применял goto. Кейсов таких не возникало. А вот break — постоянно.
Break — безусловный переход к любому оператору после определённого цикла.
Что значит к любому? К следующему оператору за циклом. Что обычно и требуется.
1) Как областной эксперт по проверке ЕГЭ по Информатике и ИКТ могу утверждать, что нет такой позиции в «Критериях оценивания заданий с развёрнутым ответом» (не верите — зайдите на сайт ФИПИ или загуглите демонстрационный вариант ЕГЭ, там будут критерии для экспертов).
2) Баллы — это для ЕГЭ очень много… снижение даже на 1 (один) балл требует очень веских обоснований, например, «неверная инициализация или её отсутствие там, где она необходима» или «используется неверный тип данных»
goto переключает управление в любую точку, а все эти break — только в одну конкретную точку. Другое дело, что нельзя снижать баллы за это, если только смыслом учебного курса не является достижение цели «как угодно, но только без goto».
А еще можно сравнить итоговый код в машинных командах и офигеть, насколько короче и быстрее тот некошерный goto, чем Ъ и обобренный брейк… )))Даже более. В машинных командах в любом случае будет аналог JMP операнда, который тот же Goto.
По сути, дело в абстракциях и удобстве.
Break — он не просто вызывает выход из цикла, попутно под капотом он может ещё и переменную/коллекцию освобождать.
А так-то вещь весьма удобная — вжик и вышел. А тут оказывается что надо не просто выйти а ещё и ресурсы освободить, файлы закрыть и т.д.
RAII?
Break — он не просто вызывает выход из цикла, попутно под капотом он может ещё и переменную/коллекцию освобождать.
Как он это сделает и почему в той же ситуации goto этого сделать не сможет?
Да и эксепшены по-сути эмулируют goto.
Да запросто:
for(...) {
for(...) {
if (condition) return;
}
}Да-да, цикломатическая сложность >= 2 — повод выделить этот код в отдельную функцию
Во-первых воротить отдельную функцию чисто для подцикла не делает код чище и понятнее, чем с одним goto, во-вторых — может потребоваться перейти на 2 цикла вверх или что-то подобное. А если это какая-то операция с тензорами, то отдельные функции просто для прохода каждого измерения не выглядят сильно оправданными.
Просто есть люди, которые пишут большие и некрасивые, но полезные программы, а есть люди, которые пишут маленькие и красивые, но бесполезные программы. То, что выглядит красиво и хорошо работает в последних, не работает в первых.
Методики и подходы написания надёжных программ были выработаны ещё в 80х при создании софта для SpaceShuttle и к данному моменту стандартизованы. И ключ совсем не в выборе самого лучшего языка программирования, а в организации процесса.
Основная идея в том, что если Дейкстра или кто-либо другой профессионально не писал программы для энтерпрайза и сложных систем, то не ему критиковать подходы, практикуемые там. Вроде бы очевидно, нет? Дальновидность его в области промышленного ПО можно оценить по тому, что он критиковал как раз те подходы, которые до сих пор является широко используемыми (хоть и критикуемыми), и, думаю, здесь дело не в повальной умственной отсталости тех, кто их использует. Проблема же написания качественного софта, которую Дейкстра пытался решать критикой (уровня обычного обсирания) отдельных технических подходов и языков, лежит не в плоскости языка, а в плоскости организационных подходов и методик — например таких, какие были выработаны при разработке ПО для Space Shuttle, а надёжное ПО, используемое десятки лет, можно писать хоть на ассемблере — например тот же MVS.
В 2002 году получил ежегодную премию, вручаемую Симпозиумом по принципам распределённых вычислений (англ. Symposium on Principles of Distributed Computing) Ассоциации вычислительной техники «за публикацию, оказавшую наибольшее влияние на область распределённых вычислений»; в знак признания заслуг учёного с 2003 года эта премия носит название премии Дейкстры.
Действительно, откуда ему что-то знать?)))

Какую, говорите, премию он там получил?:)
Не сказал бы, что COBOL кто-то сильно рекламировал. Скорее наоборот: такие, как Дейкстра, вели против него собственную кампанию-холивар.
Лично для меня критерий прост: чем меньше я трачу времени и усилий на создание решения, и чем больше зарабатываю на нём, тем лучше у меня подход и инструментарий. По этой причине в моей конторе ООП давно списан в утиль.
Можно не рекламировать плохую технологию, и она всё равно захватит мир, как какой-нибудь jQueryА чем jQuery — плохая технология? Для своего времени он был крайне актуальным и ушел, когда стал не нужным.
На самом деле чистый JS весьма неплохо спроектирован — атомарно и консистентно, на нём можно быстро писать эффектные прототипы. А продакшн-разработку можно вести на TypeScript.
Я перешёл на web в 2013-м. Я не никогда не занимался фронтендами для масс маркета. Мне достаточно, чтобы веб-приложение работало на одном браузере.
Но даже если думать о реализации кроссбраузерности через jQuery. Да, он даёт полезный функционал, но при этом также подсовывает очень опасную архитектуру, от которой проект сильно деградирует. Для примитивного лендинга-однодневки это нестрашно. Для сложного web-приложения это большая проблема.
но при этом также подсовывает очень опасную архитектуруНе подсовывает он никакую архитектуру. Это библиотека, а не фреймворк. Он:
1. Делает прозрачную кроссбраузерность
2. Дает более короткий, чем в браузере API
Всё. Эти вещи никак не влияют на архитектуру. На архитектуру могли влиять некоторые плагины. Но всё зависит от программиста
А что не так с отладкой кода на jQuery?
Если я буду выбирать инструмент для получения премии — я поучусь у Дейкстры, если мне понадобиться инструмент для реализации обработки транзакций — я поучусь у тех, кто её реализует.
Боюсь спросить, а какие-нибудь Дядя Боб да Фаулер для вас тоже так, академики, далекие от кода?)
Не правда ли забавно, что разработка ПО воспринимается некоторыми не как инженерная дисциплина, а как некий культ со своими еретиками и гуру? :) При этом софт всё равно часто приходится писать с использованием «плохих» (но эффективных) подходов, но открыто в этом сознаваться не принято. В тоже время никто не хочет читать давно придуманные стандарты по организации процесса разработки и методике написания качественного кода, которые существуют ещё со времён первых Шаттлов, вместо это все бросаются резкими цитатами своих любимых гуру.
Не правда ли забавно, что разработка ПО воспринимается некоторыми не как инженерная дисциплина, а как некий культ со своими еретиками и гуру?
Большинством программистов что я встречаю разработка ПО является сферой где можно работать по 4 часа в день и кучу денег получать. Благо если знают кто такие эти «гуру», и хоть краем уха слышали о чем они вещают.
А еретики это все кто вещают не про те подходы, о которых преподы в институте/на курсах, или не дай-бог какой-нибудь парень с хабра вещал, не признавать же что они чего-то не знают.
часто приходится писать с использованием «плохих» (но эффективных) подходов, но открыто в этом сознаваться не принято
В чем вы меряете эффективность боюсь спросить, и какие такие подходы считаются хорошими но неэффективными?
Не говоря уже о том, что разные подходы используются в разных ситуациях, и «гуру» которых я упоминал вполне себе вещают и про скорость, и про приоритеты.
И раз уже вы решили продолжить диалог, мне было бы интересно услышать ваш ответ на мой вопрос из предыдущего комментария.
Я прошу прощения, но дочитал до этого места становится сложно не видеть обилия Шаталов а комментариях. Шатлы изначально потрясный продукт, но шатлы это же шатлы, а шатлы шатлы шатл шатлы? Шатлы! Шатлы шатл. Шатл!
Скажите, какие походы в используете, и я объясню вам, почему они плохи.
TDD предполагает написание красного теста до изменений в коде. Что приводит либо к недопокрытию, из-за невозможности написать красный тест. Либо к нарушению TDD с написанием изначально зелёного теста, что говорит о том, что он пишется после имплементации тестируемой им функциональности.
TDD замедляет и усложняет RnD, требуя фиксации интерфейса до полного понимания какой он должен быть и реализуем ли вообще.
SRP приводит ко кратному увеличению числа объектов, что даёт излишнюю нагрузку на GC. А это критично, когда число объектов исчисляется сотнями тысяч.
OCP приводит к протуханию кодовой базы, переполнению её устаревшими реализациями, устаревших интерфейсов.
LSP говорит лишь про ковариантность типов, однако в ряде случаев типы должны быть контравариантны, а в ряде инвариантны.
ISP приводит к интерфейсам состоящим из одного метода, что нивелирует смысл интерфейсов и приводит к огромным объёмам бойлерплейта и необходимости дополнительно декларировать каждый используемый метод стороннего объекта.
DIP затрудняет навигацию по коду, усложняет API объекта, приводит к излишнему бойлерплейту.
SRP. Проблема в понимании SRP как «дроби пока дробится». Но это не так. SRP — он же принцип единой изменчивости, единой ответственности и локализации фичей — говорит про границы декомпозиции, а не про ее размер. Нарушение Srp — это не только God-object, но и размазывание и дублирование по коду какой-то конкретной фичи. Дублирование кода, как вы понимаете отнють не ускоряет даже MVP. Ежели мы касаемся вопросов оптимизации — то «преждевременная оптимизация — зло (с)». Кстати неверная декомпозиция, приводит к костылям в коде и кровавому легаси.
OCP, при нормальном проектировании необходим для выполнения SRP и тестирования. А устаревшие интерфейсы можно просто удалить. Другое дело что вы не сможете их удалить если у вас нарушен OCP, что приведет вас к кровавому легаси.
LSP говорит что наследование и полиморфизм должны быть сделаны с умом, в том числе. Везде где есть нарушение LSP — начинается задница и борьба с иерархиями. Как правило тут начинают говорить про кровавое легаси.
ISP не приводит к интерфейсам из одного метода. Аналогично SRP, ISP говорит о том как нужно делать интерфейсы в спорной ситуации, и позволяет развязать жуткие клубки зависимостей. Это крайне необходимо для больших команд, сложной бизнесс логики и ограниченных контекстов. В противном случае — ну вы поняли ;)
DIP — соглашусь. Есть доказательства того, что слепое следование DIP приводит к рекурсивному генерированию кода. Таким образом DIP это не принцип, а ползунок, пренебрегать которым не стоит ни в одну, ни в другую сторону.
Мне кажется, смысл поста вашего оппонента был в том, что любой подход может быть плохим, если его плохо готовить (бездумно следовать, как вариант) в рамках конкретного контекста.
Потому я и указал TDrivenD/TLastD что бы не нарваться на формализм.
Я ж не знал, как вы TLD расшифровываете. Я подумал, что это TLeadD.
Кстати отсутствие атомарных тестов зачастую приводит к кровавому легаси.
Не знаю, что такое "атомарные" тесты, но написать код так, чтобы он проходил один тест, но не проходил остальные, обычно сложно и бессмысленно.
Ежели мы касаемся вопросов оптимизации — то «преждевременная оптимизация — зло (с)».
Дьявол в слове "преждевременная". Архитектурная оптимизация должна выполняется как можно раньше, так как потом менять её будет сложно или даже невозможно. Это, кстати, большое заблуждение, что можно не думать о скорости, пока петух не клюнет.
Другое дело что вы не сможете их удалить если у вас нарушен OCP, что приведет вас к кровавому легаси.
Ко кровавому легаси приводит отсутствие регулярного рефакторинга. А OCP явно запрещает рефакторинг. OCP полезен лишь при взаимодействии со внешними клиентами, когда нужно сохранять обратную совместимость.
Везде где есть нарушение LSP — начинается задница и борьба с иерархиями.
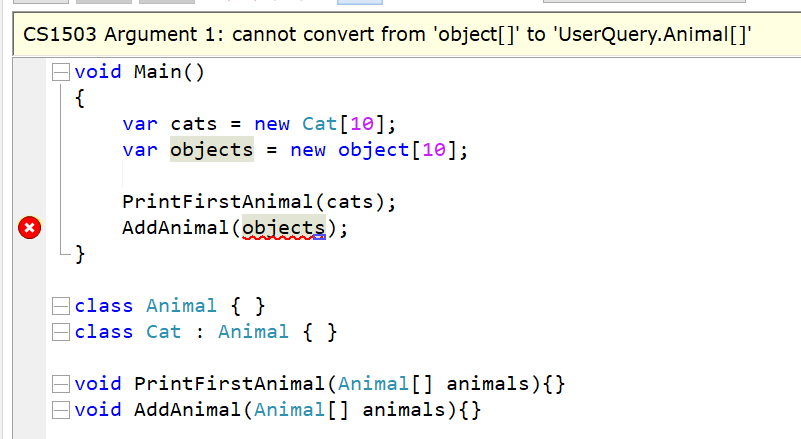
Не, вы не поняли суть проблемы. Смотрите, Cat является подтипом Animal, Cat[] является подтипом Animal[]. И если мы только читаем, то мы можем где угодно вместо Animal[] передать Cat[]. Но если мы где-то помещаем в массив, например, Dog, то, внезапно, мы уже не можем передавать Cat[] вместо Animal[]. Во времена Барбары об этой проблеме ещё не думали.
Мне понравилось определение "легаси" как кода, над которым невозможно провести полноценный рефакторинг, по факту — код, который не покрыт тестами, покрывающими требования. Даже с полным покрытием кода тестами, нельзя быть уверенным, что кто-то где-то не завязался на undefined behavior пускай и зафиксированное тестами.
undefined behavior пускай и зафиксированное тестами
Это как вообще возможно?
В требованиях нет, например, какую сумму выводить в отчёте по заказам, если ни одного пункта в заказе нет. Программист использовал какой-нибудь reduce со стартовым значением 0 и зафиксировал 0 как ожидаемое значение в тестах, хотя в требованиях этого нет, вообще ничего нет как должна вести себя системах в таких случаях, он сам принял решение, ну или с QA обсудили и решили, что это ожидаемое поведение. Но в требования оно не попало.
Не знаю, что такое «атомарные» тесты, но написать код так, чтобы он проходил один тест, но не проходил остальные, обычно сложно и бессмысленно.
«атомарные» — тестирующие минимальный объект. Я имею ввиду, что использование TDD в интеграционном ключе, тоесть тестирование больших кусков кода за раз, не тестируя маленькие — имеет тенденцию к «спецификации макарон в виде тестов». Кажется человечество еще не придумало как распутывать такие клубки.
Дьявол в слове «преждевременная». Архитектурная оптимизация должна выполняется как можно раньше, так как потом менять её будет сложно или даже невозможно. Это, кстати, большое заблуждение, что можно не думать о скорости, пока петух не клюнет.
Архитектурная «оптимизация» это хорошо, но речь про обычную, вызванную SRP. И это не заблуждение, по крайней мере если в стеке есть нормальные инструменты профайлинга. А вот экономия кол-ва типов — это кажется оскорбление чуств верующих в прекрасное, да и будущих разрабов за компанию.
Ко кровавому легаси приводит отсутствие регулярного рефакторинга. А OCP явно запрещает рефакторинг. OCP полезен лишь при взаимодействии со внешними клиентами, когда нужно сохранять обратную совместимость.
Ocp не запрещает и не поощряет рефакторинг. Он говорит что «изменение поведения кода нужно делать через… поведения-)». Иными словами — не надо хардкодить.
Не, вы не поняли суть проблемы. Смотрите, Cat является подтипом Animal, Cat[] является подтипом Animal[]. И если мы только читаем, то мы можем где угодно вместо Animal[] передать Cat[]. Но если мы где-то помещаем в массив, например, Dog, то, внезапно, мы уже не можем передавать Cat[] вместо Animal[]. Во времена Барбары об этой проблеме ещё не думали.
Либо я вас по прежнему не понял, либо вы путаете LSP и проблемы ковариантных/контравариантных преобразований и структурной типизации.
Кажется человечество еще не придумало как распутывать такие клубки.
Придумало. Компонентное тестирование называется.
SRP. И это не заблуждение, по крайней мере если в стеке есть нормальные инструменты профайлинга.
Ну вот профайлер вам показывает, что создание 100к объектов вместо 10к — это как-то сильно долго. Что вы там соптимизируете, не выпиливая SRP?
Он говорит что «изменение поведения кода нужно делать через… поведения-)». Иными словами — не надо хардкодить.
Он говорит "интерфейс закрыт для изменения, но открыт для расширения", что прямо противоречит рефакторингу.
вы путаете LSP и проблемы ковариантных/контравариантных преобразований
LSP фактически утверждает, что все типы должны быть ковариантны. Что во первых не так. А во вторых даже не является свойством типа.
Он говорит «интерфейс закрыт для изменения, но открыт для расширения», что прямо противоречит рефакторингу.Нет, не противоречит. Он говорит о том, как код должен быть написан, а не о том, как код должен писаться.
То есть он говорит о конечном результате, а не способе достижения.
Он говорит о двух глаголах в несовершенной форме, которые по семантике не могут говорить о результате. Думаю вам стоит освежить в памяти о чём этот принцип и какова его мотивация.
Принципы SOLID вообще довольно спорные, а понимают их как имели ввиду авторы вообще единицы. Интересное чтиво на тему.
Про LSP тоже интересный вопрос: должен ли список который каждый Add дублирует элемент наследоваться от обычного списка (или даже IList) или нет?
Цитата по вашей ссылке: "в результате расширения поведения сущности, не должны вноситься изменения в код, который эти сущности использует".
Код самой сущности править можно, главное — сохранять все инварианты.
Вот назвали вы метод неудачно. Что теперь, создавать новый класс с новым названием этого метода?
А кто определяет инварианты? В ФП допустим у вас все в типе возвращаемого значения зашито, а в ООП? Какие инварианты у метода ICollection.Add? Логично ли предположить, что если мы вызввали Add, то Count должен увеличиться ровно на единицу?
Вот программист и определяет. Кстати, какие инварианты определяет тип возвращаемого значения IO ()? :-)
Вот программист и определяет.
А что если один программист одно подумал, а другой-другое?
Кстати, какие инварианты определяет тип возвращаемого значения IO ()? :-)
Плохие, поэтому файнал таглес и MTL в помощь :)
А что если один программист одно подумал, а другой-другое?
Плохо будет, но это общая проблема программирования, а вовсе не проблема OCP.
Хорошо, тогда давайте по-другому: какие у нас формальные критерии соблюдения LSP? Ну вот чтобы мы могли бота написать, который на хук гитхаба срабатывает и говорит, что вот тут нарушили. Для каого-нибудь SRP можно считать количество пересечений графа ответственности и зависимостей, для open-closed насколько часто модифицируется исходный код каких-то классов. Короче, сложно, но можно.
А для LSP кроме как "я так вижу" не могу ничего придумать.
В гипотетическом формально верифицируемом ОО-языке достаточно проверить результат этой самой верификации.
В тоже гипотетической, но более приближенной к реальности ситуации, можно потребовать у использующих класс программистов оформлять свое видение инвариантов к нему в форме тестов.
А вот как вы будете формально описывать граф ответственностей — ума не приложу...
Что вы вкладываете в утверждение "все типы должны быть ковариантны"?
Не совсем по теме, но бездумное применение LSP может привести к забавным вещам. Например Java с её ковариантным array.
Функции, которые используют базовый тип, должны иметь возможность использовать подтипы базового типа, не зная об этом.
Для производных типов это означает безусловную ковариантность.
Ковариантность — свойство, которым может обладать лишь конструктор типов (дженерик), но никак не одиночный тип.
А то, что назвали вы, называется "полиморфизм".
Да нет, вас обманули. Вот смотрите, у вас есть 2 функции:
printFirstAnimal( animals : Animal[] ) — сюда можно передать Cat[], но нельзя Object[].
addAnimal( animals : Animal[] ) — сюда нельзя передать Cat[], но можно Object[].
В зависимости от того как вы работаете с типом — у него разная вариантность.
Да нет, нельзя
Несовершенство конкретного компилятора — такой себе аргумент.
По правилам языка — нельзя, а по семантике функций должно быть можно, в этом и проблема.
Собственно, поэтому в C# и появились ключевые слова in и out, чтобы объяснять компилятору где какая нужна вариантность.
Собственно, поэтому в C# и появились ключевые слова in и out, чтобы объяснять компилятору где какая нужна вариантность.
Осталось понять, при чём тут LSP...
Не везде тип может быть заменён своим подтипом. Более того, в ряде случаев он может быть заменён надтипом. Даже не знаю как ещё вам это объяснить.
Вы путаете тип и объект этого типа. LSP говорит о замене объекта, а не о замене типа.
Не заставляйте меня повторять вам определение LSP…
Давайте завязывать с этим словоблудием. Ваше уточнение ничего не меняет.
Давайте вы сами его перечитаете? И увидите, что там ничего не говорилось про дженерики, только про функции.
Можно подумать дженерики — не типы.
Дженерик — конечно же тип. А не функция.
Вот только LSP ничего не говорит про функции из типа в тип...
Именно так: LSP говорит про объекты x типа T, а вовсе не про обобщенные типы, принимающие сам тип Т как аргумент.
Рассуждения в терминах LSP для дженериков возможны, но только если мы пытаемся установить отношения подтипа для дженериков (в таком случае мы применяем LSP к самому дженерику, а не к его аргументу). Если мы не пытаемся так сделать — то и LSP тут неприменим.
Иными словами, существование инвариантного дженерика не нарушает LSP.
а вовсе не про обобщенные типы, принимающие сам тип Т как аргумент.
Когда обобщенный тип применяется к аргументу, он становится конкретным типом. И LSP тут становится напрямую применим.
Так я именно про это и написал же...
А кто из этих конкретных типов относится друг к другу как подтип?
(эта может быть та же самая ситуация, как с мутабельными кваратом и прямоугольником)
А кто из этих конкретных типов относится друг к другу как подтип?
Ну если у вас А подтип В, то List[A] подтип List[B]. примерно так.
Это применимо только для некоторых дженериков. Хотя вы и сами это знаете. Фактически по самому факту, что T подтип T1 нельзя сказать что X является подтипом для X и конкретно для List это не так.
Some kids go trick-or-treating for Halloween. They all have Bags of Candy. It's safe for them to eat anything that gets put in their Bag of Candy, because the only thing inside, by definition, is Candy.
But when they get to the end of the block, a grumpy old man who hates children begrudgingly opens the door. He looks down and sees the children all have Bags of Candy. But a Bag of Candy, he reasons, is also a Bag of Things. And the evil old man grabs a handful of RazorBlades — which are also Things — and puts them in the Bag of Things the children are holding.
Это применимо только для некоторых дженериков.
Для ковариантных. Для контравариантных — применимо наоборот. Для инвариантных неприменимо. И что, с-но?
конкретно для List это не так.
Для стандартного мутабельного списка это конечно так быть не должно, мутабельные списки должны быть инвариантными. А для иммутабельных — все окей.
Не везде тип может быть заменён своим подтипом. Более того, в ряде случаев он может быть заменён надтипом. Даже не знаю как ещё вам это объяснить.
Очень легко объяснить. В ковариантных позициях (тех, по которым генерик ковариантен) тип может быть заменен подтипом, в контравариантных позициях (тех, по который генерик контравариантен) тип может быть заменен надтипом, а в инвариантных — ничем не может быть заменен. Но вы сами это плохо понимаете.
Обе функции имеют одинаковые сигнатуры, но разную вариантность
У функций вариантности нет, вариантность есть у функционального типа (генерик Func<A, B>), и этот генерик ковариантен по первого аругменту и контравариантен по второму — всегда.
И не зацикливайтесь на генериках. Это проблема любых составных типов.
Нет, это проблема именно генериков и без генериков ее вообще не существует. Тип F: -> (генерик) называется ковариантным, если A <: B => F(A) <: F(B) и контравариантен, если A <: B => F(B) <: F(A)
Поэтому в наиболее продвинутых языках есть ключевые слова для указания вариантности аргументов.
И эти ключевые слова указывают именно вариантность генериков (типов с кондом * -> ...). У функций и аргументов вариантность указывать нельзя нигде и никак. Боле того — ни в каком языке нельзя написать ф-ю принимающую аргумент типа Т но не принимающую подтип Т (офк говорим о type safe случаях).
Компилятор мог бы вывести вариантность сам
Не мог бы, это алгоритмически неразрешимая задача.
// а сюда нельзя
В обе ф-и можно передавать Boy.
Это в каком языке так?
Если взять гипотетический нормальный язык с инвариантными массивами, то в обоих случаях в такие функции можно будет передавать только Animal[], но не Cat[] и не Object[].
А чтобы всё было так как вы расписали, функции должны выглядеть как-то так:
printFirstAnimal( animals : <? extends Animal>[] ) — сюда можно передать Cat[], но нельзя Object[]
addAnimal( animals : <? super Animal>[] ) — сюда можно передать Object[], но нельзя Cat[]
В обоих случаях вариантностью обладает анонимный тип-параметр, но никак не тип Animal.
addAnimal( animals: Animal[] ) — сюда нельзя передать Cat[], но можно Object[].
Почему?
Все ф-и коварианты по типу аргумента, в вашем случае дело в вариантности генерика [].
Обе функции имеют одинаковые сигнатуры, но разную вариантность, которая зависит не от объявленного типа, а от содержимого этих функций. Компилятор мог бы вывести вариантность сам, но мне такие не известны. Поэтому в наиболее продвинутых языках есть ключевые слова для указания вариантности аргументов.
И не зацикливайтесь на генериках. Это проблема любых составных типов.
class Man { pet : Animal }
class Boy extends Man { pet : Cat }
// сюда можно передавать Boy
declare function feedPet( man : Man ) : void
// а сюда нельзя
declare function giveDog( man : Man ) : voidВаш пример всего лишь означает, что наследование некорректное. Не вижу тут никакой контравариантности.
Ну вот профайлер вам показывает, что создание 100к объектов вместо 10к — это как-то сильно долго. Что вы там соптимизируете, не выпиливая SRP?
Прежде чем «грязнить» код — есть много других возможностей:
1) Большинство проблем происходят из O-сложности. Если O — побеждена — переходим на уровень малой крови.
2) Делаем синглтоны или кэши для часто используемых объектов, меняем ref на value типы (если позволяет инфраструктура) — итд.
3) Если и это не помогло — то часто можно упростить или реорганизовать архитектуру во благо скорости и без ущерба смыслу (на этом этапе уже понятно как).
4) Для высоконагруженных — не забываем про горизонтальное масштабирование.
И только потом, когда все вышеперечисленное не помогло — начинаем крошить код во благо скорости. Но необходимость этого встречается редко. Как правило на мобилках и ARM. И, безусловно — тут все средства хороши.
Что самое главное — предыдущие 4 пункта сложно выполнить, если у вас там все SOLID-ы порушены вкривь и вкось.
Он говорит «интерфейс закрыт для изменения, но открыт для расширения», что прямо противоречит рефакторингу.
Он говорит про изменение поведения, а не про то, что код нельзя трогать. Например — смена конекшн стринги из конфиг файла.
Или более сложный случай — вы хотите сменить одну SQL базу на другую — значит подготовьте бек-код так, что бы можно было менять провайдера DB, а не удалять старого и вместо него писать нового. Так же это говорит о том, что предпочитайте if-чикам — стратегии и композицию
LSP фактически утверждает, что все типы должны быть ковариантны. Что во первых не так. А во вторых даже не является свойством типа.
Lsp утверждает, что наследование и интерфейсы должно быть обоснованно по смыслу, а не для экономии кода. Иными словами оно против структурной типизации в языках — где структурной типизации нет, так как это лютый самострел.
Есть ощущение, что вы принципиально пытаетесь переспорить изначальный тезис, что спортивно и прикольно.
Большинство проблем происходят из O-сложности.
Это ваша личная статистика. У меня другая.
Делаем синглтоны или кэши для часто используемых объектов
Как кеши помогут вам создать 100к объектов необходимых для старта приложения?
часто можно упростить или реорганизовать архитектуру во благо скорости и без ущерба смыслу
Ага, например не лепить по 10 объектов на каждую сущность.
не забываем про горизонтальное масштабирование
Это вообще не оптимизация, а брутфорс.
И только потом, когда все вышеперечисленное не помогло — начинаем крошить код во благо скорости.
А можно изначально не создавать себе проблему во благо сомнительных аббревиатур.
Lsp утверждает, что наследование и интерфейсы должно быть обоснованно по смыслу, а не для экономии кода.
Сможете процитировать, где оно что-то такое утверждает?
Есть ощущение, что вы принципиально пытаетесь переспорить изначальный тезис
Ну а у меня ощущение, что вы уперлись рогом в свои представления и не слышите собеседника. Ведь только тролль может быть с вами не согласен, правда?
А откуда у вас возьмется 100к разных ответственностей при старте приложения?
Мы как-то расследование проводили — и обнаружили, что в Java один-единственный вызов
String.format("%0.2g", 0.1); порождает несколько сотен объектов. Добавьте сюда пачку обсуждающихся акронимов — и вы получите 100к объектов вместо нужных вам 10к легко несмотря на все кеши и прочее. Рождённых как раз всеми вот этими ускоряторами.что в Java один-единственный вызов String.format("%0.2g", 0.1); порождает несколько сотен объектов
Это вопрос уже не про SRP. А по поводу кол-ва объектов — повторюсь — SRP не про то что нужно все измельчать, а про то, как делить.
Это-таки именно о нём. Если вы посмотрите на C версию printf (вот тут, например), то вы обнаружите страшное нарушение SRP, которое любой правоверный ООПшник заменит на десятки, а то и (как видим на примере Java) сотни маленьких объектиков. В результате — то, что в C версии аллоцирует пару объектов (связанных с локалью) при первом обращении (и ничего при последующих) теперь создают 200 с лишним объектов при каждом обращении (и хорошо за 1000 при первом).что в Java один-единственный вызов String.format("%0.2g", 0.1); порождает несколько сотен объектовЭто вопрос уже не про SRP.
Вот когда ускорите Java версию так, чтобы она работала со скоростью хоть чуть-чуть приближающуюся к тому, что делает C — можете начинать петь песни о том, что вы можете вначале делать что-то с соблюдением всех этих акронимов и притом — со сравнимой эффективностью.
Но это же scanf по ссылке. Хотя да, от GNU coding style глаза сразу в кучку, различить сложно :-)
Впрочем, это не имеет отношения к SRP. Задача функции printf — сформировать в соответствии с переданным шаблоном и аргументами итоговую строку, она именно это и делает.
Вот если мы в printf засунем возможность читать данные из mysql, — это будет нарушением SRP.
Но это же scanf по ссылке.Не туда ткнул. Printf тут… но не сказал бы, что он сильно проще.
Задача функции printf — сформировать в соответствии с переданным шаблоном и аргументами итоговую строку, она именно это и делает.Ну вот разработчики Java решили что нет… и они, в некотором смысле, правы: там действительно можно выделить много подзадач. Конвертировать аргументы, переставить их по разному (вы ведь в курсе, что «Hello, World!» можно напечатать так:
printf("%3$s%2$*1$s\n", 6, "word!", "Hello"); ), обработать коллбаки (вы же в курсе, что можно дополнительные буквы зарегистрировать и дополнительный обработчик навесить) и так далее.Нельзя сказать, что все эти сотни создаваемых объектов совсем ничего не делают… но даже после долгой обработки JIT'ом там происходит куда больше работы, чем в C printf… а уж пока JIT не прогреется — там вообще караул с производительностью…
И это, ещё раз повторяю — библиотека, которой пользуются миллиарды и, вроде как, неглупыми людьми написанная. Если они не умеют в SOLID, то кто тогда умеет?
С моей точки зрения вы правы, SOLID имеет свою цену. Так же как и любое другое повышение уровня абстракции. Переход на языки высокого уровня, СУБД, библиотеки тоже имеют свою цену.
Если бы вы использовали вместо sprintf на C специально написанный для вашего случая код на ассемблере, вероятно, это заняло бы еще меньше ресурсов.
Кстати, думаю, что если на каких-то задачах sprintf является узким местом, там бы код оптимизировали возможно уйдя от SOLID.
Если бы вы использовали вместо sprintf на C специально написанный для вашего случая код на ассемблере, вероятно, это заняло бы еще меньше ресурсов.Конечно. Но вот вопрос: насколько меньше? Ответ: не так сильно меньше, чем вам кажется. Чтобы вывести 3-4 цифры в десятичной записи «наивно» — вам потребуется поделить число на 10. А это, опаньки, от 10 до 40 тактов (в зависимости от процессора). А вот
printf — этого избегает.В результате простое, наивное, приходящее в голову первым, решение, написанное на ассемблере — работает, на самом деле, медленнее, чем C printf. Что, собстенно, и делает C printf хорошей абстракцией: да, можно сделать быстрее — но это непросто. Это думать надо. И профайлить.
А вот Java printf — с этих позиций, похоже, вообще не оценивали. Даже со всеми кешами и прочими чудесами (а их там хватает, пресловутые 4 шага разработчики Java освоили неплохо) — оно всё равно работает заметно медленнее, чем пара циклов и StringBuffer.
А вот это уже, извиняюсь — никуда не годится.
Кстати, думаю, что если на каких-то задачах sprintf является узким местом, там бы код оптимизировали возможно уйдя от SOLID.Невозможно написать быстрый код «оптимизируя узкое место уйдя от SOLID». Это так не работает. То есть да, можно легко перейти от скорости в 0.1% от оптимальной к 1% от оптимальной. А вот уже даже 30%-40% получить, если у вас код в стиле фабрик-фабрик-фабрик сделан — не так-то просто.
Почему? Да потому что с 1982го года ничего принципиально не изменилось. И ваш настольный компьютер и ваш телефон — это, по прежнему, вот такой вот вот зверь, если заглянуть в микроскоп:

В нём по-прежнему разнесчастные 32KB-64KB памяти, а всё остальное — медленные свистелки и перделки.
Вылететь за 32KB-64KB памяти при использовании SOLIDного проектирования — нефиг делать. А это — сразу замедление на порядк. А если вы уже за пару мег вылетели — так там ещё один порядок будет…
А вот Java printf — с этих позиций, похоже, вообще не оценивали.
Если не оценивали за столько лет, может быть нет задач, где это является узким местом?
Невозможно написать быстрый код «оптимизируя узкое место уйдя от SOLID». Это так не работает. То есть да, можно легко перейти от скорости в 0.1% от оптимальной к 1% от оптимальной. А вот уже даже 30%-40% получить, если у вас код в стиле фабрик-фабрик-фабрик сделан — не так-то просто.
А по моему как раз наоборот, если есть SOLID то изменить начинку куска кода не меняя интерфейс проще.
SRP говорит о том, когда декомпозиция строго необходима. Достаточность же на усмотрение разработчика.
Разработчики стандартной библиотеки Java решили, что гибкость дизайна важнее производительности, вот и все.
У меня с точки зрения SRP нет претензий ни к тому, ни к другому. (Ну, к printf есть, но несущественные — можно было бы работу с буфером вынести отдельно).
Ну а у меня ощущение, что вы уперлись рогом в свои представления и не слышите собеседника. Ведь только тролль может быть с вами не согласен, правда?
Я пока слышал от вас аргументацию уровня джуниора, и «особое» понимание принципов SOLID.
Из ваших слов получается:
SRP вы воспринимаете как необходимость дробить до безумия,
OCP — запрет на редактирование кода
LSP — это о преобразование сложных типов
ISP — требует интерфейсов из одного метода
Честно я ждал от вас вдумчивых аргументов, тоскуя вечерами. А получается что вы просто не понимаете, не умеете и логично что не любите SOLID и всячески защищаете свою безграмотность.
SRP вы воспринимаете как необходимость дробить до безумия,Это не он так его понимает — это его так «правоверные ООПшники, писавшие стандартную библиотеку Java» так понимают.
Можно, конечно, сказать, что они — ничего не понимают в ООП, но… если люди, пришущие стандартную библиотеку не умеют в SRP, то… кто тогда умеет?
OCP — запрет на редактирование кодаДа, часть из этих сотен объектов рождена из OCP…
А получается что вы просто не понимаете, не умеете и логично что не любите SOLID и всячески защищаете свою безграмотность.Я ещё не видел людей, «понимающих и любящих SOLID» — и при этом способных сделать что-нибудь хоть сколько-нибудь сравнимое по эффективности решение с тем, которое могут предложить люди, «не умещие в SOLID».
Я охотно принимаю, что если постановка задачи звучит как «у нас есть 100500 индусов, не хотящих разбираться в том, что они пишут и нам нужно произвести монстра, который ну хоть как-нибудь, пусть медленно и плохо — но решает задачу», то SOLID — это отличный подход.
Но на выходе у вас всегда будет получаться большое и тормозное дерьмо… и хотя я готов признать, что «большое и тормозное дерьмо» — гораздо лучше, чем «отсутстствие работающего результата вообще», но ведь надо же понимать — какую задачу вы решаете и зачем!
Условно говоря: SOLID, это… ну не знаю — примерно способ выпекать гамбургеры в тысячах Макдональдсов по всему миру, но ни в коем случае не способ приготовления еды, которая понравится человеку, который хотя бы раз в жизни ел вкусную еду.
Для 95% задач важнее чистая и гибкая архитектура, позволяющая эффективно решать возникающие задачи и быстро реагировать на меняющиеся требования как в краткосрочной, так и в долгосрочной перспективе.
Для 5% задач, типа той же sprintf, которая используется миллионы раз, да, надо взять, написать эффективно и отлить в камне.
(Ну это, конечно, смотря какая область, если вы пишете ядро ОС или стандартную библиотеку, то там соотношение будет обратное).
Что касается стандартной библиотеки Java, скажу мягко, она во многом не пример для подражания. Надо делать скидку на середину 90-х, когда еще были иллюзии, что JIT-ом получится все оптимизировать, и даже о специализированных CPU для Джавы всерьез думали.
Для 95% задач важнее чистая и гибкая архитектура, позволяющая эффективно решать возникающие задачи и быстро реагировать на меняющиеся требования как в краткосрочной, так и в долгосрочной перспективе.Вот только фикция это: не позволяет эта «гибкая архитектура» ничего менять. Вот проводить 100500 рефакторингов — позволяет. А делать вещи, которые не сводились бы к «добавлению красненького» — нет. Вот в чём парадокс-то.
Что касается стандартной библиотеки Java, скажу мягко, она во многом не пример для подражания.Если она — «не пример для подражания», то почему ей все подражают? Ведь об этом вся статья, в принципе. А не о том, что нужно про ООП забыть и всё на чистый Pascal ISO/IEC 7185:1990 переписать…
Надо делать скидку на середину 90-х, когда еще были иллюзии, что JIT-ом получится все оптимизировать, и даже о специализированных CPU для Джавы всерьез думали.Ну тогда много о чём думали… и что компилятор вместо суперскаляра работать сможет (не смог) и что JIT сможет 100500 уровей индирекции «схлопнуть» (не умет) и что GC смогут сделать таким, что он вместо ручного распределения памяти сможет работать (не смогли: предсказуемости всё равно нет, хотя в некоторых ограниченных масштабах «цирковые трюки» и работают).
На самом-то деле самое главное, что происходило «в середине 90х» — это резкое, просто реактивное, ускорение процессоров: 486й (1й процессор, где большинство инструкций исполнялись за 1 такт) на 25MHz — это 1989й, на 50MHz — это 1991й, 1993й — это P5 (1.5 команды за такт плюс-минус и 60MHz), P54CS на 200Mhz — это 1995й, а Pentium II на 300MHz (плюс спекулятивное исполнение) — 1997й, через пару лет Katmai на 600Mhz и ещё через два года Tualatin на 1GHz с гаком.
Производительность удваивалась каждую пару лет — и под это всё и затачивалось.
А потом… оп-па: шайтан-машина издохла, славный путь к 10-20GHz (а такие планы всерьёз в конце прошлого века озвучивались!) обломался… но разработка-то ведётся в предположении, что вот-вот уже, совсем скоро, мёртвая лошадь встанет и побежит! А когда покупатели этого… добра, резонно спрашивают — почему оно всё тормозит и жрёт память «как не в себя»… то им отвечают: ну тут гибкость такая, необычайная… вы главное больше в эту гибкость верьте! То, что в конце прошлого века за пару часов разработчик мог без всяких CI и прочих мудрых слов добавить в формочку и отчёт новые данные — это всё фигня. Это вы просто «не такую» гибкость ищите. Неправильную. Там зато «дизайна» не было правильного…
P.S. Есть только одна вещь, в которую я не верил 10 лет назад, но которая сейчас реально работает: удаление «мёртвого кода». И Clang/GCC/MSVC и Java/C# и даже JavaScript движки — отлично с этим справляются (JavaScript — сносно)… при одном условии: если у вас нет вот этого вот всего SRP, OCP, DIP, ISP и прочего. Когда данные, которые используются совместно — и лежат в памяти близко. А вот как раз все эти SOLID'ные подходы устраивают в данных полный кавардак: вещи, которые используются совместно оказываются в разных местах памяти, а вещи, которые совместно почти никогда не используются — собираются в один объект.
Да, чёрт возьми, сама основа современных языков такова, что данные расположить в памяти «плотно», вообще говоря, невозможно! Вообще! Никак! Ну… если, вдруг, вас не устраивает ситуация, когда ваш огнедыщаший дракон с потреблением как доменная печь, почему-то работает медленнее, чем калькулятор, то вот вам, с барского плеча, костылик… радуйтесь.
А вот как раз все эти SOLID'ные подходы устраивают в данных полный кавардак: вещи, которые используются совместно оказываются в разных местах памяти, а вещи, которые совместно почти никогда не используются — собираются в один объект.
Выглядит как нарушение SRP как раз
printf. Что нужно, для того, чтобы вывести этот три несчастных циферьки? Разделитель тысяч, десятичную точку, информацию про набор символов (арабские цифры, настоящие арабские цифры) и так далее. И вот в соотвествии с SRP всё это у вас будет разбросано по памяти. Более того: велик шанс, что у вас класс, вставляющий разделитель тысяч будет отделён от класса, занимающегося десятичной точкой, а значит что — он будет эти данные копировать.В том-то и дело, что когда вы начинает обрабатывать данные — то вам становится нужно, чтобы данные из разных «уровней абстракций» оказались где-то рядом. А SRP требует ровно противоположного.
Как будет выглядеть SRP-почта? Ну примерно так: где-нибудь в Африке у нас много-много пакетов, куда упаковывается содержимое посылок. Там у нас живут упаковщики. А этикетки к ним печаются где-то в Северное Америке — там печатники. Проверка на вредные вещества — где-то в Австралии, а весы — в Азии. Посылка посланная на соседнюю улицу наматывает 3-4 «кругосветки».
И когда у нас возникает вопрос: «а как нам добиться того, чтобы посылка шла не полгода, а хотя бы месяц?», то, как правило, идёт выбор между строительством сверхзвуковых авиалайнром или гиперлупом.
И то и другое — дорого и, главное, не нужно: нужно просто избавиться от континента, населённого печатниками — и свести обработку посылок в одно почтовое отделение. Но это же будет нарушением SRP! У нас будут доблироваться отделы! И одно и то же будет происходить много раз! Это низззяяя!
И одно и то же будет происходить много раз! Это низззяяя!
Кто сказал что нельзя? Любые принцыпы можно нарушать, если знаешь зачем.
Разбиение на разные объекты вовсе не означает, что данные при этом обязательно должны попасть в разные места.
Ну, в Java, вроде бы, означает. Но ведь не одной только Java ООП ограничивается...
У них несколько различные свойства, но фабрики-фабрик-фабрик, без ооочень специальных усилий (доступных, пожалуй что, в полном объёме в Rust и C++, с большим трудом в C# и Go, но не в Java), породят такое количество копирований данных, что никакой профайлер вас не спасёт.
Дались вам эти фабрики фабрик фабрик… Лично я ни разу не видел ни одного оправданного SOLID наворачивания хотя бы второго уровня фабрик. Может, стоит выбрать другую дразнилку?
А «convenient proxy factory bean superclass for proxy factory beans that create only singletons» — это, увы суровая реальность (но её в Spring'е откопали уже после публикации вышеупомянутого отжига).
A. Все эти фабрики-фабрик-фабрик, SOLID, LSP и прочие «разноцветные» аббревиатуры предназначены для решения одной задачи: дать возможность человеку, который понятия не имеет о том, что делает код его менять.
B. Если эта задача для вас важна — дальше можно уже обсуждать компромиссы, нужность/ненужность «грязнить» код и прочее.
C. Если эта задача для вас не важна — то вы можете, почти всегда, написать простой и короткий код, который будет работать быстро и не будет требовать «реорганизовывать архитектуру».
D. При этом, действительно, его, зачастую, нельзя будет реорганизовать применив «предыдущие 4 пункта». И ну нужно. Если задача изменилась слегка — вы его так же слегка и поменяете. Если задача изменилась сильно — вы его выбросите и напишите новый.
Вообще же мне кажется, что вот эта патологическая война за сохранение кода приносит больше вреда, чем «преждевременная оптимизация». Потому что попылки сохранить код (за счёт «придания ему гибкости») приводят только к тому, что все проблемы, которые при создании этого кода были решены, растворяются в этой каше — и извлечь их оттуда невозможно.
Если же код изначально пишется без закладок на суперрасширяемость, то его бо́льшая часть оказывается простой (и потому её переписывание несложно), а сложности будут сконцентрированы буквально в 100-200 строчках, к которым можно и статью на 3-4 страницы дописать и объяснить, что там происходит.
Однако к теме обсуждаемой в статье всё это имеет весьма косвенное отношение: «кашу в данных» вы можете навести без всяких объектов, равно как и с применением объектов вовсе необязательно создавать «Convenient proxy factory bean superclass for proxy factory beans that create only singletons»… (google it!).
дать возможность человеку, который понятия не имеет о том, что делает код его менять.
Скорее разбить код на куски которые не будут требовать от человека понимания всего кода, чтобы его изменить — а только конкретного куска.
И да, иногда, человек, который понятия не имеет что делает данный код (без чтения кода) — это я сам через год.
И да, иногда, человек, который понятия не имеет что делает данный код (без чтения кода) — это я сам через год.Хорошо вам. Я так не умею. Код, который я писал в школе и Универе, увы, не сохранился. Но с кодом, который я писал лет 5-10 назад я периодически сталкиваюсь. И вот как раз описанного эффекта «Тут почти все лишнее. Да я даже не знаю зачем здесь половина этих API-вызовов.» у меня не возникает никогда — за исключением случаев, когда этот код меня заставили переделать, руководствуясь всякими акронимами… и в 9 случаев из 10 я не понимаю — зачем меня заставляли самому себе путать ноги тогда и не понимаю это сейчас.
см также Грабли, на которые не стоит наступатьЯ эту статью читал много лет назад, спасибо.
Но она о другом. Она о том, что не стоит выбрасывать код, который содержит, в растворённом виде, куча ценных знаний, которых в новом, переписанном с нуля, коде — не будет.
Но вот нужно ли нам стремиться любой ценой код, в котором аккумурированы все эти знания? Нужен ли нам код, позволяющей программе работать, «когда файл находится на дискете, а юзер ее выдернул посреди всего» — в программу для телефона? И полезна ли работоспособность программы в старых версиях Windows 95 в 2019м году?
Принципы, которых я придерживаюсь (и которые, собственно, конфликтуют с SOLID и многими другими акронимами):
1. Код можно и нужно переписывать. Регулярно. Требования меняются, код должен меняться тоже.
2. Не стоит пытаться за один заход переделывать компонент, который не может понять один человек.
Второй пункт, как раз, все эти SOLID'ные технологии отменяют нафиг. Если вместо отдельных компонент, которые я могу понять и упростить (а если я не могу упростить — зачем переписывать) у меня каша из тысяч отдельных сущностей, которые непонятно какую бизнес-задачу решают… то как я могу что-то в этой каше переписать?
Понимание задачи безнадёжно утоплено в потоке кода, переписать эту зачастую — просто невозможно (почему все и пытаются придумать причины этого не делать).
P.S. Кстати если вы перечитаете Джоела, то услышите там подобные же мысли: Пример: Код, отвечающий за сетевые соединения, вдруг выбрасывает из ниоткуда собственные диалоговые окна; это должно обрабатываться в коде UI. Такие проблемы могут быть исправлены по одной: аккуратным рефакторингом и изменением интерфейсов. Это может сделать один программист работая аккуратно и внедряя свои изменения целиком, никому не мешая. Здесь — тоже про «одного человека». И это — не случайно.
Для упрощения кода есть альтернатива переписыванию — рефакторинг. Постепенные маленькие, часто автоматизированные эквивалентные преобразования кода.
Но вот нужно ли нам стремиться любой ценой код, в
котором аккумурированы все эти знания?
Любой ценой не надо.
Нужен ли нам код, позволяющей программе работать, «когда файл находится на дискете, а юзер ее выдернул посреди всего» — в программу для телефона?
Не знаю. Он эта логика так же работает при вытаскивании SD-карты?
И полезна ли работоспособность программы в старых версиях Windows 95 в 2019м году?
Наверное нет, но вопрос, нет ли таких же штучек относящихся в бизнес логике? Вот вы взяли написали многостраничный текст который описывает кусочек кода. Допустим вы указали там все нюансы бизнес логики; допустим, вы абсолютно идеально вносите изменения (не забывая обновить документ и не совершая при этом ошибок) и потом решили его переписать. Так как все люди и людям свойственно ошибаться — вы же можете совершить ошибку при переписывании, а это может привести к разным последствиям зависящим от ошибки.
Кстати, посмотрите на эту статью с более взвешенным подходом к переписыванию с нуля.
Посмотрите примеры — переписывание с нуля, как правило, означает переосмысление задачи и часто вообще новый сегмент рынка — часто без выкидывание старой версии. То есть новый продукт для других людей.
Код, отвечающий за сетевые соединения, вдруг выбрасывает из ниоткуда собственные диалоговые окна; это должно обрабатываться в коде UI.
SRP?
Такие проблемы могут быть исправлены по одной: аккуратным рефакторингом и изменением интерфейсов. Это может сделать один программист работая аккуратно и внедряя свои изменения целиком, никому не мешая. Здесь — тоже про «одного человека». И это — не случайно.
Да он подчеркивает сравнительно небольшую трудоемкость рефакторинга — постепенных изменений структуры без изменения функционала.
Для упрощения кода есть альтернатива переписыванию — рефакторинг.Не очень понятно где провести границу.
Постепенные маленькие, часто автоматизированные эквивалентные преобразования кода.Что такое эквивалентное преобразование кода? Если сюда включить возможность переноса информации из одного объекта в другой — то, пожалуй, любое преобразование из мухи в слона как в известной задачке можно сделать…
Он эта логика так же работает при вытаскивании SD-карты?Нет в современных телефонах никакой SD-карты. И даже если есть — нет никаких проблем запретить её использовать.
И даже если была бы — всё равно ничего не сработало бы, так как Windows, при работе с дискетами, сообщает об ошибке при вызове функции
write, а Android — только уже при вызове функции close.Кстати, посмотрите на эту статью с более взвешенным подходом к переписыванию с нуля.А эта статья, в некотором смысла — вообще противоположность предыдущей… просто она говорит о том, что нельзя бросать старый код. А это уже немного другая история: да, прекращать поддержку существующих клиентов нельзя, когда вы занимаетесь переписыванием кода… мы снова возвращаемся к гранулярности: если у вас переписыванием кода занят один человек — то он может его переписать… или не переписать. В худшем случае — вы потереяете деньги на зарплату за какой-то промежуток времени.
А вот если вы откажитесь от поддержки старых клиентов… ну всё зависит от того — есть ли у вас конкуренты, на самом деле…
Посмотрите примеры — переписывание с нуля, как правило, означает переосмысление задачи и часто вообще новый сегмент рынка — часто без выкидывание старой версии. То есть новый продукт для других людей.Далеко не всегда. Но если вы уже делаете «новый продукт для новых людей» — то тут уж точно тянуть старый код не стоит.
Разные люди (а то и команды), я бы сказал. Если у вас весь код (с работа с сетью и UI) написан одним человеком — то в подобном подходе больших проблем не будет. А вот если этими компонентами заняты разные люди — да, тут уже приходится SRP разводить.Код, отвечающий за сетевые соединения, вдруг выбрасывает из ниоткуда собственные диалоговые окна; это должно обрабатываться в коде UI.SRP?
Что такое эквивалентное преобразование кода?
Когда функциональность не меняется а внутренняя структура меняется. Выделение методов, выделение интерфейса, добавление параметра в метод (обработка этого параметра уже не рефакторинг). Перемещение метода из класса в класс и т.д. Вообще можно поискать с примерами.
то в подобном подходе больших проблем не будет
То есть отделение UI от остального нужно только если есть две команды? А я читал что бывают еще проблемы с повторным использованием, например, того же кода с другим UI и автоматизированным тестированием. Даже если пишет один человек.
А я читал что бывают еще проблемы с повторным использованием, например, того же кода с другим UI и автоматизированным тестированием. Даже если пишет один человек.Если у вас есть много альтернативных UI и вы хотите устраивать автоматическое тестирование и прочее — то всё это резко повышает шансы на то, что вам одноного человека на всё не хватит, вот и всё.
И да, в какой-то момент приходится из-за этого выделять компоненты. Причём тут есть очень большая проблема: в тот момент, когда вы эти компоненты, всё-таки, наконец-то выделяете… сложность возрастает скачком — потому команды из 2-3 человек, работающих над одним проектом, крайне неэффективны: замедление от SOLID'ных подходов вы уже наблюдаете, а рабочей силы, чтобы скомпенсировать потери от них — ещё нет.
Я уже давно давно не работал над проектами (кроме личных) где нужен только один человек. Вы живете в каком-то другом мире — у вас все программирует один человек, он уходит в отпуск точно зная, что нет багов, ведет параллельно документацию описывающую код и не ошибается и быстродействие — единственный критерий эффективности.
У меня другие задачи.
je suis hindou.
Вы живете в каком-то другом мире — у вас все программирует один человекС чего вы взяли?
он уходит в отпуск точно зная, что нет багов, ведет параллельно документацию описывающую код и не ошибается и быстродействие — единственный критерий эффективности.О! Начались песни про то, что мы превратили компьютер, выполняющий миллиарды операций в секунду, в пишущую машинку, не способную стабильно выводить на экран пару символов в секунду — но зато забились офигительной гибкости и теперь можем создать тёмную тему всего за каких-то пару-тройку лет.
Понимаете — я ж не против SOLID. Это отличный способ для достижения разнообразных KPI и получения за это денег. И, как бы, во многих случаях — этого достаточно.
То что это не приводит к получению качественного результата — ну кого это, по большому счёту, волнует?
С чего вы взяли?
Потому, что вы рассматриваете это как основной кейз
О! Начались песни про то, что мы превратили компьютер, выполняющий миллиарды операций в секунду, в пишущую машинку, не способную стабильно выводить на экран пару символов в секунду
И рынок выбирает именно это — электрон с кучей прослоек, на не какой-нибудь редактор написанный на ассемблере.
И рынок выбирает именно это — электрон с кучей прослоек, на не какой-нибудь редактор написанный на ассемблере.Не всегда и не везде. В разных IOT ваш электрон, мягко говоря, не в почёте.
Да и даже на десктопе/телефоне: Skype ваш электрон, фактически, убил. Потому что пользоваться им стало невозможно и люди переключились на WhatsApp. Даже те, кто когда-то пользовался Skype.
Telegram, конечно, ещё шустрее и эффективнее — но вот тут уже сработал принцип «good enough»…
Не всегда и не везде
Так я и не говорю, что всегда и везде. Ничего не стоит использовать всегда и везде.
Skype ваш электрон
Даже если это так,
это только один из пяти миров.
SOLID как раз о том, как нужно писать код, чтобы его было просто переписывать. В том числе путём назначения одной сущности только одной задачи, а не создания одной сущности, которые решает все задачи, стоящие перед ИС.
Вот возьмите про тот самый «код, отвечающий за сетевые соединения, который, вдруг выбрасывает из ниоткуда собственные диалоговые окна». Пока у вас это вот так вот сделано — с нарушением всех SOLIDных принципов — добавление нового поля (скажем для одноразоывах паролей, выдаваемых вам на бумажке) это задача на пять минут. И поддержка списка пользователей, которые входили недавно… ну ещё час.
Если же вы разнесли это по разным компонентам или, не дай бог, разным библиотекам — то подобная задача может вместо пяти минут занять больше года.
А зато «поиграться с цветами» при таком подходе — гораздо проще, да.
Нужно просто отчётливо понимать, что применение любого из этих принципов — это одновременно упрощение решения некоторого класса задач и, параллельно с этим усложенение решения некоторых других видов задач.
Потому последовательность — всегда одна и та же: вначале — смотрим на бизнес-задачу, которую мы хотим решить применением того или иного принципа, потому смотрим — какова вероятность того, что её потребуется решать — а потом уже применение принципов.
Грубо говоря я готов жить с интерфейсом, который реализован в одном классе — если известно кто конкретно и когда будет делать второй.
Нет такого? Когда мы будем поддерживать сеть с посетителями на Марсе и Венере? В топку: делаем один класс и не паримся.
Поправьте меня, если я вас не понял:
— Вы — считаете что командная работа над одной задачей это плохо
— Считаете что UI-код в сетевом стеке это норм, пока его можно докостылить
— Считаете что выделение компонентов это плохой ход при котором скачком растет сложность
— Вы предпочитаете переписывание рефаторингу
— Считаете что оптимизацию нужно делать как можно раньше.
Позвольте уточнить — что именно вы делаете и на каком языке?
— Вы — считаете что командная работа над одной задачей это плохоДа, несомненно. Чем больше людей участвуют в процессе — тем хуже качество результата.
Это очень хорошо заметно в литературе: как правило книги, написанные «в соваторстве» — сильно слабее тех, которые изначально автор писал один. А интересных книг, написанных десятками авторов, я не видел вообще. Есть очень редкие случаи, когда несколько авторов работают совместно (Ильф и Петров или там Clamp какой-нибудь), но если с ними поговорить — то выяснится, что они стараются роли разделять и делать так, чтобы у каждого автора был свой, личный, кусочек.
Однако есть практическая проблема: многие современные задачи, стоящие перед IT, столь велики, что для их решения одним человеком могут потребоваться столетия.
Это делает совместную работу над одной фичей многими людьми, во многих случаях — неизбежной.
Ну и, конечно, корпорациям страшно не нравится, когда, вдруг, люди перестают быть винтиками. И они стремятся, вполне логично, продвигать культ совместной работы и любые инструменты, позволяющие изгнать из программирования личность.
То, что это снижает производительность в разы и ухудшает результат — их не очень волнует, главное, что это увеличивает управляемость.
— Считаете что UI-код в сетевом стеке это норм, пока его можно докостылитьНе «пока его можно докостылить», а «пока этим UI и этим сетевым стеком занимается один человек». Это важное отличие.
— Считаете что выделение компонентов это плохой ход при котором скачком растет сложностьИменно так. Компоненты — это неизбежное, но, тем не менее, зло. Они нужны просто потому что вы не сможете слишком большую задачу уместить себе в голову и будете в ней путаться. Ещё хуже — если у вас один и тот же код будут, без согласования, менять куча разработчиков. В этом случае лучше разделить задачу на компоненты и раздать их разным разработчикам. Так что, увы, выделение компонент при командной разработке (а сейчас почти вся разработка — командная) необходимо. Но это не делает их создание чем-то положительным.
— Вы предпочитаете переписывание рефаторингуЯ не могу ответить на этот вопрос пока не будут приведены чёткие критерии того что такое «переписывание» и что такое «рефакторинг». Например не так давно я добавлял поддержку 64-битной кодогернерации в один из модулей (изначально наш продукт поддерживал только 32-битный x86 и 32-битный ARM). В результате «git blame» показывает, что 70% кода в этом модуле теперь принадлежит мне — при этом в нём, в итоге, меньше кода, чем когда я начал с ним работать, а из десятков имевшихся там вспомогательных структур сохранились полдюжины. Однако, при этом, все изменения состояли из серии changelist'ов из которых парочка была на 300-500 строк, но большинство — не превышали 100.
Это рефакторинг или переписывание?
— Считаете что оптимизацию нужно делать как можно раньше.Вопрос не в том, «когда заниматься оптимизациями». Вопрос — «что вы можете себе позволить». Нужно просто всегда помнить, что «сложить две строки» — это дорого, «скопировать объект» — это тоже дорого, вызвать функцию — далеко не бесплатно (если компилятор не может от вызова избавиться) и так далее.
Однако иногда — вы можете себе это позволить. Например в генераторе когда — я не буду особенно бороться за то, чтобы минимизировать копирование объектов: он работает у меня на машине и даже если вместо десятой доли секунды он будет работать пять секунд — катафтрофы не случится. А вот уже если это происходит в готовой программе… то тут нужно ещё подумать — будет этот кусок кода узким местом или нет. Однако — да, об этом нужно заранее думать, до того, как вы начнёте код писать.
Ну ведь не делает же авиаконструктор самолёт как ему захочется с последующими попытками учесть влияние аэродинамики, когда уже «всё готово»? Точно так же и код нужно писать не забывая про эффективность и безопасность.
Ну а в конце — да, обдув в аэродинамической трубе, мелкий тюнинг (аналог в программировании — попытка «урвать» где-нибудь во внутреннем цикле пару тактов путём перестановки строк в коде местами). Но это — уже мелочи. Если вам нужен профайлер не для того, чтобы убедиться в том, что ваша программа ведёт себя так, как вы ожидаете, а для того, чтобы вообще понять — где у неё узкие места… то уже поздно заниматься оптимизациями…
Позвольте уточнить — что именно вы делаете и на каком языке?Язык — в основном C++ (когогенераторы на Python и Go), а что я делаю, я, пожалуй говорить не буду. Но это не натягивание «шкурок» на WordPress…
Ну ведь не делает же авиаконструктор самолёт как ему захочется с последующими попытками учесть влияние аэродинамики, когда уже «всё готово»?
Ну, обдув рассчитанных конструкций в аэродинамичексих трубах как раз про это — уесть влияние реальной аэродинамики, когда уже «всё готово»
Никто не делает самолёты так, что мы крутим-вертим, собираем всё в кучу, тестируем, а потом, когда всё уже готово — суём готовый самолёт в трубу.
Труба — используется на всех этапах. Вначале мы обдуваем маленькую модельку из дерева (да, число Рейнольдса, да это неточно — но какие-то результаты это даёт), потом — обдуваем отдельно движки и компоненты (тут не учитывается влияение компонент друг на друга — но уж лучше так, чем никак), и так далее. И да — в конце-концов мы обдуваем и целый самолёт тоже.
В программировании же, почему-то, всё делается совсем не так: вначале строится какое-то монструозное чёрт-знает-что на несколько гиг, потом — оказывается, что оно-таки тормозит и жрёт терабайт памяти (а у заказчика столько нету) и вот только тогда — запускается профайлер и делаются попытки понять — что, чёрт побери, у нас тут происходит — и куда уходят все ресурсы.
Так — это не работает. Ни эффективность, ни безопасность в программу «потом» привнести нельзя. Ну, вернее можно — но путём глубокого рефакторинга, больше похожего на переписывание…
Потому последовательность — всегда одна и та же: вначале — смотрим на бизнес-задачу, которую мы хотим решить применением того или иного принципа, потому смотрим — какова вероятность того, что её потребуется решать — а потом уже применение принципов.
Принципы типа SOLID применяются обычно не для решения конкретной бизнес-задач, а для улучшения некоторых метрик предоставляемого решения, основная из которых — сложность.
Принципы типа SOLID применяются обычно не для решения конкретной бизнес-задач, а для улучшения некоторых метрик предоставляемого решения, основная из которых — сложность.Да, из них получаются замечательные KPI, очень радующие менеджеров.
А вот по поводу качества результата… я очень хорошо помню обсуждение схем кеширования, где обсуждалось кеширования результатов валидации модуля (они присылался с удалённого сервера и нужно было убедиться, что байткод, в нём содержащийся, удовлетворяет определённым правилам). Вопрос был: может ли мы полагаться на AES-NI или нам нужно что-то другое делать (без AES-NI они в требуемые параметры никак не могли вписаться).
Я им «обломал всё малину», «написав на коленке» на выходных прототип валидатора, который работал быстрее, чем их кеш с AES-NI — чем закрыл вообще всю тему с кешом… разумеется никакого SOLID'а там не было и в помине, но нужные интерйсы написанная мною окончательная реализация поддерживала…
Причём тут KPI и менеджеры? SOLID — низкоуровневые детали кода, которые менеджмент не должны интересовать сами по себе, для них это просто инженерная практика, призванная упростить поддерживаемость кода.
Более того, манагер просят поменьше SOLID-а.То чего они просят, и то что им нужно — это разные вещи.
SOLID и тесты — зачастую единственный формализм защиты от KPI-хаосаСобственно вот, да. И ровно для этого они нужны.
Я вот сейчас другой компонент переделываю. Два месяца на «глубокий рефакторинг» ушло. Всё это время от меня почти каждый день шли CL'и. Вот только они уходили в код под
#if 0. Первый тест я смог запустить в понедельник — и в тот же понедельник заработал и последний тест тоже. Если всё будет хорошо — я завершу задачу завтра (несколько косметических правок ещё на review).Но мне это «сошло с рук» потому что менеджер меня знает — и уверен в том, что задачу я сделаю.
В противном же случае — после пары недель от меня потребовали бы начать выдавать результаты и варианта сделать эффективный код бы не было. Была бы стандартная «SOLID'ная каша».
У них «сроки-сжаты» и ХХВП их методология.Ну да. А SOLID позволяет им рисовать красивые графики и вообще душу греет. Каждый день — движуха, новые тесты добавляются, чиселки увеличиваются, работа идёт, менеджеры счастливы.
Только так — качественный код не делается.
SOLID — низкоуровневые детали кода, которые менеджмент не должны интересовать сами по себе, для них это просто инженерная практика, призванная упростить поддерживаемость кода.Ну конечно ни один менеджер не будет требовать внедрять SOLID! Они и словей-то зачастую таких не знают.
Причём тут KPI и менеджеры?Притом, что когда у вас задача «настругана в песок», то вы можете заводить таски в JIRA, рисовать красивые графики (каждый коммит ведь ускоряет работу нашего модуля, вот график — красота какая!) и прочее.
А если компонент переделывается «по уму»? Ну таски какие-то ещё как-то можно сделать. Но что делать с красивыми графиками? Поверьте мне: тот факт, что вы выпустите новый модуль, который будет в 5 или 10 раз быстрее предыдущего — очень тяжело «продать» руководству. Да, можно развести «рекламную компанию», презентации и прочее (вспоните про то, как V8 в первые годы двигался). Но это — сложно и, главное, негарантированно. Этого может хватить на месяц, два, ну три… а дальше?
Гораздо проще для менеджмента — «продавать начальству» улучшения в 2-3% каждый месяц. Даже несмотря на то, что вместо 10-кратного улучшения через пару месяцев вы получите 2-3 кратное через 2-3 года… менеджменту этот вариант куда как ближе.
Отсюда и любовь к SOLID'у «в кровавом ынтырпрайзе»: он отлично позвоялет «прикрывать задницу». А что результат — дерьмо… ну кого это волнует, в самом деле? Гравное — не допускать бунтарей вроде меня в вашу шаражку, тогда вполне можно получать хорошую зарплату за всё это от 3 до 5 лет (после этого уже обычно все ресурсы по улучшению, кроме, собственно, изменения архитектуры, оказываются «выбраны» — а её менять никто не будет, так как менеджерам это не нужно).
Есть спортивные машины, а есть гражданские. Произвести спортивную машину, в абсолютных деньгах и сложности намного дешевле и прощще чем гражданскую. И гражданских машин — 98% рынка.
К чему это я- вокруг дивный чудный мир, и львиная доля рынка занимается разработкой сложного ПО, не критичного к производительности, но критичного к функицональности. Одиночки и маленькие команды никогда не справятся с этим количеством нюансов, правок и этой динамикой рынка. И разрабатывать такое по — это искуство писать код для человека. Сделать себя взаимозаменяемым, и из этого стать дороже для рынка.
Другой пример, где читабельность выходит на первый план — Open source, где мэинтейнеру выгоден только тот реквест, который не усугубит энтропию. Максимально ясный, и покрытый тестами.
Вы приводите пример писателя и книг — но позвольте. Если вам нужно написать книгу в 10к страниц, а дополнять или изменять главы нужно раз в неделю — много вы книг издадите? Книга подобна алгоритму в программе — красивый, отточенный, согласованный. Но в программе таких алгоритмов тысячи. Современный софт, в основной своей массе нельзя сравнивать с книгами — он из них состоит.
Вы приводите пример авиаконструкторов — но их флоу обусловлен экономикой. Стоимость испытания великА а стоимость факапа — катастрофична. В софте эти стоимости почти бесплатны в сравнении. И сравните скорость развития самолоетостроения и софтвер отрасли. Софтвер отрасль развивается на порядки быстрее — в том числе из-за итеративного подхода. Иными словами — да, конструкторы делали бы итерациями если могли бы. И да — мои предки так же инженеры-конструкторы. Это имеет мало общего с современной разработкой ПО.
Безусловно есть крайние примеры легаси банкинга и физ базз интертеймент, но это точно такой же непрофессионализм как и методы по 10к строк. Две крайности.
Я вполне допускаю что конкретно вы делаете классные и специфичные вещи — это прекрасно! Мне классно что бы мы все были разными, и не греблись под одну гребенку.
Но основная масса занимается немного другими делами. Наше массовое исскуство — в читабельности и гибкости, и это отнюдь не проще чем создание алгоритма или тем более оптимизация. Не понимаете этого? Не практикуете это? Так зачем критикуете то в чем не разбираетесь?
И да, в моей практике тоже есть много кейсов, когда именно грамотное разбиение по модулям, и SOLID с unit-тестированием позволяли внедрять огромные фичи почти бесплатно, стал бы иначе я так защищать эти подходы? Я вступаю адвокатом дьявола по той причине что был по обе стороны барикад. И низко уровневой разработке втч алгоритмов и высокоуровневом процессинге высоконагруженных серверов.
Ну и в конце концов — уважьте людей. Брать в заложники заказчика своей уникальностью, это некрасиво, не профессионально и как то… низко что ли?
Доброго дня вам, и отличных задач!
К чему это я — львиная доля рынка занимается разработкой сложного ПО, не критичного к производительности, но критичного к функицональности.Вот только это не «львиная доля рынка», а «львиная доля хайпа». Если почитать Хабр, то можно решить, что Electron и JavaScript — уже захватили мир, а Java и C++ — ушли куда-то в небытьё. Однако TIOBE уверенно показывает незменную тройку: Java, C, C++ (в таком порядке).
Кто все эти люди? А это как раз embedded (C/C++) и вот этот вот суровый ынтырпрайз (Java).
Сделать себя взаимозаменяемым, и из этого стать дороже для рынка.Оно так не работает. Если вы делаете себя взаимозаменяемым — то вы становитесь дешевле, а не дороже. Отсюда — Java на первом месте: можно набрать кучу дешёвых индусов — и они, под руководством грамотного архитектора, что-то такое породят, что будет худо-бедно шевелиться.
Если будет возможность — попробуйте встать так вот, чуть сбоку, рядом с оператором, который где-нибудь в Билайн или IKEA, регистрирует что-нибудь. Почему, как вы думаете, операторы говорят с вами во время этой процедуры о чём угодно, чуть не о погоде? Потому что система, с которой они работают, ворочается так, как будто она до сих пор на IBM 402 основана.
Одиночки и маленькие команды никогда не справятся с этим количеством нюансов, правок и этой динамикой рынка. И разрабатывать такое по — это искуство писать код для человека.Нет, нет и нет. Это ПО разрабатывается не для человека. Это ПО разрабоатывается для менеджеров. SOLID отлично повышает разнообразные KPI — и с этим я даже не спорю.
Снова посмотрите на оператора ИКЕА и на систему, с которой он работает. Сказать что дизайн и эффективность там и не ночевали — ничего не сказать. Заставить нормального человека с этим ужасом общаться — невозможно… разве что за деньги… что, собственно и происходит.
А зато на разработчика — можно взять любую макаку. То, что, в конечном итоге, разработка обойдётся дороже, чем если нанять нормальных специалистов — никого не волнует: менеджер всегда может объяснить как он экономит ФОП за счёт использования всех этих SOLID'ных подходов (и действительно: все же получают копейки… экономия же) и оправдать свою высокую зарплату сложностью его работы (у меня 100 человек в отделе — конечно я заслуживаю высокую зарплату!).
Такой СССР в миниатюре — порождающий то же, что порождал и «большой» СССР.
Другой пример, где читабельность выходит на первый план — Open source, где мэинтейнеру выгоден только тот реквест, который не усугубит энтропию. Максимально ясный, и покрытый тестами.Open Source — он разные бывает. Вы когда-нибудь исходники ядра Linux видели?
Современный софт, в основной своей массе нельзя сравнивать с книгами — он из них состоит.Вашими бы устами… Современный софт, как и современные книги, это — по большей части безвкусная жвачка. Потому что критерии — не качество кода и не качество книг. А возможность на них заработать.
Как издателям не нужны шедевры (гораздо проще выгоднее продать 1000 книг по 10000 экземпляров каждую, чем вложиться в создание шедевра… который может и «не выстрелить»...), так и большинству компаний не нужны хорошие программы… им нужны дешёвые программы.
Это нормально — и с этим я особо и не спорю.
Софтвер отрасль развивается на порядки быстрее — в том числе из-за итеративного подхода.И чего ж она такого полезного развила за последние 20 лет? Да, есть интересные разработки, связанные с нейронными сеьтями и кой-какими другими интересными шутками… но вот как раз в этих областях ООП с фабриками-фабрик-фабрик и нету. Там совсем другие подходы используются.
А вот ООП, описанный в статье — это как раз для программ, которые делают всё то же самое, что делали и программы на Visual Basic или Delphi в конце прошлого века — только менее эффективно и с большими затратами как ресурсов разработчиков, там и «компьютерной техники».
Вряд ли это можно назвать прогрессом.
Не понимаете этого? Не практикуете это? Так зачем критикуете то в чем не разбираетесь?А кто вам сказал, что я в этом не разбираюсь и что я это не практиковал? Я год проработал на подобном проекте. И за этот год мы втроём успешно сделали «модуль миграции». И выполнили все KPI.
Вот только тот факт, что я, перед тем, как мы начали его разрабатывать сделал за неделю прототип на 500 строк, который всё, что нужно делал и был эффективнее, чем то, что мы, в конечном итоге, получили… меня аж никак не убедил.
Да, мой код был «неSOLIDным и нефеншуйным»… но он делал, всё, что от него требовалось — зачем был нужен год последовавшей после этого «правильной» реализации, породившей, в итоге, 50000 строк кода (почти в 100 раз больше) и спользованием Guice, модульной конфигурации и прочего? Чего мы в результате добились?
Извините — но я так и не понял… и никто из людей, с которыми я общался этого мне объяснить не смог. Все их объяснения сводились к перечислениям массы разных абревиатур и ссылкам на массу разных лекций… но никто из них так и не смог «на палтцах» объяснить — что случилось бы, если бы мы запустили миграции с тем кодом, который у меня был через неделю после начала работы.
Извините, но я сторонник Доктор Хониккера: «если ученый не умеет популярно объяснить восьмилетнему ребенку, чем он занимается, значит, он шарлатан». И вот весь этот SOLIDный рефакторинг — он сюда относится: я понимаю что и как, но я в упор не понимаю — зачем.
И да, в моей практике тоже есть много кейсов, когда именно грамотное разбиение по модулям, и SOLID с unit-тестированием позволяли внедрять огромные фичи почти бесплатно, стал бы иначе я так защищать эти подходы?Не могли бы рассказать — хотя бы схематично — что это были за «огромные фичи» и почему они требовали «SOLID с unit-тестированием»?
Ну и в конце концов — уважьте людей. Брать в заложники заказчика своей уникальностью, это некрасиво, не профессионально и как то… низко что ли?Почему «брать в заложники»? У заказчика всегда есть выбор: заплатить трём «сферическим Java-разработчикам» за три человека-года работы или заплатить мне за пару месяцев моей работы. Но какой смысл брать на работу специалиста, который может выполнить работу за два месяца и заставлять её делать таким образом, что она, в результате, она будет делаться год?
Кто все эти люди? А это как раз embedded (C/C++) и вот этот вот суровый ынтырпрайз (Java).
С ынтырпрайзом понятно, а вот где все эти миллионы вакансий под embedded на си?
С ынтырпрайзом понятно, а вот где все эти миллионы вакансий под embedded на си?В Китае в основном. Поближе к тому месту, где железо создаётся… а какой смысл деволопить embedded за тысячи километров от производства?
Embeded (24%):
C 14.243%
C++ 8.095%
asm 1.816%
Enterprise (30%):
Java 16.005%
Visual Basic .NET 5.193%
C# 3.984%
SQL 2.555%
PHP 2.489%
Действительно больше чем я ожидал. Впрочем это не касается особенно дискурса ибо Solid, безусловно не про низкоуровневую разработку
Автор, а вам знакомы такие слова: Domain Driven Development (разработка по Модели Предметной области, DDD)? ООП вообще-то это наглядный инструмент построения такой модели.
“Вам нужен был банан, но вы получили гориллу, держащую банан, и целые джунгли.”
Если вы математик, то вы работаете с абстрактным бананом, у вас какая-то своя модель, математическая, её никто уже давно не понимает. Вы гений, вас это не касается.
Если вы пишете инструмент вида DataStore\DataLoad, то вы “системный программист”. Для вас банан – это просто запись в БД. Хотя такой инструмент давно написали: ODBC (структурное, прямо по Дейкстре), OLE DB, JDBC… наконец просто SQL, текстовая строка, Execute() и получение ровсета. Вы пишете только обертки к нему. Хорошо ещё если удобные.
А если вы пишете софт, моделирующий реальные технические, экономические и социальные процессы – ну что же… Для нас банан – это объект в окружающем его мире. Как пела группа “Технология”: “Добро пожаловать в АД” (“Cкорая помощь летит на красный, но все напрасно, уже напрасно..”). Так вот, чтобы не летела на каждый чих. В любом бизнесе НУЖНА МОДЕЛЬ ПРЕДМЕТНОЙ ОБЛАСТИ.
Если вам её не дают, обратитесь к непосредственному начальнику. Если вам говорят, что её нет, не верьте. Она есть, просто кто-то должен упорядочить хаос. Есть такие люди – конструкторы, проектировщики… они как бы должны. Еще раз: вам нужна модель. Иначе вы и ваш софт умрете. Поддерживать тучу глобализмов невозможно. Либо так: надо уволиться раньше, чем он умрет.
Модель должна быть адекватной. Вспоминаем принцип Оккама – “не надо лишних сущностей”. Это ответ к пункту “Мотивирование к сложности”.
Но проблема вот в чем. Разработать модель бизнес-процесса очень сложно. Бизнес постоянно меняется и это не математика (не создали ещё такой). Математики здесь опустили лапки и сейчас предпочитают принимать зачеты у студентов в ВУЗах. Поэтому прикладным программистам приходится “как-нибудь так”, как говорила незабвенная Масяня.
На примере:
“Вам нужен был банан, но вы получили гориллу, держащую банан, и целые джунгли.”
Даже сам банан – это сложное органическое соединение, но это уже к биохимикам, они объяснят.
А в жизни банан – это элемент пищевой цепочки. Которую надо уметь моделировать, в зависимости от задачи. Моделируем обезьяну. Она съела банан. Одно дело в джунглях, а другое дело в зоопарке, эмоции обезьяны различны. Да, конечно, “съела” – это функция, а джунгли и зоопарк – это разные проги со своим набором глобализмов. Каждый раз пишем новую прогу, не устали ещё копипастить? И завтра вам сказали, что обезьяны оказывается разные – гориллы, орангутанги, макаки. А ещё бананы едят люди. Классификационный признак: люди не живут в зоопарках.
Банан может быть съеден на месте. А может быть собран и продан (агрономы, фермеры). Доставлен в Европу (логистика), да так, чтобы не сгнил по дороге (биохимия, холодильное оборудованию корабля, навигация). Продан в супермаркете (опять логистика и холодильники). И каждый этап – это деньги, а значит банковская бухгалтерия. Расплачиваемся кредитной картой (опять банк). Ура, ребята, банан у нас на столе. Мы его съели, а кожуру выбросили в мусоропровод. Мусор оттуда достали (работники ЖКХ), погрузили в мусоровоз (логистика, ремонт автопарка), отвезли на помойку. Думаете, все закончилось? Ни фига. Есть охрана окружающей среды. Помойку надо переработать, а это химия.
И любой этап – это машиностроение. Даже банки. Куда вы засовываете свою зарплатную карту? – правильно, в банкомат.
Софт нужен везде. А не только математикам, как во времена Дейкстры. И ВЕЗДЕ нужна модель предметной области. Не убедил? Пишите посты…
Другое дело, что на построении модели часто экономят трудоемкость и задание от методиста передают прямо кодерам. Нет проектирования, конструкторского этапа. Это все равно как если бы формулы расчета крыла самолета передали бы сразу на завод, без чертежей.
Поэтому модели получаются кривые и переусложненные.
А накосячить можно везде. Просто с тучей невнятных функций и глобализмов это сделать проще. Говорю так, потому что имею опыт поддержки унаследованного ПО. Даже не ПО, а ещё ПМО :-) которое прямо пришло из времен Дейкстры.
Доменная модель объектная, она оперирует отношениями сущность (объект) — связь.
Это вам так в ООП сказали. ООП не всегда нормально описывает предметную область, посмотрите хотя бы на класс Math. И не надо говорить что "ну это просто неймспейс", нет, это класс, смысла в котором нет вообще, просто джава не умеет объявлять функции на топ левеле.
Почему вы считаете, что вот после дейкстры 60 лет назад появился ООП 30 лет назад (в прикладном коде), который более прогрессивный, и с тех пор ничего не более удобного не придумали?
Java.Math — это именно нимспейс по смыслу, у него все методы static. И именно потому, что в Java отсутствуют глобальные функции (почему — не знаю). Так что это вынужденное применение конструкций ООП из-за особенностей языка.
А математика вообще странная предметная область, математика сама по себе абстрактная модель и у неё свой DDD.
Что придумали более удобное? Описание данных в виде деревьев? xml и json? Так это только данные, способ хранения и передачи свойств объектов.
Если считать, что ООП — передача сообщений между объектами, не определяя, что такое объект и что такое передача, то ничего нового и не придумают. Это определение включает вообще всё. Вот придумайте пример, который не подпадает под такое определение.
Четкого определения объекта насколько я знаю нет. Но интуитивно: объект (точнее класс) — это программное представление какой-то реальной сущности. А вот определения сущности нет ещё со времен древних греков. Хотя опять же интуитивно понятно, что это.
Посмотрите посты ниже. Я именно это и хотел сказать. Автор статьи упирает на сложность ООП-программы. Но примеры сводятся к неправильному построению доменной модели (не спроектировали). Тогда конечно, получается сложно. Хотя против классов типа DataSet автор не возражает. Так это только потому, что DataSet — программистская сущность и её может хорошо спроектировать сам программист (для себя же делает!)
Прямые вызовы методов в классическом ООП — это частный случай передачи сообщений, а не наоборот. И объект или класс совсем необязательно представление какой-то сущности предметной области. Даже по тому же DDD кроме Entity есть ValueObject как минимум: обїект, но не значение.
ООП — это способ представления программы в виде объектов определенных классов.
Классы необязательны (см. язык self, например)
ru.wikipedia.org/wiki/Прототипное_программирование:
— «Многие прототип-ориентированные системы поддерживают изменение прототипов во время выполнения программы».
— «копия наследует все характеристики своего прототипа, но с этого момента она становится самостоятельной и может быть изменена»
Это что, динамически изменяемое наследование? Вместо нынешней инкапсуляции? Может быть, когда нибудь и придет на пользу. Кто-то должен осмыслить, я пас, не математик.
А почему "математика" как таковая концептуально не объект? (то, что в java нет в языке хорошего способа описать такие объекты — не аргумент). Я даже могу себе представить инжект разных реализаций математик в разные куски кода (например, в тестовом окружении инжектить какой-нибудь логгирующий декоратор)
ООП не может выразить классы типов. Классы объектов/объекты обменивающиеся сообщениями — это абстракции слишком низкого уровня, чтобы выразить, например, монаду. Математика — это не только арифметика.
Не может выразить в прицнипе или просто в популярных языках нет поддержки и при необходимости использовать теорию типов или категорий, например, на ООП языке нужно будет реализовывать это всё ручками?
Конкретные реализации монадических структур можно сделать практически где угодно где есть обобщённые типы. Например, computation expressions в F# (это мультипарадигменный язык, включающий и ООП), в какой-то мере LINQ в C#. А вот для создания операций применимым к любой реализации монады (fmap, do-notation и т.п.) или другого класса типов, без вывода типов Хиндли — Милнера или чего-то подобного уже, по-моему, не обойтись. А такой вывод типов очень не дружит с subtyping.
В общем, похоже, что полноценная поддержка классов типов в ООП языке или невозможна или будет неудобна ни для программирования в ООП-стиле, ни для программирования в функциональном стиле.
А можно на польцах показать, почему невозможен/неудобен интерфейс IMonad?
Потому что операция bind должна вернуть не IMonad, а ровно тот же самый класс, к которому операция применялась (но с другим типом-аргументом).
К примеру, в том же C# в монаде IEnumerable операции bind соответствует метод SelectMany, а монаде Task — метод ContinueWith. А теперь попытайтесь придумать такой интерфейс, чтобы оба метода ему соответствовали, и чтобы нельзя было две принципиально разные монады случайно смешать.
Проблема, на самом деле, та же самая что и с интерфейсом ICloneable, только там её было проще не замечать.
Ага, понятно. А почему тут принципиальное противоречие с ОО, а не просто ограничения текущей реализации?
Ну, принципиального ограничения тут нет. Любой ОО-язык с динамической типизацией поддерживает монады.
А вот стандартная статическая типизация ООП (классы+интерфейсы) и правда принципиально ограничена. Возможно, в Rust что-то придумают (но им сначала надо что-то придумать с наследованием, чтобы привычное ООП стало возможным).
В расте наследования не завезут, это точно. Зачем себе проблемы выдумывать? Только чтобы потом приподнести решение?
Можно посмотреть в скале, как сделали. Весьма печально, нужно сказать, в частности вывод типов работает для списков аргументов по одному списку за раз foo(a: T, b: T) в скале написать не получится, чтобы тип вывелся, только foo(a:T)(b:T). А все из-за этого.
И какую же проблему создаст делегирование реализации указанного трейта указанному же полю?
Потому что из-за ковариантности он не сможет это вывести. А ковариантность появляется из-за наследования.
case class State[T](a: T, run: T => T) {
}
object Hello extends App {
new State(10, x => x)
}Error:(7, 17) missing parameter type
new State(10, x => x)
В языках без сабтайпинга через наследование такой проблемы не будет, к
В языках без сабтайпинга через наследование такой проблемы не будет, к
Ну так я и не предлагаю устроить сабтайпинг через наследование, необходимость явно выделять интерфейс-трейт лично меня устраивает. Все равно в силу DIP и особенностей разбиения на слои ссылки на незапечатанные классы у меня используются примерно никогда.
С дженериками должно получиться, если в языке есть типизация конструкторов. В тайпскрипте есть, про C# не уверен (вроде нет).
Я, кажется, плохо свою мысль выразил. Есть что-то в популярных ООП языках или даже самой парадигме, мешающее реализовать всю эту сложную математику? Проще говоря, можно написать вывод типов Хиндли — Милнера оперируя обычными объектами и классами, представляющими собой типы? Ну или совсем утрируя можно написать на С++ интерпретатор функционального языка с мощной системой типов?
ООП не может выразить классы типов.
Может, конечно, с чего бы нет. Формально классы типов полностью сводятся к ограниченной квантификации. Просто большинство языков позволяют делать квантификацию только по монотипам. Если таких ограничений нет (как в скале, например), то получаются тайпклассы.
Просто интеграл — это площадь фигуры, ограниченной осью X. Двойной интеграл — это площадь любой фигуры. Тройной — это объем. Это матан, коллеги, все его сдавали и сейчас сдают. Взятие интеграла — это функция (и очень сложная), а не сущность.
Матрица и вектор да, это классы языка программирования. Но это аналитическая геометрия и как всякая геометрия (измерение пространства) больше физика (такого пространства) чем абстрактный матан.
Какую такую математику надо инжектить в тесты, даже представить не могу. Если она по делу и является частью предметной области, то она уже инжекчена. А если «только для теста», то насколько адекватен тест? А если тест «умнее» предметной области, то почему её до сих пор не пересмотрели?
Взятие интеграла — это функция (и очень сложная), а не сущность.
Почему функция не может быть сущностью?
> dir(dir)
['__call__', '__class__', '__delattr__', '__dir__', '__doc__', '__eq__','__format__', '__ge__', '__getattribute__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__le__', '__lt__', '__module__', '__name__', '__ne__', '__new__', '__qualname__', '__reduce__', '__reduce_ex__', '__repr__', '__self__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', '__text_signature__']
> dir.__doc__
"dir([object]) -> list of strings\n\nIf called without an argument, return the names in the current scope.\nElse, return an alphabetized list of names comprising (some of) the attributes\nof the given object, and of attributes reachable from it.\nIf the object supplies a method named __dir__, it will be used; otherwise\nthe default dir() logic is used and returns:\n for a module object: the module's attributes.\n for a class object: its attributes, and recursively the attributes\n of its bases.\n for any other object: its attributes, its class's attributes, and\n recursively the attributes of its class's base classes."
>Какую такую математику надо инжектить в тесты, даже представить не могу.
… и прочитать в сообщении, на которое отвечаете. Кстати еще пример — в конкретном месте поменять реализации на более эффективные для него (типа вычисления через GPU)
Вот как раз DDD, по моим ощущениям, лучше всего выстреливает, когда модели предметной области нет и никто её давать не собирается просто по причине отсутствия. В этом случае она итеративно выстраивается командой разработки в постоянном взаимодействии с экспертами предметной области. DDD — это не только и не столько про технические паттерны, сколько про организацию процесса изучения домена командой разработки и по мере преобретения новых знаний и переходов на новые уровни понимания, постоянного изменения созданной ими "математической" модели и реализующего её кода (нередко модель только в виде кода и существует физически).
а примеры когда люди неправильно используют инструмент пытается выставить как недостатки инструмента.
О, раз уж вы знаете, не могли бы привести правильное использование инструмента в задаче с побитием монстров? А то у меня, навскидку, похожая же лапша получается (но хоть от объектов типа "контекст" удаётся уберечься, кроме случаев, когда они приходят извне, из фреймворков).
либо Player->hits(Monster $monster), и weapon существует тогда как property внутри player, там же можно изменить xp, либо Monster->isHitBy(Player $player), тогда наоборот, в этом методе можно получить параметры Player, и оружие и изменить его xp.
Как вы решаете в вашем проекте лучше, так и делаете, либо сверху вниз отношения, либо наоборот.
ООП — инструмент и концепция, он позволяет сделать так или эдак. Как его применить — архитектура приложения.
Если бы инструмент диктовал неизменные правила для каждого случая, это был бы жуткий черный кошмар из миллиона правил которые уже после первых тысяч трех давно противоречили друг другу и являлись списком исключений. И никто бы не пользовался таким инструментом.
Представьте себе такую ситуацию, когда нападающих разрабатывает одна команда со своими «читами» а жертву — другая. Поэтому идея отдельного класса Figt, который разрабатывается третьей нейтральной стороной не так уж плоха. Теперь правила боя определяют не заинтересованные стороны и легко проверить соблюдение правил.
Этот пример открывает лишь малую часть зла, ведь инкапсуляция вынуждает делать копии данных, преобразования данных, чтобы не пустить внешний (свой собственный чиорт возьми) код в свои кишки.
В книжках, которые вы читали по предмету объяснялось, зачем нужна инкапсуляция? Вы знаете, что инкапсуляция есть не только в ОО?
Вы знаете, что инкапсуляция есть не только в ОО?
Я знаю для чего нужна инкапсуляция, но я считаю, что ее лучше применять для более крупных блоков, нежели обычные объекты в ооп, хотя там все это будет выглядеть не органично.
В современных ОО-языках можно для каждого конкретного случая решать на каком уровне инкапсулировать, есть internal, внутренние классы, дружественные сборки и т.д.
Какие-то подробности реализации можно инкапсулировать на уровне объекта, какие-то на уровне модулей.
Ну это суть ООП, по идее. Изменение состояния объекта производится путём вызова его метода.
И отлично — это приводит к тому, что программа состоит из кусочков каждый из которых контролирует свою целостность
Я бы сделал там метод attack(Unit attacker, Unit victim), возможно, еще передавал бы тип атаки (физическая, удаленная, магическая), возможно, оружие.
метод проверяет, что оба юнита на момент начала атаки живы, что атакующий вообще может атаковать таким типом атаки и что жертва к ней чувствительна.
Если да, то производим атаку (отнимаем у агрессора силу, у жертвы — здоровье) и сетим в них новые значения этих параметров. Если жертва убита — то тут же и сообщаем об этом. Если может контратаковать — то в конце вызываем метод снова с обновленными параметрами.
Но, по большому счету, все это можно сделать и создав метод атаки (или получения атаки) у юнита… Все зависит от конкретного техзадания и от вашего чувства перкрасного,
главное, чтобы работало правильно, хорошо читалось и не просирало ремурсы зря.
Если да, то производим атаку
А что значит «производим атаку»? У вас просто меняется количество хитов у противника? Запускается анимация того, как персонаж ударяет мечом? У вас в этом методе происходит управление и моделью, и вьюшкой?
я лишь отвечал на вопрос, в котором была только самая общая инфа. поэтому и в ответе самая общая. детали надо обсуждать отдельно, причем детали требований — раньше деталей реализации.
либо Player->hits(Monster $monster), и weapon существует тогда как property внутри player, там же можно изменить xp, либо Monster->isHitBy(Player $player), тогда наоборот, в этом методе можно получить параметры Player, и оружие и изменить его xp.Необходимы оба метода. Player->hits(Monster $monster), кроме расходования патронов, вызывает внутри себя Monster->isHitBy(Player $player), в котором учитывается урон от оружия. Дальше приходим к шине событий и event-driven system.
А как вы без Environment или CombatManager будете рассчитывать урон 10 монстрам от взрыва гранаты? Кто будет вычислять, какие 10 из 20 монстров на карте надо передать в Player->hits(Monster $monster)? Вот он и будет этим CombatManager.
граната (currentWeapon) через какой-то движок отвечающий за координаты получает координаты задетых целей и наносит урон
Ну вот у вас и появился CombatManager. Только совмещенный с ответственностью гранаты. А в какое-нибудь заклинание по площади надо будет код скопировать? Наследовать заклинание от гранаты или наоборот как-то неправильно же.
Про заклинания вы правильно написали — для этого есть наследование. Только не заклинание от гранаты, а их обоих от какого-нибудь AreaEffectWeapon, куда можно вынести общий код, а различия имплементировать в дочерних классах.
А наносить урон целям это по-вашему не ответственность гранаты?
Нет, потому что граната просто разбрасывает осколки, а есть там цели или нет, и как они на осколки реагируют, ее не должно волновать. А у вас какая-то умная граната получилась, сама точку указывает, объекты запрашивает, про Playfield знает, который надо туда пробросить. Естественно, при изменениях в такой архитектуре может понадобиться все заново перепроектировать, с чем и связывают проблемы ООП. Это проблемы не ООП, а неправильной модели.
а их обоих от какого-нибудь AreaEffectWeapon
Ага, я этого и ожидал. Не делать третий класс, чтобы сделать третий класс. Клёво)
Playfield пробросить можно разными способами — это не проблема. IoC легко это решает. Пока что вам не удалось придумать изменения которые требуют все заново перепроектировать, так что модель видимо неплохая. ) И развитие модели это вполне нормально.
Ага, я этого и ожидал. Не делать третий класс, чтобы сделать третий класс. Клёво)
Цель не в том чтобы сделать меньше классов, а в том, чтобы каждый класс отвечал за свою часть работы и работу системы в целом можно было легко и наглядно увидеть (это называется ОО-декомпозиция). Есть игрок — он кидает гранаты. Есть поле, оно выдает координаты. Есть граната — она взрывается и наносит урон. Есть монстры, они получают урон. Это ООП.
Подход «у нас есть классы Player и Monster, но на самом деле каждый из них это просто набор полей, а вся логика их взаимодействия находится в классе CombatManager» по-моему не совсем ООП. Или может быть я чего-то не понимаю? Можете написать код, как вы бы в своем подходе описали пример с гранатой?
Пока что вам не удалось придумать изменения которые требуют все заново перепроектировать, так что модель видимо неплохая. )
Давайте я попробую)
Допустим у нас есть отдельные классы человек и кроган. Человек крогану наносит урон 0.5х. Все остальные комбинации (человек-человек, кроган-человек, кроган-кроган) наносят урон 1х.
protected virtual int GetAttackPower(ITarget target)
{
// При желании тут можно учесть разные эффекты от оружия и т.д.
return AttackPower;
}
public void Hit(ITarget target)
{
var attackPower = GetAttackPower(target);
// В IsHitBy можно учесть противокрогановое оружие
// и сопротивляемость разным видам урона
if (target.IsHitBy(CurrentWeapon, attackPower) <= 0)
{
// За разрушение ящиков можно XP не давать - это легко проверить если надо
XP += target.XP;
}
}В классе человек:
protected override int GetAttackPower(ITarget target)
{
var attackPower = base.GetAttackPower(target);
if (target is Krogan)
{
attackPower *= 0.5;
}
return attackPower;
}Если нужна большая гибкость, то эти правила легко вынести в какой-то отдельный файл ресурсов и брать их оттуда в методах GetAttackPower для игрока, монстра и оружия.
Что будете делать если добавим стрелковое оружие с теми же правилами? Если развивать вашу модель, то надо заводить класс Bullet, AbstractProjectile и выносить логику туда.
Насколько я понял, вы методы GetAttackPower и Hit описываете в гранате. Поэтому и вопрос, что будете делать, когда гранаты не будет, а правила останутся.
Покажите, пожалуйста, код, который вы имели в виду в случае с гранатой.
Вы вроде защищали точку зрения "наносить урон — ответственность гранаты", а теперь заявляете что метод Hit (который и вызывает нанесение урона) находится в базовом классе для Human и Krogan.
void IsHitBy(IAoeWeapon weapon, int attackPower, Point point)
{
weapon.Hit(attackPower, point)
}В классе граната, реализующей IAoeWeapon
void Hit(int attackPower, Point point)
{
var targets = Playfield.GetTargets(point);
foreach (var target in targets)
{
target.IsHitBy(this, attackPower);
}
}
В классе граната, реализующей IAoeWeapon
Но там нет ничего, что хоть как-то зависит от параметров гранаты, все передается снаружи, в том числе и PlayField, который этот метод вызывает. Почему PlayField не может вызывать свой собственный метод GetTargets? Он ведь уже знает, что оружие это IAoeWeapon. Хотя там радиус еще должен быть, который характеристика гранаты, но почему тогда attackPower передается в гранату снаружи?
C# это, и в нем не юзается ничего магического вроде, то же самое на котлине или прости господи джаве можно написать точно так же.
Простите, но где вы тут слабую типизацию увидели?..
Статичность-динамичность и строгость-слабость ортогональны друг другу. Python например язык с сильной динамической типизацией.
Где мы тут динамическую типизацию увидели? Очень надеюсь, что не в var. И при чем тут windows only?
Я перечитал 3 раза сообщение, и понял, что нихрена не понял. Затем пошли раговоры про питон и лекция про отличия слабой и динамической типизацией… вааат?
Да нет, не ошибся, это в продолжение https://habr.com/ru/post/451982/#comment_20177778, просто чуть дальше читанул.
Не все слабо типизированные языки являются динамически типизированными: PHP — это динамически типизированный язык, но вот C — тоже язык со слабой типизацией — воистину статически типизирован.
В C# ключевое слово var точно так же назначает переменной конкретный тип, который в дальнейшем переназначить не получится.
Вот по ссылке:
Сильно типизированный язык — это такой язык, в котором переменные привязаны к конкретным типам данных, и который выдаст ошибку типизации в случае несовпадения ожидаемого и фактического типов — когда бы не проводилась проверка.
…
Тем не менее, Ruby, Python и JavaScript (все они обладaют динамической типизацией) также являются сильно типизированными, хотя разработчику и не нужно указывать тип переменной при объявлении.
Сильная типизация она не про var vs int, она, грубо говоря, про невозможность вычислить 1+"1"
Тем не менее, Ruby, Python и JavaScript (все они обладaют динамической типизацией) также являются сильно типизированными, хотя разработчику и не нужно указывать тип переменной при объявлении.
Речь идет именно о присвоении (объявлении) типов, а не дальнейших операциях с ними (которые «вычислить 1+«1»»). Кстати это, к слову, раздел почему понятия статики/динамики и силы/слабости не дождественны как иногда считается.
Когда JavaScript называют сильно типизированным языком, моя рука тянется к {} + [] === 0.
Хаскель у вас тоже динамический?
x = 5
x = 6
foo :: Integer -> Integer
foo a =
b where
b = x * 2Это динамика? Я про первые 2 строки
Осталось понять, почему мы должны верить тексту по вашей ссылке...
Был бы он выложен на Хабре — были бы там мои комментарии. В которых было бы написано то же самое что тут пишут вам: используемые термины имеют совсем другие определения.
Как минимум я ссылку подвергаю сомнению ввиду того, что в ней считают JavaScript сильно типизированным, а PHP — слабо, при этом приводя для PHP в подтверждение пример, тривиально переносимый в JavaScript, пусть и с иным значением на выходе. При том, что в указанных там же Python и Ruby этот же пример поведёт себя принципиально иначе (а именно, вызовет ошибку типизации). Где, собственно, граница?
Этот текст, очень, скажем так, художественный. Общепринято, что в статических языках тип переменных известен на этапе статанализа (грубо — компиляции), а в динамических становится известен в рантайме. Как он становится известен — дело десятое. Это может быть явное объявление, может быть автоматический вывод типов из выражения инициализации в конструкции объявления переменной, специального синтаксиса для объявления переменной может вообще не быть, а тип определяется "во время" первого присваивания значения.
Она вызывает все тот же Monster.IsHitBy.
Но в реальности граната не знает ничего ни про каких монстров. Зачем делать заведомо неправильную модель, и потом решать проблемы, которые из-за этого возникают?
Точку указывает не граната сама, а игрок, когда ее кидает.
Ну а как же она тогда будет вызывать метод объекта Playfield? Она знает координаты, и по вашим словам туда их передает. Неважно, кто ей их сообщил, важно что она с ними работает.
Пока что вам не удалось придумать изменения которые требуют все заново перепроектировать, так что модель видимо неплохая.
Так я и не придумывал, мы все еще про гранату говорим) У вас надо добавлять общие интерфейсы у точки на карте и гранаты, делать кучу иерархий AreaEffectWeapon, BulletWeapon, ClubWeapon, по которым будет разбросана физика, пробрасывать Playfield во все из них. И все для того, чтобы не делать выделенный класс с нужной ответственностью. А теперь допустим появляется требование добавить спецэффекты типа "граната не взорвалась, но попала монстру по башке, и он потерял сознание". А у нас в ней повреждение по area рассчитывается, а повреждение при прямом контакте рассчитывается в иерархии ClubWeapon. Теперь надо гранату от ClubWeapon наследовать?
а не CombatManager, который знает все обо всех и спокойно меняет состояние любых объектов нарушая инкапсуляцию
Стоп, я нигде не говорил, что он меняет состояние любых объектов. В моем примере объект Environment отправляет сообщения своим под-объектам, которые являются наследниками класса Environment (или более общего) и потому знают физику игры и меняют свои параметры в соответствии с ними, и возможно передают модифицированное сообщение своим под-объектам.
Например, игрок отправляет сообщение в Environment "Бросаю гранату типа G в точку X". Environment определяет радиус через G.calculateRadius(), определяет все объекты MonsterBody в этом радиусе от точки X, опеределяет силу взрыва через G.calcualtePower(), для каждого объекта расчитывает P в зависимости от расстояния и отправляет сообщение "Осколок гранаты силой P", каждый MonsterBodу меняет свои характеристики в соответствии с законами физики. Environment может иметь в составе компоненты для разных стихий или типов оружия, которые и делают конкретные расчеты, у объектов Monster есть ссылка на MonsterBody с доступом на чтение характеристик и к методам управления, Monster и MonsterBody могут иметь разные иерархии наследования или вообще их не иметь, а делать все через композицию. Возвращаясь к примеру с невзорвавшейся гранатой, если G.calcualtePower() вернула 0, то Environment берет массу гранаты G.getMass(), вызывает код, которые рассчитывает урон для холодного оружия, проверяет, есть ли какой-то объект конкретно в точке X, если есть отправляет ему сообщение "Камень массой M". Инкапсуляция не нарушена, нет никаких ограничений на наследование, новые правила боя добавляются без изменений архитектуры.
Но в реальности граната не знает ничего ни про каких монстров. Зачем делать заведомо неправильную модель, и потом решать проблемы, которые из-за этого возникают?
Граната знает радиус своего поражения и влияет на объекты, которые в него попадают — монстры, здания и любые другие ITarget. По-моему это более естетственная модель чем некий CombatManager, который всем управляет. Разве что это бог войны какой-то. )
Ну а как же она тогда будет вызывать метод объекта Playfield? Она знает координаты, и по вашим словам туда их передает. Неважно, кто ей их сообщил, важно что она с ними работает.
Не понял в чем проблема. Граната получает координаты взрыва от игрока, когда он ее кидает и окружающие объекты от Playfield когда взрывается.
Так я и не придумывал, мы все еще про гранату говорим) У вас надо добавлять общие интерфейсы у точки на карте и гранаты, делать кучу иерархий AreaEffectWeapon, BulletWeapon, ClubWeapon, по которым будет разбросана физика, пробрасывать Playfield во все из них. И все для того, чтобы не делать выделенный класс с нужной ответственностью.
Общий интерфейс с точкой на карте возможно не лучшее решение — в этом случае в принципе можно и добавить Environment для AOE эффектов, его унаследовать от ITarget и туда передавать координаты, например. Но общая идея именно в том, чтобы разбросать логику по тем классам к которым она относится. Правила взрыва — в гранате, получение урона — в монстре и т.д. вместо одного огромного класса который через некоторое время станет очень болезненно поддерживать. В зависимости от изменений модели — можно делать рефакторинг и добавлять классы, переносить логику из одного класса в другой и т.д. Но по крайней мере есть модель из которой понятно что как работает.
А теперь допустим появляется требование добавить спецэффекты типа «граната не взорвалась, но попала монстру по башке, и он потерял сознание». А у нас в ней повреждение по area рассчитывается, а повреждение при прямом контакте рассчитывается в иерархии ClubWeapon. Теперь надо гранату от ClubWeapon наследовать?
Зачем? Если она такое умеет — можно в ней же эту логику и описать.
Например, игрок отправляет сообщение в Environment «Бросаю гранату типа G в точку X». Environment определяет радиус через G.calculateRadius(), определяет все объекты MonsterBody в этом радиусе от точки X, опеределяет силу взрыва через G.calcualtePower(), для каждого объекта расчитывает P в зависимости от расстояния и отправляет сообщение «Осколок гранаты силой P», каждый MonsterBodу меняет свои характеристики в соответствии с законами физики. Environment может иметь в составе компоненты для разных стихий или типов оружия, которые и делают конкретные расчеты, у объектов Monster есть ссылка на MonsterBody с доступом на чтение характеристик и к методам управления, Monster и MonsterBody могут иметь разные иерархии наследования или вообще их не иметь, а делать все через композицию. Возвращаясь к примеру с невзорвавшейся гранатой, если G.calcualtePower() вернула 0, то Environment берет массу гранаты G.getMass(), вызывает код, которые рассчитывает урон для холодного оружия, проверяет, есть ли какой-то объект конкретно в точке X, если есть отправляет ему сообщение «Камень массой M». Инкапсуляция не нарушена, нет никаких ограничений на наследование, новые правила боя добавляются без изменений архитектуры.
Ок, можно сделать большой Composite как вы предлагаете или какую-то шину сообщений, но засовывать туда всю логику неправильно. Если у вас Environment активно вызывает G.calculateRadius(), G.calcualtePower(), а потом G.getMass(), то по-моему это явный признак того, что этой логике место в G (сорри за каламбур).
Граната знает радиус своего поражения и влияет на объекты, которые в него попадают — монстры, здания и любые другие ITarget. По-моему это более естетственная модель
Она не знает ни про какие объекты, она просто разбрасывает осколки. Есть там объекты, или нет, или они были на границе радиуса и сдвинулись после взрыва и осколки до них не долетели, ей без разницы. Какая же это естественная модель, если поведением куска железа вдруг становится передача координат и получение целей.
Не понял в чем проблема. Граната получает координаты взрыва от игрока, когда он ее кидает и окружающие объекты от Playfield когда взрывается.
В том, что в реальности так не происходит. У вас неправильная модель, которая сразу ведет к усложнению кода и потенциально к проблемам при изменениях.
Правила взрыва — в гранате, получение урона — в монстре
Так взрываться могут не только гранаты. Бензобак автомобиля может взорваться, его тоже от оружия наследовать? Получение урона у меня тоже в монстре, вернее в его физической части, а не в самом объекте Environment.
вместо одного огромного класса
Откуда огромный класс-то? Что мешает его разделить на более мелкие? Просто они не будут совмещаться с иерархией типов оружия, не нужен никакой ITarget, который надо вводить заранее, или переделывать готовые классы если не заранее, не нужен рефакторинг при изменениях требований, все гораздо проще, и точнее моделирует предметную область.
Зачем? Если она такое умеет — можно в ней же эту логику и описать.
Так копипаста же. В ClubWeapon уже есть этот код.
Если у вас Environment активно вызывает G.calculateRadius(), G.calcualtePower(), а потом G.getMass(), то по-моему это явный признак того, что этой логике место в G
Так она и к другим объектам обращается, про которые G ничего не знает. В том-то и дело, мы же с этого и начинали. А еще могут быть всякие расчеты, связанные с формой окружающих предметов (монстр в радиусе поражения, но спрятался за бетонной стеной), с защитными полями определенного типа на поверхности карты (которые не связаны с конкретным субъектом) и т.д. Это, как я понимаю, должно быть в Playfield, который список целей отдает? Ну вот и появился Environment.
Правила взрыва — в гранате,
Граната ещё от PlayField получает информацию о том, где она взорвалась — на земле, в воздухе, в воде, в вакууме, в закрытом или открытом пространстве, при какой гравитации и атмосферном давлении и всё это обсчитывает?
CombatManager, который знает все обо всех и спокойно меняет состояние любых объектов нарушая инкапсуляцию.
Нет, CombatManager — это просто такой "мастер игры", который следит за игровым полем, положением игроков, событиями, рассчитывает взаимные траектории исходя из игровой физики и раздаёт указания: "ты получил осколок гранаты в бедро", "ты ранен копьём в шею" и т.п. Он не меняет состояния игровых объектов напрямую, он занимается координацией и енфорсит правила боя.
Примерно как на конвентах всяких реконструкторов: там машут безвредными деревянными мечами и тупыми копьями, никто друг друга по-настоящему не убивает, но есть мастер, который делает это рукомашество и дрыгоножество игрой, в которой персонажи умирают.
Примерно как на конвентах всяких реконструкторов: там машут безвредными деревянными мечами и тупыми копьями, никто друг друга по-настоящему не убивает, но есть мастер, который делает это рукомашество и дрыгоножество игрой, в которой персонажи умирают.Не надо только привносить опыт управления людьми в программы.
Ничего хорошим это не кончается потому что они слишком разные: у человека есть здравый смысл и он может «додумать», а зато он может и передать приказ неправильно или «творчески переосмыслить его».
Потому при управлении людьми «цепочки управления» должны быть как можно короче, иначе начинается испорченный телефон, а при написании программ — они быть как можно проще, потому что чем больше информации вы передаёте, тем меньше вы делаете чего-то полезного с теми же ресурсами.
На мой взляд, проще если персонажи и игровые артефакты отвечают исключительно за своё собственное состояние и не пытаются влиять на состояние других объектов, тем самым размазывая логику игры тонким слоем по всем объектам. Т.е. та же обсуждаемая граната не должна знать, кому и в каких условиях какой урон она наносит, она должна лишь выдать задержку взрыва, бризантность, осколочность и т.п., а решать, какой от неё реальный радиус и эффект поражения при взрыве на земле, в воздухе, в воде, за деревом, за стеной, за бронёй, за силовым полем — это дело того, кто отвечает за логику игрового мира, за его физику и правила игры. Тогда, скажем, переход персонажа с поверхности Земли под воду или на поверхность Луны сведётся к замене физического движка, а не к переписыванию эффектов в каждом виде вооружения.
А наносить урон целям это по-вашему не ответственность гранаты?
Ответственность гранаты — взорваться, то есть создать соответствующий АОЕ-эффект и благополучно исчезнуть.
Ну да, так и есть. Вызывать Monster.IsHitBy в окрестностях и все.
Нет, граната монстров не бьет, она создает АОЕ. А потом уже все монстры, попавшие в АОЕ { actor: playerId, source: grenadeId, position: {...}, area: {...}, effects: [{ type: Effects.DAMAGE, damageType: Damage.STAB, target: Targets.ALL,' value: X, ticks: 1, delayBefore: 0, delayBetween: 0,… }], ...} получают эффект в соответствии с этим АОЕ.
Еще можно передавать в монстра damagedata вместо игрока, с количеством и типом урона, чтобы повреждения мог наносить не только игрок
Я думаю, правильно будет, если объект Player передает сообщение с заданными параметрами объекту Environment, а Environment уже сама распределяет чего и куда. В простом случае это сообщение целиком уходит объекту Monster, в более сложном можно например рассчитывать урон взрыва от расстояния. Environment это не столько окружающее пространство, сколько законы физики (игры) в целом.
Лучше если физические параметры Monster cможет менять только Environment, а не сам Monster. Можно сделать отдельный объект MonsterBody, который является частью Environment, а у Monster доступ только на чтение. Environment распределяет сообщение по всем своим составляющим в виде сообщений с меньшими характеристиками, составляющие тоже знают законы физики, возможно даже являются наследниками класса Environment, и при получении сообщения меняют свои параметры или в свою очередь передают своим составляющим.
Тот факт, что ущербная версия, которая была реализована в Simula 67 из соображений эффективности… считается единственно правильной версией… ну не знаю…
Вы повторили то же самое что написано в статье и точно также не дали ответа, а только запутали. И нет, не существует иерархии между monster и player в общем случае. А с точки зрения данных и их преобразования и понятий-то таких нет.
Не знаю, насколько мой вариант "правильный" с точки зрения ООП.
На мой взгляд лучше завести класс CombatManager у которого нужно вызывать условный attackEventHandler(attacker, victim). Ну а внутри уже учитывать хитпойнты, силу атаки, защиту, опыт, оружие и все остальное. Можно даже вызвать какие-нибудь методы класса Player и Monster вроде onAttackSucceed, onAttackMisses.
Проблема ООП в том, что методы пытаются представить как действия субъекта. В то время как методы это дейстия над объектом.
Методы это не действия над объектом, объект это штука которая обладает каким-либо поведением, вот его методы это описание того, что мы можем сказать ему сделать.
Если у нас есть класс менеджер который принимает в себя два объекта и что-то рассчитывает на основе этих объектов, объекты превращаются просто в структуры данных (поле+геттеры), а логика утекает а менеджер. Это нарушение инкапсуляции
В вашем первом предложении, тезис
Методы это не действия над объектом
противоречит тезису
, объект это штука которая обладает каким-либо поведением, вот его методы это описание того, что мы можем сказать ему сделать.
Инкапсуляция это когда объект знает только про себя и не дает никому другому знать о себе. Вы ведь так это понимаете?
Если мы будем говорить объекту (допустим Player) "сделай ка что-нибудь над другим объектом (допустим Monster)", то для этого объекту Player нужно что-то знать об объекте Monster. То есть Monster даст возможность кому-то другому знать о себе. Вот это нарушение инкапсуляции.
Вместо "CombatManager" можно описать класс "Rule". Потому что только правила игры знают как правильно менять объекты, участвующие во взаимодействии.
Пример нарушения:
class Manager{
fun someFunc(Target t, Player p) {
if(p->getWeaponDamage >= t.getDefenceValue) {
// do smth...
}
}
}
Логика в классе менеджере зависит от данных находящихся в объектах.
Если мы будем говорить объекту (допустим Player) «сделай ка что-нибудь над другим объектом (допустим Monster)», то для этого объекту Player нужно что-то знать об объекте Monster. То есть Monster даст возможность кому-то другому знать о себе. Вот это нарушение инкапсуляции.
Объект Player может сказать что-то объекту Monster, а объект Monster решает что ему с этим уже делать. Напрямую изменить состояние, данные внутри объекта Monster, объект Player не может
Почему нарушение то?
функция getWeaponDamage у вас ведь находится в классе Player, а не в Manager.
Вот если бы вы написали
class Manager {
fun getWeaponDamage(Player p){return p.damage;}
fun getDefenceValue(Target t){ return t.defence;}
fun processAttack(Target t, Player p){
if(getWeaponDamage(p) >= getDefenceValue(t)) {
// do smth...
}}}Вот тогда мы бы нарушили инкапсуляцию потому что функция по работе с данными (полями классов Player и Target) были бы отделены от этих данных.
Почему нарушение то?
Потому что геттер возвращает данные из объекта, а логика работы с этими данными находится в другом объекте.
weaponDamage это не данные принадлежащие классу-менеджеру. Это данные принадлежащие, в примере выше, объекту Player.
Вы путаете логику работы С данными (т.е. чтение, использование их) от логики работы НАД данными (т.е. изменение, модификацию).
Если ни один объект вообще никак не будет давать читать свои данные никому другому, у вас просто программы не получится. Если вы перенесете логику боя из CombatManager в Player, то в вашем понимании неизбежно нарушите инкапсуляцию класса Monster. Он ведь отдает свои данные кому-то.
Вопрос в том, насколько внешний мир способен модифицировать внутренние данные объекта.
Когда мы пишем геттер Player::getWeaponDamage, то можем как угодно вычислять этот самый урон. Варианты: хранить в поле, проходиться по списку шмоток и искать сумму бонусов на урон.
Внешний мир об этом не узнает и напрямую повлиять не сможет. Только через специальные методы, которые мы можем контролировать.
Ну и теперь уже можно и класс Manager выкинуть, и cделать свободную функциию processDamage(Target p, Player p, GameState s), чтобы не рефакторить Manager каждый раз когда для расчета урона понадобится новая фаза луны.
Заодно и голову не надо ломать кому же эта функция должна (должна ли?) принадлежать. И, скажем, ИИ сможет подсчитать какой-же урон будет при гипотетическом GameState s1.
А в императивном коде как?Неинтересно подсказывать вам решение) Но, обещаю, когда вы предложите свое — я вам расскажу, как это обычно делается.
Можно вывести набор функций, которые ставят некую анимацию в соответствие изменению каждой переменной. Будет анимация на изменение level, на изменение xpНельзя, это будет бажная неюзабельная игра. Наивный подход как в Реакте тут не работает. Да, модель изменилась, вьюшка должна об этом узнать. Но измениться вьюшка должна не мгновенно в ответ на модель, а через анимации.
Вот представьте, вы делаете удар игроком.
В модели это выглядит так:
1. У игрока запустился кулдаун до следующего удара
2. У монстра отнялись жизни и он умер
3. Из него на землю выпал лут
4. Игроку начислились монеты
Конечно, ваш подход подойдет для какого-то рогалика без анимаций. Ты нажал кнопку и вот уже новый стейт. Но в нормальной игре на такое действие будет следующая реакция:
1. Сначала игрок замахивается мечом в течении 10-30 кадров зависимо от оружия
2. Потом в определенный момент запускается анимация нанесения урону персонажа, а так же из него вылетают цифры, которые указывают, сколько урона ты ему нанес
3. Потом еще кадров 10 спустя — запускается анимация смерти, в этот момент (и ни кадром раньше) у игрока запускается анимация начисления денег, а так же из монстра начинает вылетать и падает на землю лут.
При этом модель обновилась, провалидировала и отправила все изменения на сервер ещё в первый кадр этой анимации.
мне нужно будет написать полноценную систему, что несколько выходит за рамки усилийПросто вы не знаете, как это сделать (особенно на фп, там и я не знаю). Я вот могу написать в небольшом сообщении отлично работающее решение, которое применяется на практике.
А почему вы считаете, что такая проблема вообще возникнет?Ну потому что я разрабатываю игры и знаю, какие там стоят задачи. И прекрасно знаю, насколько сложно решать подобные задачи на реакте, который реализует тот подход, о котором вы говорите.
отвечающей за расчёт состояний, притягивать что-то там про анимации, вообще очень многое говорит о типичном месиве ООП.
Проблема вашего предложения, что оно сугубо теоретическое и неюзабельное на практике. Нет никакой сложности написать
monster.hp -= 100 и даже на обычном процедурном программировании оно будет работать. Вот только как вьюшка потом узнает, почему у этого монстра хп изменилось? Вот изменилось хп и все. А почему? То ли из-за яда? Или заклинание на него наложили? Или мечом ударили?Вы, как типичный плохой коллега говорите:
— Это не моя область, в модели хп меняется, я уехал в отпуск а вы…

А программисты, пока вы в отпуске, выкидывают ваш теоретический код и пишут код, который работает.
А программисты, пока вы в отпуске, выкидывают ваш теоретический код и пишут код, который работает.
Были у нас такие "погромисты", которые навертели ADO.Net поверх энтити фреймворка пока автор кода был в отпуске, потому что не поняли, нахрена там все эти атрибуты, модели и UoW.
Теперь снова ваша очередь говорить вещи, которые не несут никакой полезной информации и вообще не в тему.
Вы усложнили модель, но это не влечет никаких особых изменений. Ну будет вместе с хп передаваться тип урона, разница-то какая? Анимация та же ничего не решает.
Какое-то время назад была серия статей "как программисты хлеб пекли", там на всех языках включая чуть ли не фортран разобрали, как последовательно программа меняется, обрастая требованиями. От вашего добавления анимаций или еще чего принципиально ничего не меняется.
Ну будет вместе с хп передаваться тип урона, разница-то какая?И что, что тип урона? Ну вот урон от спелла. И что это даст? Кто этот спел наложил? Вот изменилось количество монет у пользователя — в результате какого действия? Из-за удара? Или смерти персонажа? После смерти какого персонажа? А если от гранаты умерло 5 персонажей и от каждого капнуло 20 монет и нам надо это отобразить — вот вылетели с монстра эти монеты.
От вашего добавления анимаций или еще чего принципиально ничего не меняется.Суть в том, что ваше решение — плохое. Вы стараетесь как-то, костылем его подпереть, а потом через три месяца у вас будет неподдерживаемый продукт. И дело не в том, что какой-то фичи не хватает, у вас ядро гнилое.
Потому что в реакте, который до вас никто не упоминал, криво сделали, или почему?Тот подход, который вы описали активно используется в реакте и его я привел только как пример. В любом фреймворке, где вьюшка реактивно реагирует на модель будут такие проблемы.
как нам на ООП-подходе с этими плеерами и монстрами организовать походы в пати, чтобы на всех участников капало.А в чем проблема? Вы о сложностях работы по сети? Они есть независимо от парадигмы.
Ну будет вместе с хп передаваться тип урона, разница-то какая?О! И кстати, куда будет передавать тип урона? Записываться в модель? Только последний? А если вьюшке, то как туда будет передаваться тип урона? Там просто поменялись хитпоинты. Это даже непонятно от урона ли. Может просто на персонаже висел бафф на +100 к хп и теперь он пропал. Это ведь не урон уже.
От вашего добавления анимаций или еще чего принципиально ничего не меняется.Анимация — всё ерунда, конечно. А вот если типов монстров сотни, поведение — гибкое, изменения — частые. Вот тут неерунда начнется.
attack(hero, monster) на практике совершенно не работает. Ну то есть функция, которая просто напрямую меняет модель — совершенно неюзабельная в данном контексте.То есть, функции, которая по герою и монстру вычисляет новое состояние, в предлагаемом вами подходе нет, и она размазана лапшой по коду с анимациями, валидациями и отправками на сервер?Конечно же у меня ничего подобного нету. У меня — крайне четкое разделение ответственности, модель и вьюшка совершенно независимы. А вот у вас, когда появится вьюшка — будет лапша
Немного оффтоп.
Как вы понимаете, что из XP -> XP -> Animation это аргументы функции, а что — результат?
makeAnimationCoins :: Coins -> Coins -> Animation
mВот к примеру нагуглил первый попавшийся пример — крайне простая казуальная игра, смотрите где-то на 2:00

У вас просто стало 256 монеток вместо 200. Как это функция поймет — почему и какую именно анимацию надо создать?
Вот у меня значение, представляющего старое состояние монстра, вот — новое. Этого недостаточно?Конечно недостаточно. У вас не хватает информации о причинно-наследственной связи, что деньги добавились из-за появления монстра. У вас два независимых факта — монстр умер. У игрока изменились деньги. Это факты совершенно независимы.
Если у вас в монстре нет достаточной информации о том. что это за монстр, чтобы к нему анимацию привязать, то вам и ООП не поможет.У меня как раз информации достаточно. А у вас — нет.
{
player: { gold: 200 },
monsters: [
{ id: 1, isDead: false },
{ id: 2, isDead: false },
{ id: 3, isDead: false },
{ id: 4, isDead: false },
{ id: 5, isDead: false },
]
}
// ==>
{
player: { gold: 256 },
monsters: [
{ id: 1, isDead: true },
{ id: 2, isDead: true },
{ id: 3, isDead: true },
{ id: 4, isDead: false },
{ id: 5, isDead: false },
]
}
У вас есть независимые факты:
1. Умер монстр 1
2. Умер монстр 2
3. Умер монстр 3
4. Изменилось количество золота у игрока
Но у вас нет информации о том, сколько над каждым из монстров голды необходимо нарисовать
Если монстры равноценные, то информация есть: 3 монстра умерло, 6 монет прибавилось, итого 2 монеты с каждого монстра.
Если монстры имеют разный "вес", то у вас состояния не полны, не хватает стоимостей жизни монстров.
UPD: Сорри, там +56 монет, и на 56 на 3 не делится. Значит вам наверняка придётся использовать monster.id чтобы получить информацию о "весе" каждого монстра.
Или другой вариант. У вас в стейте на монстре висит эффект из-за которого монет именно и дается больше, но при смерти эффект с монстра спадает. Да, это эффект был в старом стейте, но в новом — уже нету. Вы будете проверять и старый и новый стейт?
Что, если вы получаете на 10 монет больше за каждого 10 монстра?
Или или вопрос значительно проще, который я уже задавал — что, если это была цепная молния — как вы её отобразите? Ну нету в стейте инфы, почему умерли эти персонажи — то ли файрбол в них попал, то ли молния цепная, а может и от старости умерли. Просто в прошлом стейте они были живы, а сейчас — они мертвы.
Это "костыль" лишь потому, что вы не удосужились положить в стейт достаточно информации, и её приходиться довычислять. Нужно учитывать kill-streak или давать бонус за каждого 10-й kill? Сделайте эту информацию доступной, например, храните в состоянии историю побед игрока. Нужно учитывать, как умерли персонажи — сохраняйте информацию об обстоятельствах смерти. Ну, например, слегка переделав ваш пример:
{
player: {
gold: 256,
xp: 9001,
hp: 100500,
kills: [
<... previous kills ...>,
{ id: 1, with: "lightning", time: 12345 },
{ id: 2, with: "lightning", time: 12345 },
{ id: 3, with: "lightning", time: 12345 }
],
},
monsters: [
{ id: 1, lvl: 25, hp: 0 },
{ id: 2, lvl: 25, hp: 0 },
{ id: 3, lvl: 6, hp: 0 },
{ id: 4, lvl: 50, hp: 100 },
{ id: 5, lvl: 20, hp: 500 },
]
}— и вот внезапно у нас есть всё, чтобы вычислить и монетки, и способ убийства (равно как и связать несколько убийств в цепочку), и бонус за стрейк, и бонус за общее число побед.
Вы будете проверять и старый и новый стейт?
Блин, ну а зачем нам оба стейта, если мы их не собираемся сравнивать? Конечно же будем! Смысл анимации — плавная интерполяция между двумя состояниями, значит нам по-любому нужно из нового состояния вычесть старое (что и означает "сравнить"), и все полученные отличия так или иначе интерполировать.
kills: [ <... previous kills ...>, { id: 1, with: "lightning", time: 12345 }, { id: 2, with: "lightning", time: 12345 }, { id: 3, with: "lightning", time: 12345 } ], },
Стоп. А они умерли от одной цепной молнии, или от трех разных? А если персонаж этой цепной молнией убил первого и третьего, а второго только ранил. У вас к массиву killed ещё появится массив wounded? Time — это вообще интересное. Откуда эта вьюшная деталь взялась в модели?
А они умерли от одной цепной молнии, или от трех разных?
Они умерли в одно и то же время от одного и того же оружия, и это оружие позволяет "убийство по цепочке", так что нетрудно вывести, кто от чего помер. Если этого недостаточно — кто вам запрещает добавлять в стейт больше деталей, например, добавить id оружия/удара?
А если персонаж этой цепной молнией убил первого и третьего, а второго только ранил
Ну, добавьте монстру массив зарегистрированных травм. Заодно получите новую возможность: монстры могут постепенно излечиваться, и скорость восстановления будет зависеть от нанесённых ему травм. Скажем, электротравма от молнии зарастает за 10 шагов, а колотая рана — за 20.
Time — это вообще интересное. Откуда эта вьюшная деталь взялась в модели?
Time — не вьюшная деталь, она позволяет 1) коррелировать события между собой, 2) вычислять бонусы за стрики (скажем, 5 убийств за 10 секунд => streak bonus), 3) вычислять или ограничивать kill rate и т.п.
На игроке висит «проклятие» — за каждое действие, которое он совершает — он получает spellLevel*10 урона. Ну если он не джин, который получает от проклятия в два раза меньше урона. А ассасин получает от спеллов в два раза больше урона.
А дракон отражает 20% урона от спеллов (но только от спеллов) назад в кастующего
Если вы думаете, что это какой-то бред, то посмотрите на MTG, Heartstone и т.п. — я затронул только верхушку айсберга
Значит, игрок играет спелл, который его юнит лечит на 100, а противнику наносит 100 урона.
ГеймОунер просит следующее отображение действий:
1. Играется анимация спелла
2. Юнит игрока получает свой хил (+100 хп)
3. Противник получает свой урон (-100хп)
4. Срабатывает абилка — играется анимация
5. Юнит игрока получает урон (-20хп)
6. Противник, если у него закончились хиты, умирает
7. (Тут может ещё что-то произойти из-за смерти противника, к примеру начислятся деньги)
8. В этот момент игрок получает урон от проклятия (-10хп)
Что же мы будем иметь в стейте? Всё, что есть — у игрока +70 хп. И как нам с этой информацией работать? Как развернуть то одно изменение модели в эти 8 последовательных анимаций?
Что же мы будем иметь в стейте? Всё, что есть — у игрока +70 хп.
Не понял. По вашим же словам выше, "в результате выполнения функции hit у вас появился новый мир.". Т.е. для вашей функции отрисовки доступно две вселенных — старая и новая. И вы говорите, что всё, что в этой вселенной есть — это hp игрока? Там нет информации о проклятиях, спеллах и прочем? Как это может быть?
Там нет информации о проклятиях, спеллах и прочем? Как это может быть?
Конечно есть. Давайте постараемся понять, что есть в вашем стейте, синхронизируемся с вами.
У вас есть юнит с id=123, джин, его владелец — игрок с id=5, на джине висит проклятие. Ещё есть юнит с id=42, он дракон.
Нам пришёл новый стейт, в котором у юнита с id=123 hp увеличились на 70, а у юнита с id=42 hp упали на 100. Ну и вся та остальная информация.
Ладно, на базе предыдущего обсуждения давайте добавим, что у джина ещё в каком-то массиве wounded появился дракон.
Как вы всё это проанимируете? Видите ли, причинно-следственные связи у вас потеряны и, предполагаю, во вьюшке вы хотите их восстановить. Правильно ли я понимаю, что вы предлагаете вьюшке залезть в джина, проверить, лежит ли на нём проклятие и если лежит, то понять, что в результате него была получена часть урона. Так же вьюшка должна посмотреть, что целью атаки был дракон, знать, что дракон отражает часть спелла. Для этого вьюшка должна узнать, что за спелл был применен и высчитать, сколько дамаги дракон отразил. Всё остальное — это лечение.
Может я неправильно понял, вы такой видите вьюшку?
Если у вас анимация зависит от состояния персонажа, то очевидно, что алгоритм, составляющий план анимации, должен получить все необходимые данные, иначе он просто не сможет работать.
Видите ли, причинно-следственные связи у вас потеряны
Если вы можете легко восстановить информацию о связях, имея прошлое и настоящее состояние, это не называется "данные потеряны". Ваша цель — продумать структуру состояния так, чтобы вам всегда было достаточно данных. Если вам лень лазить по графу персонажей и восстанавливать события из разницы их состояний — ну заведите тогда "лог событий" как часть состояния и пишите в него все действия всех персонажей явным образом. Это может упростить анимацию, но может усложнить другие вещи.
Правильно ли я понимаю, что вы предлагаете вьюшке залезть в джина, проверить, лежит ли на нём проклятие и если лежит, то понять, что в результате него была получена часть урона.
Это всё нужно для анимации джина? Не проще посчитать урон через разницу hp на текущем и предыдущем шаге? И зачем вьюшке знать причину урона, как это отражается на анимации? Показываете сообщение? Ну тогда да, вьюшке нужна эта информация, как иначе-то?
То же самое про дракона: если для анимации вьюшке нужно знать, какой спелл был применён — значит ей нужно получить этот спелл. Если "отразил часть спелла" как-то влияет на анимацию — значит и это нужно знать. Урон можно посчитать просто как разницу между двумя числами, непонятно зачем там сложная логика вычислений.
Я поражен терпением вашим и 0xd34df00d. По 100 кругу переходить от "Да не, не будет работать, давайте усложним модель" к "Да пожалуйста, вот так вот будет работать", и опять к "давайте снова усложним".
При этом в ООП варианте безо всякиех спеллов/стриков и прочего у нас были проблемы уже в самом первом варианте, где нам обязательно нужен был какой-то менеджер, который должен разрулить кто кому чего нанес. Ну и ООП, магическим образом добавляющее информацию в стейт, чего ФП делать никак не может.
какой-то менеджер, который должен разрулить кто кому чего нанес
Потому что в реальности он есть. Игрок бросил камень в противника, а пока он летел, противник увернулся. Кто здесь считает, кто кому чего нанес? Точно не игрок и не его противник. Если мы делаем модель боя, значит и модель этой части должна быть. Если вы ее убираете по каким-то причинам, значит у вас неточная модель, и если будут проблемы, то это из-за неточной модели, а не из-за ООП.
Потому что в реальности он есть. Игрок бросил камень в противника, а пока он летел, противник увернулся. Кто здесь считает, кто кому чего нанес? Точно не игрок и не его противник.
Ну вот я и говорю об этом. ООП уже в самом мышлении. "Где-то ДОЛЖЕН быть объект, который все считает". Почему должен и почему именно объект, это очень любопытный вопрос.
Проблема на самом деле не в том, что это объект, а в том, как правильно выбирать способ взаимодействия в случае, когда у нас иерархия Player и иерархия Monster.
Почему должен
Так я же написал — потому что он есть в той предметной области, которую мы моделируем. Логически есть, даже если она вымышленная. Мне вот любопытно, почему вы считаете, что его не надо моделировать.
Нет, нам надо моделировать удар игрока по монстру, а не менеджера фабрик ударов. Все это — искусственный конструкт, чтобы выразить предметную область в терминах ООП. При этом почему-то люди считают это естественным.
Где вы увидели предложение делать менеджера фабрик ударов?
Это гипербола. На текущем этапе пока что предлагается только иметь менеджера, который с помощью паттерна команда посылает запросы о нанесении ударов. Чуть выше об этом писалось. Но я уверен, что чуть-чуть обсуждения (особенно в описанных ситуациях с анимациями/killing spree/...), и мы к ним придем.
Но я уверен, что чуть-чуть обсуждения (особенно в описанных ситуациях с анимациями/killing spree/...), и мы к ним придем.
Ну так давайте идти. Конкретные примеры обсуждать полезнее, чем гиперболы про менеджера фабрик ударов.
Какие конкретно правила нам нужно добавить, чтобы вводить такие классы? Покажете ваш вариант кода, где не нужно их вводить?
На текущем этапе пока что предлагается только иметь менеджера, который с помощью паттерна команда посылает запросы о нанесении ударов.
На текущем этапе предлагается иметь информационный объект в программе, который соответствует информационному объекту вне программы — в физической реальности или в воображении придумывающих физику игры людей, которая впрочем тоже в той или иной степени основана на физической реальности. Если кому-то удобнее моделировать это фабрикой фабрик, значит будет фабрика фабрик, но это не обязательно.
Нет, нам надо моделировать удар игрока по монстру
Да, который в физической реальности происходит через посредника в виде физических законов и окружающей среды, которые в удар игрока вносят свои коррективы.
особенно в описанных ситуациях с анимациями
В описанных ситуациях с анимациями, насколько я понимаю, и подразумеваются сообщения о событиях как способ рендерить все это асинхронно.
Нет, нам надо моделировать удар игрока по монстру, а не менеджера фабрик ударов.
Алгоритм, который принимает описание эффекта удара и монстра и применяет данный эффект к монстру и будет де-факто "менеджер ударов", как он по факту будет реализован (в виде класса со вспомогательными ф-ми или просто в виде одной ф-и или еще как) — не важно, вообще.
Ну вот я и говорю об этом. ООП уже в самом мышлении. «Где-то ДОЛЖЕН быть объект, который все считает»
Где-то «всё» считать надо в любой парадигме. В «ООП» это будет класс который хранит в себе данные, а менеджер который вытянет данные и будет считать — шаг назад от идей ООП.
Какой подход проще и лучше в вашей ситуации решать вам. Геймдев довольно специфичная облась где популярны другие подходы.
А под этим постом явно происходит заблуждение о котором Страуструп писал
«X — это хорошо. Объектная ориентированность — это хорошо. Следовательно, X является объектно-ориентированным»
Люди заявляют что им больше нравится класс менеджер и отсутствие инкапсуляции, и на основе того что это удобно заявляют что это ООП
С точки зрения модульности, которая есть ив ФП эта фнукция должна принадлежать какому-то модулю. Почему нельзя этот модуль роассматривать как объект (Game, CollisionProcessingRules, etc..)
Подобно тому, как в смолтоке классы тоже объекты
Оу, уже 2 минуса. Прошу минусующих ответить на заданный вопрос — какой объект в реальности рассчитывает повреждение от летящего камня, и кто меняет характеристики объектов, в которые он попал.
какой объект
God Object.
Да, реальность писал какой-то говнокодер.
Не минусовал, но в реальности как бы сам объект "рассчитывает" свои повреждения, получив от среды "сообщение": "ты совершил контакт с телом с импульсом таким-то, размерами такими-то и т. п.", как реакцию на это сообщение он сам изменяет свои характеристики. Сам камень тоже получает сообщение типа "ты совершил контакт с телом ..." и так же реагирует. При этом собственно расчёты делегируются обоими телами сервисам под общим названием "законы природы".
Кто здесь считает, кто кому чего нанес?Компьютер считает, компьютер.
Точно не игрок и не его противник.Вы из игрока и противника каких-то самостоятельных личностей сделали. Но зачем?
«давайте снова усложним».В смысле «усложним»? Я вам рассказываю о базовых требованиях в геймдеве. Все эти «усложнения» — это начало разработки, фичи, которые появляются в первом прототипе. То, как многие игры должна работать изначально. И я говорю о крайне простых играх.
Хотите усложнение? Посмотрите Хартстоун или МТГ
Вы просто привыкли одинаковые круды писать, да статично вьюшку от модели генерить — вот и пугаетесь таких элементарных вещей, которые любой гейм-девелопер прошел не один раз.
С другой стороны, пока в ООП-подходе обсуждают, чья ответственность взрываться у гранаты, в Виллабаджо ФП уже обсуждают, как обрабатывать киллстрики и цепные молнии.В ООП-подходе эти проблемы давным-давно решены
С другой стороны, пока в ООП-подходе обсуждают, чья ответственность взрываться у гранаты, в Виллабаджо ФП уже обсуждают, как обрабатывать киллстрики и цепные молнии.
Кстати, это как раз претензия скорее к ФПшникам. Ведь люди, которые практически этим занимаются — задают практические вопросы. А ФПшники классически теоретизируют — :
— А вот ответственность…
— А вот теоретически…
— А вот у вас не очень подходящее имя у метода…
— А вот у меня есть стереотип про фабрику фабрик
— А вот мне не нравится слово «менеджер» в названии
Вот на уровень вопросов вы и обратили внимание
Не проще посчитать урон через разницу hp на текущем и предыдущем шаге?Не проще, я же выше показывал, что в результате удара урон и хил должен отображаться раздельно:
ГеймОунер просит следующее отображение действий:
1. Играется анимация спелла
2. Юнит игрока получает свой хил (+100 хп)
3. Противник получает свой урон (-100хп)
4. Срабатывает абилка — играется анимация
5. Юнит игрока получает урон (-20хп)
6. Противник, если у него закончились хиты, умирает
7. (Тут может ещё что-то произойти из-за смерти противника, к примеру начислятся деньги)
8. В этот момент игрок получает урон от проклятия (-10хп)
Над джином мы должны показать +100, через некоторое время -20, потом -10. И это всё в рамках реакции на один удар. Вы же понимаете, что в наивном стейте у нас будет просто +70.
ну заведите тогда «лог событий» как часть состоянияВо, вы начинаете понемногу приходить к понимаю. Спасибо вам за ответы, давайте я теперь расскажу, как это делается на самом деле. Вся суть в паттерне Команда. Я его, правда, немного изменил под себя.
Нам нельзя терять информацию о действиях, причинно-следственная связь крайне важна. Вы ввели лог, это уже движение в правильную сторону, но очень неловкое.
Не должно быть метода Player.hit или функции hit. Для каждого действия заводится команда. У неё есть паблик-ридонли аргументы, которые характеризуют её и метод exec. Далее — TypeScript
class HitCommand extends Command {
public constructor (
readonly source: Unit,
readonly target: Unit,
) {}
public exec () {
// тут действия, которые выполняются, когда необходимо сделать hit.
}
}
Тут можно вспомнить туповатую статью, которая говорит никогда так делать. Но она на то и туповатая, чтобы её не слушать.
Дальше, команды могут вызывать другие команды. У меня это делается через `addChild` — таким образом строится дерево, кто и почему.
class HitCommand extends Command {
public constructor (
readonly source: Unit,
readonly target: Unit,
) {}
public exec () {
this.addChild(new DamageCommand(target, source.getPower()));
}
}
class DamageCommand extends Command {
public constructor (
readonly target: Unit,
readonly value: number
) {}
}
class TryKillCommand extends Command {
public constructor (
readonly target: Unit
) {}
public exec () {
if (this.target.hp <= 0) {
this.addCommand(new KillCommand());
}
}
}
class KillCommand extends Command {
public constructor (
readonly target: Unit
) {}
public exec () {
this.target.isDead = true;
}
}
Когда мы выполняем root-команду — у нас получается приблизительно такое дерево (скрин из консоли реальной игры):
Это чистая модель и с этим очень приятно работать. Но как с этим работает вьюшка?
Она получает дерево команд и у неё есть маппинг Command => Reaction. Она знает, как проиграть удар, как — нанесение дамаги.
Вьюшка получается крайне тонкой. Что-то вроде такого:
class HitReaction extends Reaction<HitCommand> {
constructor (
readonly command: HitCommand,
readonly units : UnitsContainer,
) {}
async play () {
const { source, target } = this.command;
const sourceView = units.find(source);
const targetView = units.find(target);
await sourceView.rotateTo(targetView);
await sourceView.launchHitAnimation();
}
}
class DamageReaction extends Reaction<DamageCommand> {
constructor (
readonly command: DamageCommand,
readonly units : UnitsContainer,
readonly bubbles: BubblesView,
) {}
async play () {
const { target, value } = this.command;
const targetView = units.find(target);
await bubbles.create(
value,
BubblesView.DamageStyle,
targetView.position
);
}
}
Видите? У меня вьюшка вообще не заморачивается какими-то деталями модели. Ей плевать, висит ли на юните проклятье. Пришел дамаг? Она отобразила дамаг. Вьюшка получается крайне тонкой и очень легко поддерживается. Модель — отвечает только за свою часть и легко расширяется. Все действия могут композироваться друг с другом. И если в результате демеджа должно что-то произойти — оно произойдет, кто бы этот демедж не нанес.
И я понимаю, что всё это можно повторить на ФП. Создать рекорды, вручную их заносить в лог. Сделать, чтобы команда вместо стейта возвращала
[ ActionsTree, NewWorld ]. Но это не так удобно. В системе с деревом команд оно всё просто работает, само по себе и её крайне удобно использовать. Любое действие можно сделать в любой момент. Хотите написать чит, который убивет лишнего персонажа? Элементарно!game.exec( new KillCommand(unit) );
И вьюшка это корректно проанимирует. Все, кому необходима эта информация — её получат.
Хотите дать денег игроку? Просто
new GiveMoneyCommand(player, value) и оно заработает!Хотите сделать реплей для вашей игры? Проще простого — сохраняете начальный стейт и дерево команд.
У вас должен вестись подсчёт убитых и отображаться в конце боя? Никаких проблем, вам не нужно где-то в функции kill вызывать другую функцию. Просто StatisticsSystem ждет все KillCommand.
И так далее. Оно работает. Это очень просто поддерживать. Любой приходящий программист с этим разберется за пару дней. Оно позволяет написать тесты на любом уровне.
У вас произошёл баг? Открываете консоль и видите все изменения стейта в крайне удобочитаемом виде.
0xd34df00d, вот и мой ответ, как я обещал выше.
Просто это происходит настолько естественно, что никому не приходит в голову называть это паттерномИ, конечно, в примерах про это забывается и нигде не отображается
Естественно, подход, предлагаемый как решение для одной задачи, не подойдёт в качестве решения для другой задачи, если его скопипастить напрямую. Неудивительно.
Ну смотрите, тот же наивный подход можно и в "ООП" сделать, просто сунув этот сраный hit или hitBy или как вы там его обзовете куда угодно. Решение будет полностью эквивалентно ФП варианту. И в обоих случаях проблемы начинаются, когда: "а что если мне потом надо Х?".
И если вы сделаете все расширяемо, то с-но и опять же в обоих случаях что в ООП что в ФП будет одинаково — представление некоего глобального стейта, представление акторов (монстры/игроки), представление эффектов и алгоритм апдейта стейта на тик.
Нельзя по определению. Потому что у вас нет одного сраного hit как самодостаточной сущности, вам обязательно надо, чтобы объекты, и кому-то оно принадлежало
Ну вот в кого хотите в того и суйте — в плаера, в монстра, куда угодно. В простом случае это не важно будет, кому оно принадлежит.
А в более сложном вы уже отдельно выделите слой, ответственный за обработку стейта.
В чистом ФП тут проблемы "как бы" нет, потому что такого понятия как "засунуть в" нет, ведь нету классов.
Но если например добавить тайпклассы то проблема сразу возвращается — сделаем ли мы тайплкасс тех кто бьет или тех кого бьют?
Потому что у вас нет одного сраного hit как самодостаточной сущности, вам обязательно надо, чтобы объекты, и кому-то оно принадлежалоЕсли нет, то всегда можно сделать. Объекты в ООП совершенно не обязаны всегда представлять реальную вещь, почему бы и не сделать объект «удар» если очень хочется. Но вообще я бы предположил что hit здесь должен быть не обхектом и не свойством объекта, а сообщением одного обхекта другому — а это как раз идеально ложится на ООП. Есть объект который совершает действие затрагивающее другой объект для этого он посылает сообщение об этом действии со всеми необходимыми параметрами. Второй объект, над которым действие совершают получает это сообщение и сам решает как ему поменять свой стейт на освновании того, что он получил. В простом случае такое сообщение можно реализовать и через простое дергание метода второго объекта, но это несколько сбивает с толку, кажется как будто никаких сообщений в таком случае нет, что не совсем верно.
Если память не изменяет, то в классическом ООП сообщения — тоже объекты :)
То есть им тоже можно отправлять сообщения?
что это последовательность действий, а потом про это резко забываете и пишете
всмысле забываю? Я как раз прекрасно об этом помню. Если у меня будет в результате удара три независимых урона — это отобразится на дереве и оно отрисует три независимых урона.
В наивном стейте у меня будет как минимум четыре изменения состоянияОткуда? Если у вас
newState = hit(oldState, player, monster). Я тут вижу ровно одно изменение состояния.хранить список необходимых действийИ как это делать? Вручную формировать и заполнять?
Почему вы вечно рассказываете, как это просто, а когда дело доходит до кода, то всего этого в коде — нету?
hit = do heal attack damage spell
Не, так не пойдет.
hit — наносит урон. Ну вот псевдокодом:
hit (source, target) {
damage(target, source.getPower());
}А вот уже в damage происходит убийстов:
damage (target, value) {
target.hp -= value;
if target.hp < 0 {
kill(target);
}
}У вас не получится всё это причинно-следственное дерево в каждом действии вручную развернуть.
ваши примеры для меня по выразительности не особо отличаются от моих примеровВаши примеры достаточно выразительны (учитывая, что Хаскель я не знаю). Но не всегда могут корректно работать в реальном приложении, увы.
Реакт в своих примерах я не использую.
Это перевод действий из вашего списка. Исцеление, атака монстра, дамаг от монстра, дамаг от проклятия.Знаете пословицу «вассал моего вассала — не мой вассал»?
Ну то есть death — это вассал damage.
А damage — вассал death.
hit создает damage, damage создает death. Но hit ничего не знает о том, что будет создано в damage, соответственно не знает о death.
Над джином мы должны показать +100, через некоторое время -20, потом -10. И это всё в рамках реакции на один удар. Вы же понимаете, что в наивном стейте у нас будет просто +70.
Нет, я не понимаю, почему стейт должен быть настолько наивным? Просто чтобы сделать вас правым? :) Кто запрещает вам положить в стейт всё, что необходимо? Вы считатете, что стейт — это только мгновенные значения координат игроков и их атрибутов (здоровья, экспы), и не может включать "память" персонажей о событиях? Это как если бы ваше собственное состояние включало бы только ваше местоположение, пульс, температуру, мгновенный слепок мысли и эмоций, но не включало бы ваши воспоминания и опыт.
В нормальном стейте будет не только изменение здоровья, но также и информация о применении спелла по противнику, а также о наличии абилки и проклятия, что даёт всю необходимую информацию. Функция анимации получает два стейта — прошлый и настоящий — делает дифф, видит в диффе, что был применён спелл, видит, по кому он был применён, видит в стейте абилку и проклятие, вычисляет, какие кадры и в какой последовательности нужно показать (прямо по вашему списку), выплёвывает эту последовательность движку и забывает о ней. Эта последовательность может быть в виде ваших команд, или в виде набора готовых спрайтов — это уже неважно. У вас есть, по сути, две чистых функции для обсчёта игры:
makeMove(past: World, input: GamerInput) => World;
makeEffects(past: World, present: World) => AnimationFrame[]и две грязных для ввода-вывода:
getInput() => GamerInput;
applyEffects(AnimationFrame[]) => void;Вы вольны положить в структуру World всё, что вам необходимо, чтобы восстановить события между двумя ходами. Функция getInput получает пользовательский ввод с игрового контроллера. ФункцияmakeMove применяет пользовательский ввод и высчитывает новое состояние мира, включая историю применения вооружений и артефактов, makeEffects вычисляет чистую последовательность визуальных эффектов на основе всех этих изменений. applyEffects проигрывает сгенерённую последовательность на дисплее.
Это нарушение инкапсуляцииНе нарушение. Код — это проекция предметной области. И то, какое поведение в какую сущность инкапсулировать — это исключительно вопрос точки зрения.
Если у вас есть взаимодействие нескольких объектов, у вас в любом случае не получится инкапсулировать его сразу во все. И ничего страшно, что один и тот же объект может и содержать свои инкапсулированные методы, и выступать структурой данных для внешних функций, концепция ООП это не запрещает.
И ничего страшно, что один и тот же объект может и содержать свои инкапсулированные методы, и выступать структурой данных для внешних функций
То есть другие объекты будут доставать данные из этого объекта, и работа над данными будет отделена от самих данных. Это самое, что ни на есть, нарушение инкапсуляции, и возвращение к процедурному программированию.
Но ведь «абсолютно правильный» объект в таком случае становится бесполезен, т.к. он просто существует в сферическом вакууме, и никак ни с чем не взаимодействует.
Я не говорил что объект ни с чем не взаимодействует. Объект может решать с чем ему взаимодействовать. В примере выше за него это решает класс менеджер, ломая инкапсуляцию и доставая из него данные.
class Player {
val strength = 10
fun dealDamage(Target t){
t.takeDamage(strength)
}
}А если самую чуточку усложнить, и урон будет зависеть ещё и от параметров экипировки? Просто банальная сумма модификаторов из всех надетых на персонажа шмоток. Эти статы ведь как-то надо из шмоток извлечь, чтобы просуммировать.
Эти статы ведь как-то надо из шмоток извлечь, чтобы просуммировать.
Вот, вы хотите из шмоток достать данные, а суммировать снаружи. Логика отдельно от данных :)
Возможно, стоит подумать над тем чтобы все необходимые расчеты производились в объектах представляющих снаряжение, объект снаряжения мог на основе результатов этих расчетов сообщить что-то объекту, который в конечном счете, после получения сообщений от всех остальных объектов сможет сказать как должно измениться состояние системы.
Теперь объект снаряжения знает что-то про ведение боя и, например, про монстров (тыкать палкой в водяного монстра глупо). Хорошая инкапсуляция, да. Зато все переменные защищены.
Объект снаряжения знает как он защищает от разных типов атаки, при необходимости какие-нибудь коэффициенты можно выносить в конфиг, мне кажется это логичным, почему нет?
Возможно есть какие-то подходы лучше этого, но вынести всю логику подсчета в класс менеджер, который достанет данные абсолютно из всех объектов что участвуют при атаке и что-то там считать из получившихся значений, мне видится явно худшим подходом, с неимоверной связностью, и такой менеджер, опять же, будет знать вообще обо всех объектах, а не только о типах атаки, и всю эту систему нужно будет держать программисту в голове при желании что-то в нём изменить.
чтобы все необходимые расчеты производились в объектах представляющих снаряжение, объект снаряжения мог на основе результатов этих расчетов сообщить что-то объекту, который в конечном счете, после получения сообщений от всех остальных объектов сможет сказать как должно измениться состояние системы.
Так, а каким образом остальные объекты будут ему эти результаты расчетов сообщать? То есть что имеем, главный объект говорит всем объектам снаряжения "посчитайте результат", у них доступа к другим объектам нет, значит они считают на основании только своих характеристик, что превращается просто в возврат значения, а главный объект их суммирует или еще как-то еще объединяет. Вау, так мы же пришли к тому от чего пытались уйти.
Доставать данные из объекта ООП совсем не запрещает. Запрет, если так можно выразиться, есть на прямое изменение состояния объектов. Ваша "работа с данными" — это работа по изменению данных.
Доставать данные из объекта ООП совсем не запрещает. Запрет, если так можно выразиться, есть на прямое изменение состояния объектов.
Работа с данными нарушающая инкапсуляцию в примере что я приводил — это логика находящаяся в одном модуле, зависящая от данных из другого модуля.
А если говорить что ООП запрещает лишь прямое получение изменение переменных из объекта, получится что класс реализующий интерфейс
getA();
getB();
setA();
setB();
полноценный объектВ ООП — это точно нормально, когда логика одного объекта анализирует состояние другого через его публичный API для изменения своего состояния или вызова методов других объектов.
В принципе, да — полноценный объект формально. Который, кстати, не гарантирует, что вызовы getA будут возвращать один и тот же результат, даже если не было вызовов SetA между ними.
Если у нас есть класс менеджер который принимает в себя два объекта и что-то рассчитывает на основе этих объектов, объекты превращаются просто в структуры данных (поле+геттеры), а логика утекает а менеджер.
Это совершенно нормально для действий, которые выполняются над всеми(некоторыми) объектами коллекции.
Это нарушение инкапсуляции
Нет. У объектов остается свое поведение. Например, объект Player умеет переходить из одного состояния в другое, умеет рисовать себя, и многое-многое другое.
Кстати, как я понимаю, логика расчета атаки вообще будет выкинута из кода и окажется в скриптах.
Это совершенно нормально для действий, которые выполняются над всеми(некоторыми) объектами коллекции.
Речи ведь не шло о коллекциях.
Нет. У объектов остается свое поведение. Например, объект Player умеет переходить из одного состояния в другое, умеет рисовать себя, и многое-многое другое.
Данные лежат в объекте, а логика которая зависит от этих данных находится в другом классе, классе-менеджере, это ли не нарушение инкапсуляции?
Данные лежат в объекте, а логика которая зависит от этих данных находится в другом классе, классе-менеджере, это ли не нарушение инкапсуляции?Нет. Нарушением это будет, когда внешняя логика будет описывать внутренне поведение объекта.
Логика боя может и не зависеть от данных. CombatManager может получить просто два интерфейса: Attacker и Victim с набором методов типа Attacker.getAttackPower, Victim.takeDamage.
Как именно каждый конкретный attacker будет вычислять свою силу атаки и как именно каждый конкретный victim будет получать урон, определяют они сами. При этом CombatManager знает лишь общие правила, Attacker ничего не знает о Victim и наоборот.
Мы сможем подсунуть вместо экземпляра Monster, экземпляр Gazebo, который в методе takeBowDamage никак не будет менять свое состояние.
Кстати, как я понимаю, логика расчета атаки вообще будет выкинута из кода и окажется в скриптах.Вы почти воспроизвели «паттерн проектирования Visitor», только в нём «логика расчёта» написана не во внешних скриптах, а в отдельном монстрообразном классе — «визитёре», который вызывают в начале и который потом выдаёт куда надо и кому надо результат.
Так это логика взаимодействия. То есть как конкретно монстр истекает кровью — это его внутреннее дело (поэтому я бы сделал sethitBy(weapon)), а вот общая логика (изменения атакующего и атакуемого) не могут быть ни в атакующем, ни в жертве. То есть у нас условно
- changeMonster
- changeAttaker
И оба этих метода нужно где-то вызвать. Скорее всего в менеджере боя.
makeHit(strength: number) и acceptHit(strength: number)?Герой: Меч, не будешь ли ты так любезен, нанести Злодею удар в левую пятку, в который я вложу всю свою силу (10) и ловкость (3). Система, зафиксируй удар.
Меч: Злодей! Мною нанесён по тебе удар, который (с учётом моих бонусов) имеет силу 13 и ловкость 3. Система, запиши себе в журнал.
Злодей: Система. Имею сообщить, что в результате подлой атаки Мечом Героя, от которой я слегка уклонился, мне была нанесена рана в мягкое место и я потерял 5 единиц здоровья.
Система: Слизняк, участвующий в бою, Злодей отпрыгнул на тебя с силой 20.
Слизняк: Система, я потерял 25 единиц здоровья от рукопашного удара Злодея и умер.
Система: Слизняк умер от атаки Злодея. Злодей получает 1 опыта и лечебное зелье.
Герой:… твою мать.
Система: ну что, бойцы, к бою готовы? Сообщите мне ваши цели и типы атак.
Герой: Цель — Бешеный Бобр, атака — удар бревном, вложено 5 единиц силы и 2 ед ловкости
Оруженосец: я ничё, я тут так, посмотреть только и бревно подать.
Бешеный Бобр: цель — Герой, атака — удар хвостом, вложено 3 ед силы, 10 ед ловкости
Система: Ок, тааак… посмотрим… Оруженосец встал на линии атаки Герой--Бобр и создаёт помеху, снимаем 1ед ловкости с атаки Героя, а атаку Бобра частично направляем на Оруженосца. Теперь рандомизируем, взвешиваем по ловкости… Ок, все приготовились к раздаче люлей! Герой — прими атаку бобровым хвостом 1.5 ед, Оруженосец — прими атаку бобровым хвостом 0.6 ед, Бобр прими удар бревна 6 ед. Герой, поздравляю, удачный удар, даже при том, что Оруженосец тебе мешался.
Герой: принял
Оруженосец: ну ё… меня-то за что?
Бобр: гхххххх....
Я сейчас задам максимально тупой вопрос, но… Зачем для этого класс? Может ограничиться функцией?
(Предположим, что язык позволяет, например C++ или python)
Можно обойтись функцией, если возможно. Просто в ОО языках вроде Java и C#, эти функции должны где-то находиться.
Еще не понятно, кто именно должен вызывать эту функцию. Этот некто должен знать всех игроков и всех монстров, обрабатывать действия игрока и разбираться кто кому на самом деле нанес урон.
Например, инлайнинг приватных методов и/или замена вызовов на переходы. Не уверен, как сейчас, но лет 10 назад компиляторы C справлялись с оптимизациями вызовов статических вызовов все-таки похуже.
Где-то в районе 2004 года сравнивал реализацию через класс с приватными методами и на C с непрозрачной структурой и б/м таким же кодом в статиках. Суть — принимаются входящие отсчеты и регистрируется начало и завершение определенных событий в преобразованном сигнале с адаптивными порогами, определением артифактов и т.д. Много внутреннего состояния, соответственно.
Результат на C++ получался компактнее и где-то на 10-15% быстрее. В ассемблере на C++ не было вызовов приватных методов: или прямое встраивание, или джампы. А на C были.
Как-то так.
Возможность сохранять в себе всю свою информацию.
Проблема ООП в том, что методы пытаются представить как действия субъекта. В то время как методы это дейстия над объектом.Хорошо было в Visual Basic: действия объекта — это события, которые он генерирует, действия над объектом — это методы.
Что значит "было"? И в чём тут заключается особенность VB?
Что значит «было»?Я не знаю насколько широко он используется сейчас.
И в чём тут заключается особенность VB?В нём, по крайней мере в COM, это на уровне языка. Под события «выделяются» не методы и не свойства источника событий, а метода со специальным названием у «приёмника»-обработчика событий. Т.е. не у кнопки есть свойство «onclick» и не метод кнопки «click», для чего требовалось бы на каждую кнопку создавать специальный класс-потомок, а у формы, на которой есть эта кнопка, должен быть метод с именем типа
CancelButton_click, который вызывается при нажатии на кнопку с именем (как это делается на объектном уровне, не помню, вроде как это имя поля класса формы, на которой есть эта кнопка) «CancelButton».по крайней мере в 1998 я читал хелп к VB5, и там было написано что-то вроде «метод — это то, что вы делаете с объектом, событие — это то, объект говорит, что с ним сделали».
Это всего лишь статическое связывание событий с обработчиками, а не механизм событий в общем виде. Оно в VB.NET присутствует до сих пор, и на данный момент реализуется "за кулисами" двумя методами и одним полем в самой кнопке, а также одним свойством на форме.
И да, делать наследника для источника событий (т.е. для кнопки) не требуется ни в одном языке.
Методы — это не действия, это способ приёма объектом каких-то сообщений от внешней среды и возможность отреагировать на них изменением своего состояния и(или) посылкой сообщений другим объектам, выступая для них внешней средой.
Я все понимаю, правда, но у меня возникает ощущение, что все забывают о том зачем собственно вся эта возня.
Напишите, пожалуйста, вариант решения этой задачи на ООП из Smalltalk. Мне правда интересно, как все изменится.
Посмотрите на нормальную реализацию ООП — CLOS или GOOPS. Последний у вас на компьютере имеется, скорее всего, можете поэкспериментировать. CLOS появился он после того, как в MIT познакомились со Smalltalk, поняли — насколько он ущербен, и придумали как сделать правильно.
Классы там описываются вот так, методы вот так — и они, что характерно, классам не принадлежат.
Что и логично: методы описывают, как правило, взаимодествие двух или нескольких классов — с какого перепугу они должны быть в одном их них? Потому что кто-то когда-то решил, что выбирать в одной табличке быстрее, чем в графе?
Ну бред это. И да — имитация нормального ООП поверх того, что у нас есть — не самый плохой вариант. Но нужно понимать — что это просто компромис, не более того.
Вы Чем хуже, тем лучше читали? Вот это — всё оттуда. Вопрос: «принадлежит ли метод „hit“ монстру или игроку» в нормально реализованном ООП просто не возникает. Но поскольку у нас такой не используется, то да, приходится выбирать. И иногда в результате очень вычурные конструкции получаются.
Но тут ничего не поделать: у нас нет времени всё сделать правильно. К тому моменту, когда вы сделаете «самый правильный язык» критерии правильности поменяются — и вам придётся всё начать с начала (см. Кнута с его MIX и MMIX). И написать на «хорошем» языке реальную систему не получится никогда.
Потому всё, что у нас есть — это плохие реализации ООП, плохие реализации ФП — и так далее. Спорить по поводу принципиальных проблем в ООП глядя только на плохие реализации — глупо и бессмысленно.
Я и не собирался спорить.
Прошу вас просто написать реализацию задачи "игрок бьет монстра" на хорошей реализации ООП или ФП.
(use-modules (oop goops))
(use-modules (oop goops describe))
(define-class <player> ()
(attack-power #:init-keyword #:attack-power)
(xp #:init-keyword #:xp))
(define-class <monster> ()
(hp #:init-keyword #:hp)
(level #:init-keyword #:level))
(define-method (is-monster-alive (m <monster>))
(> (slot-ref m 'hp) 0))
(define-method (player-hits-monster (p <player>) (m <monster>))
(slot-set! m 'hp
(- (slot-ref m 'hp) (slot-ref p 'attack-power)))
(if (not (is-monster-alive m))
(slot-set! p 'xp (+ (slot-ref p 'xp) (slot-ref m 'level)))))
(define p (make <player> #:attack-power 5 #:xp 0))
(define m (make <monster> #:hp 10 #:level 3))
(player-hits-monster p m)
(player-hits-monster p m)
(player-hits-monster p m)
(describe p)
(describe m)
$ guile test.scm
#<<player> 55e24a5f01a0> is an instance of class <player>
Slots are:
attack-power = 5
xp = 6
#<<monster> 55e24a5f0020> is an instance of class <monster>
Slots are:
hp = -5
level = 3
Это выглядит, фактически, как плохой и нехороший «процедурный» подход… но на самом деле — это полноценный ООП. Вы можете сделать, например, «святого игрока» и «монстра-нежить» и сделать так, что при их столкновении урон будет в два раза больше:
(define-class <holy-player> (<player>))
(define-class <unholy-monster> (<monster>))
(define-method (player-hits-monster
(p <holy-player>) (m <unholy-monster>))
(next-method)
(next-method))
(define p2 (make <holy-player> #:attack-power 5 #:xp 0))
(define m2 (make <unholy-monster> #:hp 9 #:level 3))
(player-hits-monster p2 m2)
(describe p2)
(describe m2)
#<<holy-player> 55f2e383aca0> is an instance of class <holy-player>
Slots are:
attack-power = 5
xp = 3
#<<unholy-monster> 55f2e3923620> is an instance of class <unholy-monster>
Slots are:
hp = -1
level = 3
Через MOP вы можете динамически менять тип объекта, так что вам не нужно решать — куда девать «обвес» игрока.
Вот все эти фабрики-фабрик-фабрик и прочее — это попытка обойти ограничения Simula 67, где нет ни возможности менять классы в рантайм, а методы обязательно нужно куда-то засовывать… но зачем эти ограничения приписывать «ограничениям ООР» в целом?
Напишите, пожалуйста, ваше определение ООП.
Я просто не пойму чем
(define-method (player-hits-monster (p <player>) (m <monster>))
(slot-set! m 'hp
(- (slot-ref m 'hp) (slot-ref p 'attack-power)))
(if (not (is-monster-alive m))
(slot-set! p 'xp (+ (slot-ref p 'xp) (slot-ref m 'level)))))существенно отличается от метода в CombatManager.
Термин "метод" в вашем примере применяется для концепции, которая в ФП называется функцией. UPD: сначала написал "чистой", но не уверен. У вас в ней меняется состояние того, что вы передали через аргументы.
Вы взяли логику по взаимодействию и вынесли ее в отдельную единицу исполнения. player, holy-player, monster, unholy-monster у нас все так же ничего не знают друг о друге и модифицируются чем-то снаружи.
В случае с holy-player и unholy-monster в традиционном ОО языке мы сделаем перегруженный метод в том же CombatManager и логику по выбору метода в том месте, где мы будем вызывать атаку.
Если вас смущает необходимость писать метод в каком-то классе (в частности CombatManager), то можно относиться к нему просто как к namespace. Чтобы метод был не в глобальной области видимости, а подключался только тогда, когда мы его используем.
Любопытно, что в вашем случае нужно будет делать, чтобы реализовать комбинации "player атаковал unholy-monster" и "holy-player атаковал monster"?
Я просто не пойму чемОтсутствием CombatManager'а, очевидно.
…
существенно отличается от метода в CombatManager.
Термин «метод» в вашем примере применяется для концепции, которая в ФП называется чистой функцией.Ну какая ж она, нафиг, чистая, если она меняет и состяние игрока и состояние монстра?
В случае с holy-player и unholy-monster в традиционном ОО языке мы сделаем перегруженный метод в том же CombatManager и логику по выбору метода в том месте, где мы будем вызывать атаку.И тем самым, криво и неуклюже, сделаете имитацию нормальных multiple dispatch методов.
Любопытно, что в вашем случае нужно будет делать, чтобы реализовать комбинации «player атаковал unholy-monster» и «holy-player атаковал monster»?Рука-лицо.
(define-method (player-hits-monster
(p <player>) (m <unholy-monster>))
...)
(define-method (player-hits-monster
(p <holy-player>) (m <monster>))
...)
Если вас смущает необходимость писать метод в каком-то классе (в частности CombatManager), то можно относиться к нему просто как к namespace. Чтобы метод был не в глобальной области видимости, а подключался только тогда, когда мы его используем.А если у нас одна команда заведует святыми, а другая — демонами? Где они будут соотвествующие методы размещать?
Появится HolyCombatManager и UnholyCombatManager. Дальше появятся комбинаторы. Фабрики. Фабрики фабрик. Ну и всё то, о чём статья.
Но это всё — не проблемы ООП! Это свойство одного конкретного языка… который, к сожалению, раздублировали везде и всюду.
Говорить, что это всё «проблемы ООП»? Ну блин. ООП — не панацея, у него есть свои проблемы… но то, что описывается в статье — не есть проблема ООП.
А если у нас одна команда заведует святыми, а другая — демонами? Где они будут соотвествующие методы размещать?Команда разработчиков. Которые делают соотвествующие модули.
Ну какая ж она, нафиг, чистая, если она меняет и состяние игрока и состояние монстра?
Тут вы правы, она не чистая.
Я правильно понимаю, что в вашем языке можно сделать что-то вроде
allPlayers = (shuffle (make<holy-player>, make<player>, make<player>, make<holy-player>)) //создать коллекцию разных игроков и перемешать ее
currentPlayer = (getByIndex allPlayers, 0) //взять первого игрока
(define m2 (make <unholy-monster> #:hp 9 #:level 3))
(playerHitsMonster currentPlayer m2)и рантайм сам поймет какую именно комбинацию playerHitsMonster выполнять?
И это не мой язык, как я сказал. Это guile. Если у вас Linux, то наберите в комадной строке
guile и нажмите Enter — с большой вероятностью он у вас уже есть.Ну или на tio.run загляните, если его у вас всё-таки нет.
Я тут сел написать то же самое на java и задумался. Какой логикой руководствуется рантайм, когда выбирает из
(define-method (player-hits-monster (p <player>) (m <monster>))
(slot-set! m 'hp
(- (slot-ref m 'hp) (slot-ref p 'attack-power)))
(if (not (is-monster-alive m))
(slot-set! p 'xp (+ (slot-ref p 'xp) (slot-ref m 'level)))))и
(define-method (player-hits-monster
(p <holy-player>) (m <unholy-monster>))
(next-method)
(next-method))Эти методы помещаются в список и из них выбирается какой-то первый?
Ищется такой метод, аргументы которого ближе всего к реальным типам p и m?
Какой метод выберется, если у нас будет corrupted-holy-player — наследник holy-player, который должен наносить урон как обычный player?
Какой логикой руководствуется рантайм, когда выбирает из
Вызывается наиболее специфичный метод, подходящий под типы аргументов. Если нормально специфичность сравнить нельзя, то добавляются костыли (ну типа специфичность первого аргумента > специфичности второго и т.п.).
Какой метод выберется, если у нас будет corrupted-holy-player — наследник holy-player, который должен наносить урон как обычный player?Если у вас corrupted-holy-player не ведёт себя так же, как holy-player, то он, очевидно, не должен являться его наследником. Если у вас часть характеристик идёт и туда и туда (скажем у обоих есть нимб), то у вас будет иерархия, где player-with-halo — и уже от него будут наследоваться holy-player и corrupted-holy-player.
Как я уже сказал: тип объекта со временем может меняться и, более того, типы могут генерироваться автоматически при необходимости (то есть у вас нет проблемы «комбинаторного взрыва», которую решают 100500 уровней индирекции в Java: если у вас 100 типов и может быть 2100 подтипов, которые зависят от того, какие типы включены, какие нет — то вам вовсе не обязательно реализовывать все 2100 подтипов статически...)
А если у нас одна команда заведует святыми, а другая — демонами? Где они будут соотвествующие методы размещать?
Эти команды будут отвечать за святых и за монстров (внутренние данные, отрисовка, анимация и т.п.), но не за динамику их боевого взаимодействия друг с другом. Точно так же как за (player-hit-monster ... ...) будет отвечать тот, кто реализует бой, а не персонажей.
Появится HolyCombatManager и UnholyCombatManager.
Зачем? В том же самом CombatManager появится код, обслуживающий столкновения дополнительных персонажей. Это могут быть перегруженные методы вроде .PlayerHitMonster(HolyPlayer, UnholyMonster) (аналогично приведённому вами), или один-единственный метод, который выясняет трейты каждого персонажа и матчит их возможные взаимные комбинации:
var factor =
(p is Holy) && (m is Unholy) ? 2.0 :
(p is Holy) && !(m is Unholy) ? 1.5 :
!(p is Holy) && (m is Unholy) ? 0.5 : 1.0;
var power = p.AttackPower * factor;Эти команды будут отвечать за святых и за монстров (внутренние данные, отрисовка, анимация и т.п.), но не за динамику их боевого взаимодействия друг с другом.А кто будет отвечать за динамику?
В том же самом CombatManager появится код, обслуживающий столкновения дополнительных персонажей.А как он там появится, извините? Если, скажем, игру выпускают одни люди, а аддоны к ней к наборами монстров — другие?Это могут быть перегруженные методы вроде .PlayerHitMonster(HolyPlayer, UnholyMonster) (аналогично приведённому вами), или один-единственный метод, который выясняет трейты каждого персонажа и матчит их возможные взаимные комбинации:Один-единственный метод, очевидно, работать не будет, а чтобы перегружать методы — как раз и потребуются
HolyCombatManager, UnholyCombatManager, CombiningCombatManager и всё прочее, что отсюда будет следовать…А кто будет отвечать за динамику?
Тот, кого поставили отвечать за неё и за баланс игры в общем — т.е. тот, кто в вашем случае добавляет все эти перегрузки player-hits-monster.
Вот две команды — разработчики "игроков" и разработчики "монстров" — готовятся добавить новый тип монстра и новый тип игрока, а значит надо добавить ещё перегрузок на разные комбинации игрок-монстр, с учётом всех уже имеющихся и тех, что готовятся к выпуску. Кто в вашем случае будет добавлять перегрузки, "команда игроков" или "команда монстров"? Как они будут согласовывать своих персонажей друг с другом? На мой взгляд, чтобы не превратить игру в хаос, за это должна отвечать отдельная команда "мастеров игры", имеющая информацию о всей игре, а не команды отдельных персонажей.
Если, скажем, игру выпускают одни люди, а аддоны к ней к наборами монстров — другие?
Т.е. у вас player-hits-monster перегружается авторами аддонов с монстрами? А если добавляется новый тип игрока — то авторами аддонов с игроками? А если два аддона выпущены независимо, то возникает дыра в том месте, где новые игроки взаимодействуют с новыми монстрами, так как никто об этом не подумал? А потом обе команды спохватываются и решают заполнить дыру, и выпускают новые версии, каждая из которых перегружает одну и ту же комбинацию игрок-монстр?
На мой взгляд, чтобы не превратить игру в хаос, за это должна отвечать отдельная команда «мастеров игры», имеющая информацию о всей игре, а не команды отдельных персонажей.Конечно. Вот только эта «отдельная команда» — это люди вообще не имеющие отношения к программированию.
Вы в настолки когда-нибудь играли? Там регулярно выходят новые допы. В диких количествах. В некоторых случаях — их вообще разные фирмы выпускают к одной игре. И да, иногда сочетания разных паков приводят к странным эффектам — тогда игроки (а не разработчики!) такое сочетание договариваются не использовать.
А потом обе команды спохватываются и решают заполнить дыру, и выпускают новые версии, каждая из которых перегружает одну и ту же комбинацию игрок-монстр?Иногда бывает, но очень редко. Обычно меняется описание базовых эффектов, из которых строятся все персонажи, меняется вместо этого.
А как он там появится, извините? Если, скажем, игру выпускают одни люди, а аддоны к ней к наборами монстров — другие?
Для этих целей делают всякие скриптовые движки, где можно подписаться на событие и проверить, хотим ли мы его обрабатывать.
Например https://wiki.wesnoth.org/Eventwml
И тем самым, криво и неуклюже, сделаете имитацию нормальных multiple dispatch методов.
Если решать задачу с holy-player "в лоб", то действительно получится некрасивая имитация.
public static void hit(Player p, Monster m) {
m.hp -= p.power;
if (m.hp <= 0) {
p.xp += m.level;
}
}
public static void hit(HolyPlayer p, EvilMonster m){
m.hp -= p.power * 2;
if (m.hp <=0 ){
p.xp +=m.level;
}
}
public static void selectHit(Player p, Monster m){
if (p.getClass().equals(HolyPlayer.class) &&
m.getClass().equals(EvilMonster.class)){
HolyPlayer hp = (HolyPlayer) p;
EvilMonster em = (EvilMonster) m;
CombatManager.hit(hp, em);
} else {
CombatManager.hit(p, m);
}
}Однако в реальном приложении скорее всего будет такая логика:
public static void hit(Player p, Monster m) {
m.hp -= p.power;
if (m.hp <= 0) {
p.xp += m.level;
}
}
public static void holyHit(Player p, Monster m){
m.hp -= p.power * 2;
if (m.hp <=0 ){
p.xp +=m.level;
}
}
public static void selectHit2(Player p, Monster m){
if (p.isHoly() && m.isEvil()){
CombatManager.holyHit(p, m);
} else {
CombatManager.hit(p, m);
}
}public class Player {
public int power;
public int xp;
public Player(int power, int xp) {
this.power = power;
this.xp = xp;
}
public boolean isHoly(){
return false;
}
@Override
public String toString() {
return "Player{power=" + power + ", xp=" + xp + '}';
}
}
public class HolyPlayer extends Player {
public HolyPlayer(int power, int xp) {
super(power, xp);
}
@Override
public boolean isHoly() {
return true;
}
}
public class Monster {
public int hp;
public int level;
public Monster(int hp, int level) {
this.hp = hp;
this.level = level;
}
public boolean isEvil(){
return false;
}
@Override
public String toString() {
return "Monster{hp=" + hp + ", level=" + level + '}';
}
}
public class EvilMonster extends Monster {
public EvilMonster(int hp, int level) {
super(hp, level);
}
@Override
public boolean isEvil() {
return true;
}
}
public class CombatManager {
public static void main(String[] args) {
Player p = new Player(5, 0);
Monster m = new Monster(10, 3);
hit(p, m);
hit(p, m);
hit(p, m);
System.out.println(p);
System.out.println(m);
HolyPlayer p2 = new HolyPlayer(5, 0);
EvilMonster m2 = new EvilMonster(9, 3);
hit(p2, m2);
System.out.println(p2);
System.out.println(m2);
Player p3 = new Player(5, 0);
EvilMonster m3 = new EvilMonster(9,3);
hit(p3, m3);
System.out.println(p3);
System.out.println(m3);
List<Player> players = new ArrayList<>();
players.add(new Player(5,0));
players.add(new Player(5, 0));
players.add(new HolyPlayer(5, 0));
players.add(new HolyPlayer(5, 0));
Collections.shuffle(players);
EvilMonster m4 = new EvilMonster(9, 3);
Player p4 = players.get(0);
System.out.println(p4.getClass().getCanonicalName());
selectHit2(p4, m4);
System.out.println(p4);
System.out.println(m4);
}
public static void hit(Player p, Monster m) {
m.hp -= p.power;
if (m.hp <= 0) {
p.xp += m.level;
}
}
public static void holyHit(Player p, Monster m){
m.hp -= p.power * 2;
if (m.hp <=0 ){
p.xp +=m.level;
}
}
public static void selectHit2(Player p, Monster m){
if (p.isHoly() && m.isEvil()){
CombatManager.holyHit(p, m);
} else {
CombatManager.hit(p, m);
}
}
}В этом варианте бизнес-логика по выбору между holy-hit и просто hit не будет утекать в диспетчер языка.
В этом варианте бизнес-логика по выбору между holy-hit и просто hit не будет утекать в диспетчер языка.А какую проблему вы этим решите?
Нет, я верю: можно гланды вырезать и автогеном через задницу. Но… зачем?
А какую проблему вы этим решите?
"Этим" это чем? Я попытался реализовать задачу на java и пока что решение выше — лучшее, что я придумал. Я ещё на scala попробовал, но показать нечего.
Я бы вас понял, если бы на java было решение с динамической диспетчеризацией и без нее и вы бы спрашивали "зачем без нее". Но решение пока всего одно.
Я бы вас понял, если бы на java было решение с динамической диспетчеризацией и без нее и вы бы спрашивали «зачем без нее».А причём тут Java? Я в самом начале этой ветки сказал, что обсуждаемая проблема — это Simula головного мозга.
Да, в Java нет динамической диспетчеризации и из-за этого отношение многие-ко-многим моделируются через промежуточные, искусственные, структуры.
Не вижу тут ничего плохого — при условии, что вы понимаете что это костыль и какую именно проблему он решает.
А вот говорить, что раз вам при использовании Java нужен костыль, то теперь давайте весь ООП отменим — это перебор.
На Java и её подходах ООП не заканчивается…
Проблема ООП в том, что методы пытаются представить как действия субъекта. В то время как методы это дейстия над объектом.Я в самом начале этой ветки сказал, что обсуждаемая проблема — это Simula головного мозга.
Но ведь вы показали такой пример, где методы это как раз действия над пассивными объектами, а не действия активных субъектов. Я тот же самый тезис защищаю.
Разница моего и вашего подхода только в диспетчеризации этих методов, которая в GUILE из коробки и динамическая, а в моем решении на java самописная.
Рука-лицо. Причём тут Smalltalk? Он ещё более ограничен, извините.
Потому что Smalltalk ООП язык, а C++, какой, например, нет?
Потому всё, что у нас есть — это плохие реализации ООП
Ну идеи Кея частчино представлены в виде actor model в erlang или akka, или, например, микросервисы выступающие в роли объектов.
Ну идеи Кея частчино представлены в виде actor model в erlang или akka, или, например, микросервисы выступающие в роли объектов.Речь не об этом. Речь о том, что вы либо постоянно меняете язык несовместимым образом, когда в нём обнаруживаются проблемы (Algol ⇒ Pascal ⇒ Modula-2 ⇒ Operon) — и тогда вы рано или поздно теряете всех программистов, потому что никому не интересно переписывать то, что уже один раз написано 100500 раз, либо у вас язык, оказывается плохим… но, возможно, востребованным…
Просто нужно понимать, что «ООП» и «то, что умеет C++ (Java, ObjectiveC, Swift, C#, да даже и GUILE — неважно)» — это разные вещи.
Любой язык реализует некое ограниченное решение. От этого никуда не деться.
Статическией шаблонный полиморфизм в C++ (CRTP и вот это вот всё) — гораздо ближе к CLOS и ML, чем виртуальные функции и виртуальные классы.
И, что характерно, в последнее время всё больше библиотек в C++ используют именно этот объектный подход, а не ФабрикуФабрикФабрик, критикуемую в статье… но что это тоже ООП — авторам статей, подобных обсуждаемой, в голову не приходит…
P.S. Десятое правило Гринспена в действии, блин…
void Hit(Monster monster)
{
if (monster.IsHitBy(CurrentWeapon, AttackPower) <= 0)
// например можно возвращать количество оставшихся hp
// у монстров может быть immunity к немагическому оружию например
// или разный уровень дамага от slaching/piercing/crushing - все это легко тут учитывается
{
XP += monster.XP;
}
}А используя наследование можно, например заменить monster на ITarget и тогда подставлять туда сундуки, других игроков, NPC и т.д.
Можно чтобы Hit возвращал bool если нужно и т.д.
AttackPower нужно передавать, т.к. одним и тем же оружием разные персонажи разный damage нанесут. Это может быть например, специалист по убийству зомби с доп. дамаком против undead и т.д. И все это очень легко и красиво укладывается в модель.
Битва (класс Fight), например, может быть также отдельной сущностью — содержать свою информацию о событии. У битвы есть 2 стороны (это могут быть даже и коллекции) — интерфейсы, которые могут наносить урон, получать урон, использовать оружие или не использовать — это уже конкретная реализация интерфейса в виде классов Player или Monster. По SOLID ни один из этих классов не должен знать о существовании другого, поэтому кто кого и как пинает может решаться в классе битвы Fight. Но битва тоже напрямую ничего не знает о конкретных реализациях, она только знает, что интерфейс стороны А может нанести N урона, а интерфейс стороны B получить N урона (а может и не N, потому что вмешались какие-то третьи магические силы).
А можно придумать еще кучу вариантов. Считать недостатком инструмента, что он предоставляет множество вариантов сделать кривую реализация, я думаю, неправильно. Также полагаю, что нельзя считать недостатком инструмента непонимание или нежелание его понимать. Как и на машине можно разогнаться и въехать в столб — машина ведь не виновата.
Вот здесь было обсуждение:
softwareengineering.stackexchange.com/questions/369066/oop-ecs-vs-pure-ecs
Событийную шину с emit(hit) и onHit уже предлагали?
Неа! Вы же видите, предлагают ровно то же самое, что описано в статье (осуждаем, а потом это же и предлагаем, да) — вариации с hit/isHitBy, либо использовать класс "менеджер битвы" (чорд! Это ещё бОльший трэш, но его всерьёз предлагают несколько человек, как более хорошее решение! Я был лучшего мнения о человечестве...)
Ваш вариант, кажется мне куда более вменяемым. Но, вообще-то, это не ОО решение ;). Оно, безусловно, может быть реализовано в ООП стиле, но совершенно не обязательно :).
Да уж… Кони ездят верхом на людях у автора статьи. Начать стоит с того, что реальные сущности практически никогда не мапятся на объекты и классы один к одному. Пример с игроком и монстром не корректен, т к по сути такая ситуация напрямую показывает, что нужен ещё класс и возможно не один. (Например Game или FightRule)
Второе — он упомянул акторы… Так они по сути ещё ближе к ооп в том его виде, в каком задумывал Алан Кей. Объекты обмениваются сообщениями. И всегда поддерживают инварианты внутри себя. Инкапсуляция! Причем в акторах она прям тру — ничего нельзя сделать без сообщений. И состояния у них есть… Короче, что то тут не то...
нет нормальных data object.
во всяческих kotlin — стараются исправить.
в идеале, возможно, часто нужен вобще аналог struct(яркий пример — Point, Color, Rect и т.д.).
Чем класс с конструктором и пачкой public final-ов не data object?
хочется serializable и прочее искаропки
сравнение опять же.
вот в котлине грамотно сделано.
ну и аналог struct тоже хотелось бы
Я не предлагаю геттеры и сеттеры делать. Java как язык не виновата в том, что Javabeans стал де-факто стандартом.
Serializable — это уже DTO. Для обычного data object достаточно внешней сериализации.
Если нужен кастомный Comparable — это уже Entity. Для обычного data object равенство объектов — это равенство всех полей по определению.
В общем, не вижу, чем не хватает обычного класса, в котором нет ничего, кроме конструктора и public final-ов, и парочки внешних утилит, работающих через рефлексию. Это в общем-то и есть immutable struct по сути своей. А mutable — не надо, спасибо.
Пример с игроком и монстром не корректен, т к по сути такая ситуация напрямую показывает, что нужен ещё класс и возможно не один.Так вся статья как раз о том, что там, где до появляения Архитектурных астроавтов от ООП было сто строк кода и парочка массивов структур — у вас повилась куча классов, в которых без помощи IDE разобраться нельзя, а с помощью IDE — можно, но очень поверхностно.
Все аргументы подобного рода игнорируют предысторию, почему вдруг стали появляться эти "кучи классов"?.. А предыстория такова что стало "модным" поддерживать и разширять ПО уже после того как первоначальная задача решена при создании. Тот же ООП никак вам не диктует сколько создавать классов. Можете создать один только "Game" если для вашей задачи этого достаточно. А игрок и чудовище будут в нем полями, структурами или массивами (привет Фортран-стайл). Автор статьи валит проблемы на инструмент, в то время как реальная беда — отсутствие людей способных прочитать и осмыслить инструкцию к инструменту
Вот сделать несколько классов для изображения обсуждаемой там логики — понятно. Но ещё один (или, тем более, много) классов для рассчётов? Зачем?
Но ещё один (или, тем более, много) классов для рассчётов? Зачем?
Какой-то AttackDamageCalculator, который сведет все возможные модификаторы урона и выдаст решение. Ну или функция
calculateAttackDamage(), в которую зависимости пробрасываются каррированием. Ну или какая-то ParabolaTrajectory для того, чтобы узнать траекторию полета снаряда.
У меня вот ещё в одном проекте были довольно сложные условия и, как результат — был билдер фильтров. Выглядело так:
// Нанесите 2 повреждения выбранной технике или взводу
// Восстановите 2 прочности вашему штабу.
public class ParisGunAbility : SpecificAbility
{
protected override Command[] Exec(Card target)
{
return new Command[] {
new DealDamage(2, Card, target),
new HealDamage(2, Card, Owner.Cards.GetHq())
};
}
protected override Search Targets(Search search)
{
return search.Enemy().Vehicle().Platoon();
}
}Ещё нам необходим какой-то OptionsCollector, который сможет проанализировать модель и выдать для вьюшки в адекватном виде возможные действия, которые мы ждем от пользователя.
Да нет, в DDD перечисленных проблем бы не было.
Скажем, вопроса про hits бы точно не возникло — поскольку был бы aggregate root.
А то что автор путает ООП с чем-то несусветным это точно.
Достаточно такого:
ООП требует передавать повсюду длинные списки аргументов или непосредственно хранить ссылки на связанные объекты для быстрого доступа к ним.
Первое что у меня произошло с переходом на ООП, это исчезли длинные списки аргументов.
архитектура данных -> код
Стоит только подвергнуть сомнению этот тезис (даже не опровергнуть, а просто засомневаться), как и все остальные рассуждения становятся неубедительными. Но размышления интересные.
Код оперирует данными. Все базовые конструкции кода (присвоение, ветвление, цикл) без данных не осуществимы. Можно ради хохмы создать пустую функцию и сказать, что это код без данных, но и она будет возвращать null по-умолчанию. Так что, даже не сомневайтесь ;)
P.S.
хотя… можно создать кучу классов, наследующих друг от друга и все без единого метода (если не брать во внимание наличие default-методов типа toString()) — это лучшее, что удалось придумать на тему "код без данных".
А сколько, по-вашему, различных элементов данных нужно иметь, чтобы можно было говорить об "архитектуре данных"?
IMHO, писать код без входных-выходных аргументов (или без взаимодействия с каналами ввода-вывода) бессмысленно. А наличие данных на входе-выходе (вводе-выводе) уже подразумевает наличие некоторых правил (например, заданным языком программирования), которым эти данные подчиняются. Пусть даже эти правила в явном виде не осознаются при написании кода по причине их прошитости в подкорку (те же самые типы данных, например).
Но вы все еще придумали архитектуру данных завода до или вместе с кодом завода и архитектуру данных станка до или вместе с кодом станка.
В этом смысле Я пожалуй согласен со статьей — Data-First
Но в остальном так себе — соломенное чучело ООП
А если я пишу код с абстрактними данными, ну, например, у всех методов и конструкторов абстрактный param: Object единственный параметр, который уточняется, специфицируется по мере необходимости?
Просто она достигает гибкости не за бесплатно — позднее связывание и дополнительные проверки/конвертации могут запутать код.
Если бы у вас было больше спецификаций и вы бы сделали базовый параметр с необходимыми базовыми свойствами — вышло бы лучше, но почему бы и нет.
Причем такая архитектура есть.
Android спокойно живет с активностями, данные через которые передаются через интенты — по сути словари строка-объект.
Каждая активность может сама создавать их и принимать/интерпретировать. О передаче посередине заботится система.
И ничего, живут как то, довольно простая и универсальная система.
Я не про позднее связывание, а про уточнение низкоуровневых бизнес-требований в процессе разработки. На высоком уровне у нас бизнес-процесс с, обычно, названиями его состояний и высокоуровневых событий и какой-то схемой переходов. Этого достаточно обычно, чтобы, грубо говоря, написать класс, отвечающий за процесс. Потом начинаем уточнять у бизнеса какие данные ему нужны на вход и выход каждого элемента, где их брать и т. п. и на уровне кода или каких-то схем выстраиваем структуры данных для работы и хранения, а также, при необходимости, маппинг между ними.
Обычное итеративная разработка сверх вних.
Ну или я и правда ничего не понял.Вы правда ничего не поняли. Вся эта история восходит к мифическому человеко-месяцу и в оригинале звучит так: «Стратегические находки приходят в результате изменения способа представления данных или таблиц. Именно здесь лежит сердце программы. Покажите мне ваши блок-схемы, но спрячьте таблицы, и я останусь в неведении. Покажите мне ваши таблицы, и мне уже не надо смотреть блок-схемы, они и так очевидны.»
Это, как бы, 1975й год, до увлечения ООП ещё далеко… речь идёт «всего лишь» о проекте, перевернувшим всю IT-индустрию…
А с ООП, как вы правильно замечаете «можно писать код, частично независимый от архитектуры данных». Ну это всё равно как строить водопровод и канализацию «частично независимо от физических свойств воды». Можно разработать такую технологию? Не вопрос. Только тогда вам для того, чтобы налить чашку воды потребуется три энергоблока АЭС, а чтобы суп сварить — десять новых электростанций вы начнёте задумываться над тем, что что-то в этом подходе «не так». А в программировании — за счёт дикого запаса прочности — эти подходы прижились…
Вот именно, что код оперирует данными. Но не для оперирования данными он обычно пишется, а для решения какой-то задачи. Решение задач — смысл кода, а оперирование данными — способ реализации этого смысла, свойство кода, он вынужден оперировать данными, чтобы решать задачу. Какие данные и в каком виде нам нужны для решения задачи часто нельзя определить, не начав писать код, блок-схемы или иные виды представления алгоритмов, пускай и в голове.
он вынужден оперировать данными, чтобы решать задачу.
Ну так и что первично, в таком случае? Данные, например, не требуют наличия какого-либо кода для своего существования. Попробуйте придумать функцию с пустыми входными/выходными аргументами, решающую какую-либо задачу. Или объект с пустым конструктором, без set'еров и с аналогичным методом (без входных/выходных аргументов)?
Я могу определить иерархию абстрактных классов не имеющих ни одного метода с входными-выходными аргументами или набор интерфейсов с такими же свойствами и сказать, что вот он — код без данных. Можно даже сделать обычный класс, наследующий от и имплементирующий. И потом чесать репу, как доставить данные вовнутрь, чтобы задача, для которой написан этот код, решалась. Так стоит ли ставить телегу впереди лошади и писать код, который вынужден оперировать данными, чтобы решать задачу, не определяясь с тем, какими же все-таки данными он вынужден оперировать?
Очень часто задачи ставятся в виде подобном "при наступлении такого-то события (пользователь нажал клавишу в игре, потенциальный клиент захотел заключить сделку в B2* системах и т.п.) должна біть такая-то реакция (у монстра уменьшилась жизнь, система выдала договор на подпись) мы сначал как-то составляем алгоритм, а лишь потом определяем а какие входные и выходные данные нам нужны. Мы можем набросать код типа
class ContractSigningProccess {
private Contract contract
static start(): self;
signByCustomer(): void;
signBySupplier(): void;
getStatus(): string ;
getContract(): Contract;
}, пустой класс Contract, и простой скрипт, генерирующий события. Написать минимальный код без всяких данных и начать уточнять а что собственно, какие данные должны быть на входе и выходе каждого из шагов, какие ограничения должны соблюдаться и т. п. Сначала описываем процесс обработки абстрактных данных, а уж потом специфицируем данные, определяем откуда и как их будем брать, как преобразовывать и куда отправлять.
И это процесс — лошадь, который тянет за собой телегу данных. Обычно в моём мире задачи не ставят в виде "нам нужно преобразовать ФИО клиента и его корзину товаров в счёт для оплаты"
private Contract contractСначала описываем процесс обработки абстрактных данных
А абстрактные данные уже не данные?
Нет, не данные :)
Абстрактные данные не данные? В таком случае мы с вами не придём к общему знаменателю — у нас различное мировоззрение.
Похоже на то, я могу оперировать абстрактными типами данных, абстрактными структурами данных и т. п., но абстрактные данные я не могу вообразить.
Сначала описываем процесс обработки абстрактных данных
Тем не менее, вы можете описать процесс обработки того, чего вообразить не можете.
Я не умею в ООП, поэтому ООП плохой— это все, что нужно знать о данной статье
wiki.c2.com/?ArgumentsAgainstOop
часть вполне себе объективные.
Просто на мой взгляд, критика автора сама по себе слабая.
Меня больше возмутила даже не слабая аргументация сама по себе, а выводы которые автор пытается сделать:
«ООП плохой в некоторых сценариях <слабые аргументы>, поэтому не нужно его использовать вообще».
С таким подходом ВООБЩЕ ничего нельзя использовать, сидеть и ждать когда идеальная методология разработки всего упадёт аки манна небесная.
Имхо, хорошая методология должна быть дружелюбной в том числе к неопытным.
Я сам сторонник ООП подхода, но отвергать любую критику вовсе — быть фанатиком.
Например, организация объектов по ссылкам делает объекты удобными для понимания, но недружными к кешу процессора.
Есть подходы, когда данные реорганизуют под производительность. ECS
Впрочем тяжело сказать, является это проблемой прямо ООП или его нынешних организаций.
Может это проблема процессоров и кэшей? ;)
Время программистов дороже, чем машинное, все дела. Компьютерные мощности в мире и на 1 % не утилизируются так то.
Но если целевое оборудование определено или задача требует выжать максимум возможностей — проблемы процессоров и кешей становятся нашими проблемами.
Нужно уметь их решать.
Если ООП мешает — нужно решать в ущерб ООП.
Благо жить можно и так, к тому же такие места обычно редки — вполне можно пожертвовать сложностью и читаемостью ради них.
Вызубрить мантру НаследованиеИнкапсуляцияПолиморфизм сможет любой ребенок 3х лет за две недели и пачку конфет. Научиться разнообразию методик и техник, понять, почему они существуют и как взаимодействуют друг с другом — тут надо и думать, и книжки читать.
Но, у нас на это нет времени, товарищ! Код должен работать еще вчера, так что мы тут используем архитектуру с синглтон-сервисами (чтоб по ооп!), которые в себе не будут содержать данных (только объекты с интерфейсом, состоящим из геттеров и сеттеров), а будут все-все знать о правилах, по которым должна работать система (в виде IFов, конечно, как еще можно по-вашему выражать правила, не смеши мои опытные портянки, я 15 лет код пишу, все остальное от дьявола и
ФП точно так же уводит в сторону. Кратчайший путь — это императивная лапша.
Дело в том, что написать код для машины, который работает, может любой дурак, а вот написать код для человека, такой, что его можно будет поддерживать и развивать лет 10 силами других сотрудников и без переписывания с нуля — вот тут уже посложнее.
Код как раз пишется для машин. А для человека пишется база знаний. «Любой дурак» — это тот, кто пытается подменить человекочитаемую базу знаний кодом с комментариями)
Суровая реальность ИТ в том, что большинство бизнесов или долго не живут, или быстро не развиваются. Поэтому почти никогда нет нужды 10 лет что-то там активно поддерживать и развивать.
Сказку про «других сотрудников», развивающих чей-то легаси код я тоже слышал. Но в реальности код неотрывно связан со своим создателем, ибо основан на миллионах неявных логических моделей и связей, которые никак не отражены в коде, но присутствуют в голове автора. Стоит отделить автора от его кода, и он превращается в «наглядное пособие». Поэтому наиболее эффективно, когда новый программист пишет с нуля новый код под себя и в соответствии с зафиксированными в старом коде требованиями заказчика. Выбросить код не так страшно как кажется.
Деградация кода неизбежна, как ни старайся. Даже если всё поектировать идеально, бизнес постоянно меняет условия игры и старые архитектурные решения перестают соответствовать реальности. В итоге в определённый момент всю систему проще полностью переписать с нуля, чем продолжать её мучительные переделки, которые с каждой новой фичёй даются всё сложнее и сложнее.
императивная лапша
Вы забываете о структурах данных, которые идут на вход в систему. А также о бизнес-процессах, которые рождают и используют эти структуры данных. Проектирование решения — это работа и с бизнес-процессами, и со структурами данных, и с алгоритмами. Если это всё не разделить оптимальным образом и не продумать, то лапша как раз и получится. Не важно на чём описывать алгоритмы — на ООП, на ФП, в декларативном или императивном стиле.
Поэтому я считаю, что кратчайший путь — это оптимальная декомпозиция для решения актуальной задачу бизнеса, которое не создаёт ему дополнительных проблем и не тратит время и деньги попусту.
Но в реальности код неотрывно связан со своим создателем, ибо основан на миллионах неявных логических моделей и связей, которые никак не отражены в коде, но присутствуют в голове автора.К сожалению или к счастью, но в суровом ынтырпрайзе — это не так. Там — совершенно нормально «для оптимизации затрат» перекинуть код из офиса в Бангалоре в офис в Токио или наоборот. И для того, чтобы это было возможно — и нужен весь этот ООП и Фабрика Фабрик Фабрик.
Поэтому наиболее эффективно, когда новый программист пишет с нуля новый код под себя и в соответствии с зафиксированными в старом коде требованиями заказчика.Это — совсем другой подход и применяется в совсем других случаях.
Выбросить код не так страшно как кажется.Только в тех случаях, когда информация о том, что код должен-таки делать содержится где-то ещё.
Выбросить код не так страшно как кажется.
Только в тех случаях, когда информация о том, что код должен-таки делать содержится где-то ещё.
Ну тут я вижу, что Вы в принципе не владеете методами оценки состояния инфо-проекта на уровне бизнеса.
Допустим, я пришёл в контору, где есть кодовая база. Все программисты разбежались. Что я буду делать? Полезу в код? Полезу в багтрекер? Полезу в их внутреннюю вики? Нет.
Я посмотрю внедрён ли этот продукт в реальный бизнес-процесс. Если нет, то ценность в нём нулевая — выкидываю смело и начинаю разработку заново с нуля с владельцем бизнеса.
Если проект внедрён, то я анализирую этот бизнес процесс и составляю его модель (база знаний по проекту). Эта модель как раз и будет содержать актуальные общие требования к системе. Далее я проанализирую структуры данных, с которыми работают реальные пользователи. Что они получают на входе, что должны получить на выходе, как это структурируют, всё ли в этом процессе оптимально устроено. В 100% случаев оказывается, что имеющийся код не соответствует реальному бизнес-процессу, потому что делался под другие требования, а потом жестоко хачился. Соответственно и заглядывать туда не стоит — я делаю за несколько недель (обычно этого срока достаточно) собственную систему для осуществления тех же бизнес-процессов и работы с теми же структурами данных, а потом незаметно подменяю одно другим. И вуаля — теперь у меня код мой, подконтрольный и прагматичный. А не какой-то легаси-монстр, с которым надо по неделе за каждую новую кнопочку сражаться.
Что дальше? А дальше идёт оптимизация и модификация бизнес-процессов для повышения прибыли компании. Больше всего этот процесс затрагивает структуры данных, а код для алгоритмов тянется уже в хвосте.
Теперь хотелось бы услышать про Ваш опыт организации миграции проектов из Бангалора (а точнее из Бенгалуру) в Токио. И как на практике ООП в этом помог.
И вуаля — теперь у меня код мой, подконтрольный и прагматичный. А не какой-то легаси-монстр, с которым надо по неделе за каждую новую кнопочку сражаться.
А через полгода вы увольняетесь, на ваше место приходит другой разработчик и все начинается по новой? :)
А если вдруг захочется взять и кардинально что-то поменять, тогда он наймёт себе CTO, который оценит бизнес-процессы, соберёт команду разработчиков и вместе с ними решит что лучше — разбираться в моём легаси-коде или переписать всё с нуля. Но это уже совсем другая история и не про меня.
Я описал цикл продажи компании. А вы спрашиваете о цикле релизов. Вы знаете в чём разница?
Проект развивается постоянно. До продажи компании это осуществляется нашими силами. После продажи — силами нового владельца.
Мы оформляем информационные системы так, чтобы заказчик мог без программистов менять свойства информационной системы для нужд своего бизнеса. Обычно для этого используется документация с методиками и кастомный domain specific language, который мы разрабатываем под каждый конкретный проект. Таким образом после продажи для развития проекта уже нет нужды лезть в кодовую базу или в структуры данных. Что тут противоречивого?)
Вы решаете очень специфичные задачи с очень специфичными метриками. Кстати, заглянете в код, если он единственное место, где описан бизнес-процесс полностью, если в компании нет никого, кто мог бы его описать полностью? Каждый знает только свою роль в процессе, но никто не знает, например, когда и почему система требует о него конкретных действий?
Обычно я ухожу из компании, когда она успешно продана.Ну в этом случае вас действительно должно мало волновать что с ней произойдёт после продажи… но ведь что-то же с ней происходит. Вы никогда не задумывались — что?
А зачем задуматься? Я и так знаю что произошло со всеми моими проектами. Если проблемы и возникали, то не на уровне технологий, а на уровне развития бизнеса. Иногда из-за неверных управленческих решений новый владелец сам разоряет свой бизнес. Тут уж я ничем не могу помочь.
А иногда всё идёт нормально. Короче, кому как повезло)
— успеть продать бизнес раньше, чем его решат отжать.
Если программист уходит в отпуск, и обнаруживают ошибку весь код переписывается. Когда он возвращается — он переписывается обратно.
Будут ещё какие-то домыслы про возможные проблемы? Или смиритесь, что мой подход рабочий?
Или смиритесь, что мой подход рабочий?Ваш подход рабочий, исключительно за счёт того, что вы никогда не сталкивались с задачами того размера, где нужен ООП.
Если один человек в принципе способен разобраться в коде — то тут вообще не нужно обсуждать никакие принципы и подходы. Как ему захочется — так и сделает. Может даже блок-схему со спегетти кодом на доске нарисовать или, прости господи, ДРАКОН, привлечь.
Проблемы начинаются тогда, когда размеры кодовой базы и/или организации становятся слишком велики для того, чтобы уместиться в одну голову.
И вот тут-то ваш подход «рассыпается». Вы не сможете ничего узнать у «владельца бизнеса», потому что тот появляется в компании раз в квартал, на собрании акционеров и о «бизнес-процессе» знает чуть более, чем ничего. Вы не сможете понять как устроен бизнес-процесс, опрашивая рядовых сотрудников, так как новые структурные подразделения открываются и закрываются каждый день. Ну Ok, может быть через день. Даже если вам в попу вставить реактивный двигатель — вы всё равно всюду не поспеете за изменением «бизнес-процесса». Структуры данных? Ну вот буквально вчера обсуждали вопрос: как лучше разбить класс на два, если он используется в 283 тысячах файлов (не строк, файлов). Успехов вам в выяснении того, что эти 283 тысячи файлов делают.
И так далее. Тот факт, что вы никогда не сталкивались с большими программами (а определение большой программы: это программа, объём исходных кодов в которой больше, чем может поместиться в голову одного человека) — не значит, что их не существует.
Да, для проектов, которые могут «осилить» 5-10 человек — ваш подход годится. Уже 30 человек — сомнительно: в коде начинают пониматься места, которые вы не понимаете. 1000 человек? 10000 человек? Оно просто не работает!
- В последние годы я вообще не лезу в код проектов, которыми руковожу. Я не знаю сколько там файлов, строк кода, я даже не знаю есть ли там ООП. Но я досконально знаю требования заказчика, наш технологический стек и его свойства, каждого разработчика и его зону ответственности, и лично провожу ревью каждой фичи.
- Спарта — здесь я был рядовым программистом, на проекте работало 50 человек. Код был фаршем на С++ ровно в том стиле, который пропагандирует @S_Revan в своих комментах.
- Сочи — здесь я был тех лидом, на проекте работало 30 человек. Код — модульный C# под Unity.
- С 2013 года я сознательно не занимался проектами с командой более 10 человек. При этом время, которое я провожу на работе, сократилось в 2 раза, мои доходы выросли в 1,5-2 раза, я получил возможность жить в любой точке мира (что в 2 раза дешевле Москвы и в 100 раз интереснее).
Зачем мне ваши 1000-100000 человек и должность «раб лампы»?)
У нас весь отдел разработки уходит в отпуск одновременно.
и болеют тоже. А если кто-то попадает под машину расстреливают весь отдел. А если человек загружен задачей и появляется еще одна задача в его области, то соответсвующая часть кода стирается и переписывается.
Предварительно мы приводим инфосистему к стабильному состоянию, в котором она работает без проблем и без постоянной поддержки со стороны разработчиков.
А если все-таки случается инцидент требующий такой поддержки? Вы пишете вообще без ошибок? Срочная задача, например?
Или смиритесь, что мой подход рабочий?
Вы, наверное, живете в параллельном мире.
Под функциональным кодом я понимаю код, который описывает функции и даёт прямой видимый эффект. Про концепцию ФП я вообще тут не говорю.
Это называется "процедурное программирование".
Код как раз пишется для машин. А для человека пишется база знаний. [...] Проектирование решения — это работа и с бизнес-процессами, и со структурами данных, и с алгоритмами.
Правильный ООП как раз хорош тем, что заставляет писать код на языке бизнеса, отражать бизнес-процессы в коде (DDD по сути про это). В паре с BDD код и тесты будут той самой базой знаний — полученной бесплатно и никогда не устаревающей.
Правильный ФП, в принципе, тоже позволяет это делать, просто в среде функциональщиков об этом редко задумываются.
Да нет, типичный ООП обычно обрастает всякими менеджерами, провайдерами и фабриками адаптеров стратегий, отражения которым в домене никаких нет, просто паттерны и подпорки для проектирования в терминах ооп. Вообще подход "все есть объект" обычно не более полезен, чем "все есть указатель" или "все есть файл". Иногда чтобы удовлетворить данному утверждению начинают совмещать ежа с ужом. Если это нужно делать часто, то это называют "паттерном". Пример с современными DI я уже приводил, по сути тот же сервис локатор (который все давно ругать научились), только в профиль.
Я бы сказал, что всё будет плохо пока люди не будут задумываться о правильных вещах, или о том что для них вообще важно и нужно, какую бы парадигму они не пытались прикрутить, потому что в данном случае выбор идет лишь по принципу «ну я знаю ООП» или «ну я знаю ФП», или «Ну вокруг говорят что X это круто»
В ООП при правильном подходе (DDD например), хотя бы часть кода описывает модель в более-менее понятных терминах и ее можно даже бизнесу объяснить (в отличие от ФП). А паттернами все обрастает от неумения строить объектную модель, по-моему.
Менеджер — часто просто неудачное название, если сильно захотеть, то из бизнеса можно вытащить реальное.
А провайдеры часто в домене есть, они появляются при ответе на вопрос: откуда эти данные берутся?
Не может быть провайдеров в домене. Может быть интерфейс, описывающий протокол получения сущностей (EntityRepositoryInterface, скажем), да и это нужно далеко не всегда.
Конкретная реализация уже вне домена, домену все равно, откуда данные берутся и как они мапятся на сущности.
Вы говорите языком программиста, пишущего модель домена. Я же говорю о домене, в котором есть, например, клиенты, поставщики, иные внешние контрагенты, сотрудники разных подразделений, топ-менеджмент, собственники, внутренние и внешние автоматические сервисы и т. п. Они все, например, могут поставлять для процесса начисления НДФЛ определённые данные, необходимые для него. Кто они как не провайдеры этих данных?
На уровне домена никаких менеджеров и фабрик адаптеров стратегий быть не может. Если они там появились, это проблема. На уровне инфраструктуры это вполне нормально там, где такая гибкость требуется. Пихать их везде и всюду — это такая болезнь человека, который недавно понял паттерны, проходит со временем.
Про DI и сервис-локатор: любой DI это одновременно и сервис-локатор. DI отличается от SL не столько реализацией, сколько использованием: при нормальном использовании DI от него нет прямой зависимости (как от сервис-локатора), классы просто принимают свои зависимости в конструкторе, и всегда можно их повторно использовать безо всякого DI или там SL.
Я бы сформулировал разницу так: SL — библиотека, DI-контейнер — фреймворк :)
Мне с DI очень не нравится словить ошибку из-за того, что тип не зарегистрирован. Один раз смешно было, что интерфейс был в одной библиотеке, а реализация в другой. И одно из четырех приложений, использующих этот интерфейс вообще не ссылалось (и не могло, из-за несовместимостей в версиях библиотек) ссылаться на библиотеку, где была объявлена реализация. Ну а обнаружилось это, конечно, когда все в рантайме упало, когда понадобилось этот объект инстанцировать.
Заменять компайл-тайм проверки на динамику — зло. Никакие "ну тут зато мокнуть можно и сконфигурировать в одном месте" не помощники. Конфигурировать и так пришлось бы в одном месте, но явно в типах, а не в пространных флюент-ассертах.
Если вспомнить старика Кея, то весь ООП про динамику и late binding.
В принципе, не вижу большой разницы, ну свалится не при компиляции, а в test suite, ну, на минуту позже обнаружили.
Я вам конкретный пример привел, как так получилось на практике. Советовать тесты вместо типов может только самый глубокий приверженец динамики.
Да я не то, что советую. Я бы не отказался от compile-time DIC, вон как в Kotlin-е делают. А когда и так пишешь на динамическом языке, все равно есть еще 100500 способов облажаться. :-) Это ж не повод все фигачить статикой. Если выстроены нормальные процессы, а не "раз-два и в продакшен", таких ситуаций минимум.
Мне с DI очень не нравится словить ошибку из-за того, что тип не зарегистрирован.
Нормальные DI фреймворки должны давать ошибку о том, что тип не зарегистрирован :hz:
Проблема COBOL-кода — в том, что
- к нему не известны все требования (каждое требование в отдельности кому-то известно, иначе это не было бы требованием — но вот вместо их так просто не собрать);
- его нельзя переписать на новый язык по частям;
- его просто много.
Не не для любого старого кода все эти требования выполняются одновременно...
Ожидал увидеть под конец статьи "а вот смотрите, как надо", и пару ссылок на гитхаб с используемыми в реальной жизни репозииориями, в коде которых нет ни одного класса, только лишь функциональщина.
То есть у меня будет некий объект…
В данном примере функции могут иметь сайд-эффекты, которые будут влиять на работу всех остальных функций. При функциональном подходе такого быть не должно.
Это подход, при котором функция является объектом первого рода: функции можно передавать как параметры, а также создавать новые в процессе работы.
В крайнем случае кроме объявления функции и её вызова вообще никаких конструкций не используется. Или даже объявление функции заменяется кучкой стандартных комбинаторов.
Также в последнее время с ФП связывают идею "чистоты": структуры данных в ФП обязаны быть иммутабельными, а функции обязаны не иметь побочных эффектов и возвращать тот же самый результат при повторном вызове.
Если что, с автором не согласен. И это уже не первая статья в духе «ООП это плохо» когда берут кривую реализацию и из неё делают такой странный вывод.
* 2 репозитория
* используемых в реальной жизни
* в коде нет ни одного класса
* одна «функциональщина»
Какие претензии?
Все кто критикует ооп функциональщики? Кстати в качестве 'решения' автор предлагает все то же ооп, только со слегка иным вкусом
Это гитхаб автора оригинального поста, ссылка на него есть у него в блоге, на вкладке open source.
Пример кода:
function generateCommonMenu($nas_name)
{
global $tpl;
global $config;
$tpl->addBlockfile("common_menu", "common_menu", "common_menu.html");
$tpl->setVariable("nas", $nas_name);
$tpl->setVariable("edit_url",
generateUrl(
array("mg" => "nas", "mm" => "edit", "nas" => $nas_name)
)
);
$tpl->setVariable("info_url",
generateUrl(
array("mg" => "nas", "mm" => "info", "nas" => $nas_name)
)
);
$tpl->setVariable("acct_url",
generateUrl(
array("mg" => "acct", "mm" => "generic",
"value" => $nas_name, "search" => "nas-name")
)
);
$tpl->setVariable("online_url",
generateUrl(
array("mm" => "users-online", "mg" => "nas",
"nas" => $nas_name)
)
);
$nas_info = getNas($nas_name);
if ($nas_info) {
$tpl->setVariable("nas_common_nas_descr",
htmlentities(
$nas_info[SQL_NAS_COLUMN_DESCRIPTION],
ENT_QUOTES, "UTF-8"
)
);
}
}
?>Я не искал специально худший кусок, я просмотрел с десяток файлов из разных модулей и они все выглядят примерно как в спойлере выше.
Так что нет уж, спасибо, пойду я дальше пилить кучу классов на каждый чих с методами по 5 строк, а разбираться в таком коде из непонятных типов, имен, и глобальных переменных останется моим страшным сном.
Ну, через текст статьи уже проступает некоторая "ржавчина" ) В Rust нет ООП (в смысле наследования данных и образования подтипов с помощью наследования), нет культуры обязательного наличия геттеров/сеттеров, уровень доступа к полям можно ограничивать видимостью в модуле и т.п. Rust снимает большинство претензий автора.
Злоупотребление наследованием и геттеры-сеттеры — это неправильное ООП. Проблема не в ООП, а в том, что плохие подходы стали широко использоваться, и в умах тут появился знак равенства.
Если придерживаться более разумных практик, то между Растом и Simula-подобными языками разница в определенном смысле будет чисто синтаксическая по большому счету.
Это вряд ли. Проблема ООП (в том виде как оно реализовано в мейнстримовых языках) как минимум в том, что в нем смешивается наследование с образованием подтипов.
Можно ваши определения наследования и образования подтипов?
Наследование и полиморфизм подтипов
Наследование удобно использовать для синтаксического расширения существующего класса: когда потомок имеет те же поля и методы, что и предок + свои. Далеко не всегда желательно, чтобы при этом потомок был подтипом предка. И наоборот, часто для образования подтипа приходится использовать наследование и тянуть в потомка все содержимое предка, хотя это и не нужно.
Вот вам пример для иллюстрации проблемы: есть класс Rectangle и Square. Ясно, что Square должен быть подтипом Rectangle, но наследование реализации при этом не желательно. Эффективная реализация Square должна хранить только поле a, вместо двух полей a и b, которые она получила бы в наследство от Rectangle.
Далеко не всегда желательно, чтобы при этом потомок был подтипом предка
Но как это возможно в принципе? Для того, чтобы вызвать унаследованный от предка метод, требуется привести объект-потомок к типу предка. Или есть ещё какие-то варианты?
И наоборот, часто для образования подтипа приходится использовать наследование и тянуть в потомка все содержимое предка, хотя это и не нужно
Эта проблема решается интерфейсами.
Наследование удобно использовать для синтаксического расширения существующего класса: когда потомок имеет те же поля и методы, что и предок + свои. Далеко не всегда желательно, чтобы при этом потомок был подтипом предка.
То есть просто чтобы код копипастить?
Стоит подумать как избавиться от копипасты кода, возможно этой логикой должен обладать какой-то другой класс/объект/модуль.
И наоборот, часто для образования подтипа приходится использовать наследование и тянуть в потомка все содержимое предка, хотя это и не нужно.
Так не наследуйтесь. Неграмотное использование наследование один из важных источников проблем в проектах.
есть класс Rectangle и Square. Ясно, что Square должен быть подтипом Rectangle
Кому ясно, и с чего бы ему им быть?
Square даже по определению
subtype is a datatype that is related to another datatype (the supertype) by some notion of substitutability, meaning that program elements, typically subroutines or functions, written to operate on elements of the supertype can also operate on elements of the subtype.
подтипом Rectangle не является
возможно этой логикой должен обладать какой-то другой класс/объект/модуль
Конечно, можно использовать аггрегацию. И в Rust, где нет наследования, так в основном и делают. Но часто при этом еще возникает необходимость пробрасывать вызовы методов. Вручную писать такое — это бойлерплейт, поэтому в Rust ведется работа по добавлению в язык делегатов.
Иначе обстоит дело в ООП языках. Там есть соблазн просто унаследоваться. И так делают достаточно часто — используют наследование именно для расширения, а о том, что при этом еще и полиморфизм подтипов начинает работать, не думают. Иногда это приводит к проблемам.
Square даже по определению подтипом Rectangle не является
И почему это? Квадрат — частный случай прямоугольника. То есть там, где мы ожидаем прямоугольник, всегда должно быть можно подставить квадрат. Вы с этим спорите?
Ну например при попытке изменить размеры этого "прямоугольника" вас ждет фиаско.
А почему в понятие "квадрат" входит операция "изменить размеры и остаться квадратом". Не может ли быть квадратных констант? Не может ли (теоретически) квадрат перестать быть квадратом?
Потому что определение прямоугольника не зависит от размеров его сторон, а значит операция "изменения размеров" вполне себе валидна для прямоугольников. Если говорить математически и иммутабельно, то это должно быть что-то вроде
data Rectangle { width: u32; height: u32 }
fn with_height<T>(rectangle: T, new_height: u32): T
where T : Rectangle {
T {
width: rectangle.width,
height: new_height
}
}Ну или давайте проще, если мы меняем высоту квадрата, должны ли мы менять его ширину?
Как раз в иммутабельном случае всё просто: операция "изменить высоту" всегда возвращает прямоугольник, даже если применена к квадрату.
Проблема в том, что объекты в ООП бывают мутабельными.
Однако, если ширина равна высоте, то это прямоугольник является ещё и квадратом.
Ну это так работать не будет, ведь это поломает любые декораторы. И как вы правильно заметили, для произвольного T это тоже реализовывать не очень правильно. А если сюда же добавить то, что для хранения такого квадрата придется потратить в 2 раза больше места, что на миллионах объектов будет заметным, и получаем, что наследование поведения вместо требований плохая штука.
Потому что определение прямоугольника не зависит от размеров его сторон.
То есть для любого прямоугольника в мире имеет смысл операции "изменение сторон"? Константые прямоугольники или вычисляемые прямоугольники запрещены?
Поработав с нормальными языками, я пришел к выводу, что лучше когда неизменяемость это свойства биндинга, а не типа.
биндинга чего к чему?
Значения к имени.
Можете проиллюстрировать? Имеется ввиду readonly Rect rect?
Это работает только для простых структур данных. Для чего-то более сложного изменяемая и неизменяемая версия принципиально отличаются набором допустимых операций, и никаким модификатором снаружи это не изменить.
Но соглашусь что для DTO подключаемая неизменяемость — идея хорошая, в C# её очень не хватает.
Ну да, принципиально отличаются — для неизменяемой структуры, говоря терминами Rust, нельзя взять &mut (т.е. послать её в функцию, включая её собственные методы, которые могут её изменить). Правда, какие есть отличия, не вытекающие из этого, я не очень понимаю.
Существует такая структура данных, как "изменяемая очередь". Чтобы достать из такой элемент — надо иметь изменяемый биндинг к очереди, иначе всё что можно с такой очередью сделать — проверить её на пустоту.
А вот структура данных "неизменяемая очередь" позволяет извлекать из нее элементы в любой ситуации (извлечение элемента из такой очереди даёт вам очередной элемент и легковесную копию очереди без элемента).
Работает в любых случаях, проверено.
А вот ридонли типы наоборот фигово. Ты владеешь единственной копией ImmutableArray и захотел добавить элемент? Хрен там, копируй все.
В том-то и дело, что для ImmutableArray копирование дешевле, чем для простого массива.
Кстати, вполне допускаю возможность изменения ImmutableArray на месте, если статически доказано что это единственная копия.
То есть ImmutableArray вполне выигрывает от контроля владения в стиле rust, но обычным массивом он всё равно не становится.
В том-то и дело, что с такой схемой копирование вообще не нужно :) Ну вот мы допустим делаем
struct Foo {
arr: List<Int>;
pub fn update(&mut self, value: Int) {
self.arr.add(value);
}
pub fn contains(&self, predicate: Fn(List<Int>) -> bool): bool{
predicate(self.arr)
}
}В итоге вообще не надо ничего копировать, лямбда по-умолчанию не может ничего изменить.
А когда в типах кодируем либо лишние копирования имеем, либо еще что. До сих пор помню, как умники в C# коде делали
IReadOnlyList<int> readonltList = ...;
list = (List<int>) readonlyList;
list.Add(123);бррр
Иногда копирование таки нужно. Было бы не нужно — не было бы в Rust трейта Clone :-)
Иногда нужно. Но в данной ситуации — не обязательно. В C# мне обязательно нужно будет создавать какой-нибудь враппер, чтобы он не позволил модификацию коллекции. Причем гарантированно рабочим варианнтом будет только копирование. В том же сишарпе ReadOnlyList это просто коллекция с тем же апи, которая бросает эксепшоны на попытку модификации. Но никто не мешает объекту, держащему оригинальную ссылку модифицировать "типа ридонли" список.
Баги из-за такого тоже встречал.
Если говорить математически и иммутабельно, то это должно быть что-то вроде
Я говорю не про иммутабельность а про отсутствие мутабельности. Т.е. тип не гарантирует наличие либо отсутствие мутабельности:
interface Rectangle
{
int Height{ get; }
int Width{ get; }
}Т.е. на прямоугольник вообще не накладывается обязанность, что все его данные где-то хранятся, это может быть динамически вычичляемый по требованию прямоугольник. Или константный прямоугольник 2*1 или прямоугольник для которого хранится размер одной стороны. Или обычный мутабельный прямоугольник который хранит размер двух сторон.
Мне кажется, было бы неплохо, если бы в языках программирования (императивных с ООП) можно было сделать что-то такое:
class Rectangle {
int width;
int height;
}
class Square variant of Rectangle {
bool __match() {
return this.width == this.height;
}
}
int f(Square x) {
...
}
var r = new Rectangle(10, 10);
f(r as Square); // call __match(), success
var r2 = new Rectangle(10, 20);
f(r2 as Square); // call __match(), runtime errorНу так можно сделать, только у вас as магический метод, а в некоторых языках есть стандартный.
В C# вы сможете сделать if (var r is Square s) ...
Не, в C# как я понимаю переменная уже должна быть Square или его наследником. А я предлагаю, чтобы переменная всегда была Rectangle, но при некоторых значениях полей ту же самую переменную можно было бы использовать как Square. Получаются runtime-типы.
Нет, В C# можно переопределить оператор чтобы работало и не только с наследниками.
Тут пишут, что is переопределить нельзя. Даже если было бы можно, я не могу представить, как это может работать с переопределением, мне кажется нужна поддержка рантайма для именно такого поведения.
Да нет, там тупой код достаточно. Просто пишете статик функцию аналогично тому, как + или — там определить кастомный и оно работало. Оно для такой кастомной деконструкции использовалось. найти к сожалению не могу источник. Может, передумали и не стали в итоге делать, я в превью это видел.
Вспомнил, где видел, вот здесь.
И выглядит это так:
public static class Polar
{
public static bool operator is(Cartesian c, out double R, out double Theta)
{
R = Math.Sqrt(c.X*c.X + c.Y*c.Y);
Theta = Math.Atan2(c.Y, c.X);
return c.X != 0 || c.Y != 0;
}
}bool __match() { return this.width == this.height; }
False negative при вещественном сравнении, не?
del
Иначе обстоит дело в ООП языках. Там есть соблазн просто унаследоваться. И так делают достаточно часто — используют наследование именно для расширения, а о том, что при этом еще и полиморфизм подтипов начинает работать, не думают. Иногда это приводит к проблемам.
В языках без наследования люди больше/чаще думать не станут, и именно это будет приводить к проблемам.
И почему это? Квадрат — частный случай прямоугольника. То есть там, где мы ожидаем прямоугольник, всегда должно быть можно подставить квадрат. Вы с этим спорите?
Вообще, зависит от абстракции, в одних ситуациях квадрат будет подтипом прямоугольника, в других нет.
Если у нас иммутабельные объекты и мы не столкнемся с проблемой синхронного изменения сторон у квадрата, никаких проблем.
И почему это? Квадрат — частный случай прямоугольника.
Вы не путайте геометрические фигуры и программные сущности. Геометрическая фигура "квадрат" — частный случай геометрической фигуры "прямоугольник", да.
А вот класс Square по отношению к классу Rectangle может как быть подтипом, так и не быть, в зависимости от конкретного интерфейса и его реализации.
Квадрат также частный случай ромба. Квадраты — пересечение множеств ромбов и прямоугольников. Именно пересечение, а не объединение. Вроде мэйнстрим ООП языки не поддерживают классы как пересечения других классов, в "лучшем" случае как объединение — множественное наследование.
Множественное наследование даёт именно пересечение (в смысле возможных значений).
Откуда пересечение? Допустимые значения множественных наследников состоят из комбинации значений родителей. N значений у первого родителя, M у второго: N*M у наследника в общем случае.
Любой наследник является одновременно и родителем.
Именно. Допустим наследник от классов 8-бит-целое и 3-ascii-символов строка без искусственных ограничений. Для первого у нас 256 значений, для третьего 2048383, итого для итогового объекта у нас 524386048 значений — он может быть любым целым значением и любой строкой, чтобы соблюдать инварианты родителей
Точнее любой наследник реализует публичный интерфейс базового класса и принудительно включает его данные.
В ООП понятие совместимости типов определяется методами, а не свойствами. Какая разница, что там в private-ах?
Просто квадрат и прямоугольник никому не нужны (даже если это value objects — они где-то используются, а не сами по себе): надо рассматривать конкретную предметную область. Скажем, программа для рисования типа paint-а. Тогда все встанет на свои места.
В мэйнстрим ООП совместимость объектных типов обычно определяется иерархией наследования, подразумевающую совместимость публичных свойств, методов, констант. Вашими словами, есть разница, что там во всех public-ах, а не только в public методах. Ещё интерфейсы есть, и в некоторых языках свойства — полноправные их члены.
Если под иерархией наследования понимать то, как это сделано в языках типа С++, где есть множественное наследование и в качестве интерфейсов используются pure abstract классы, тогда соглашусь.
Публичные свойства и константы всегда можно заменить методами, так что это несущественно. Существенно — должны ли там быть публичные методы getWidth() и getHeight(). И обычно ответ такой: если это не Value Objects, то нет.
Из вашего высказывания следует, что если мы не хотим инкапсуляцию, то подойдет ФП. Иными словами, если мы не хотим ООП, то подойдет ФП.
С этим сложно поспорить. :-)
Я немного не понял, почему инкапсуляция оказывается прерогативой ООП? В других парадигмах прятать реализацию и торчать интерфейсом не надо?
Ну это не прерогатива, а одна из двух основных фич. Вторая — сабтайпинг. Если и то и то в языке есть, при этом работает совместным образом (инкапсуляция завязана на подтипирование) то язык, по определению, ООП.
Но если мы что-то одно отрываем, то уже не ООП. Хотя вообще язык без инкапсуляции мне представить трудно, разве что ассемблер. Получается, ООП это сабтайпинг через наследование.
А инкапсуляция есть везде. Про то и был мой вопрос.
Товарищам минусующим предлагаю такой пример на ФП языке
def factorial(n: Int): Int = {
@tailrec
def factorial_impl(x: Int, result: Int): Int =
if (x ==
1) result
else
factorial_impl(x -
1,
result * x)
factorial_impl(n, 1)
}Вопрос, тут есть ООП? Или инкапсуляция итеративной реализации за интерфейсом не считается? Или там
let dbLogger = logTo $ getDatabase dataBaseConnectionтут мы не инкапсулировали доступ к базе за интерфейсом dbLogger?
Здесь как раз подойдет ФП
В ФП будут ровно те же проблемы с тем, что невозможно API менять.
В Value Object как раз сеттеров не должно быть, они должны быть иммутабельны. А public getWidth() вполне может біть и в, например, Entity. Тут, главное, понимать что наличие getWidth() никак не гарантирует наличие private _width в коде класса.
В value object, конечно, только геттеры. (Хотя иногда может быть и как бы сеттер, но который возвращает новый инстанс).
А в Entity — тут такое дело. Быть оно там, конечно, может, но когда объект рассказывает о своих внутренностях, надо сразу задуматься, а зачем мы в Entity добавили такой метод. Если только для того, чтобы эту width потом передать другому объекту, то где-то тут что-то не так, скорее всего.
Надо просто мысленно отделять value objects от всего остального, и все будет хорошо.
А как бы вы записали этот код?
Прежде всего переименовать :) — это не generateCommonMenu, а какой-то buildCommonMenuBlockByNasName.
Потом разделить ответственности. Тут их навсидку 5.
И, как обычно, мне непонятно, как концепция абстрактных типов данных (классы) оказалась столь тесно связана с ООП?!
С такой последовательностью, конечно будет кривой код.
Должно быть:
цель -> алгоритм -> структуры данных -> код
Архитектура данных выбирается в зависимости от алгоритмов,
а не наоборот.
Тогда уж:
цель -> структуры данных -> алгоритм -> структуры данных -> код -> структуры данныхтак как алгоритмы по своей сути — тот же код, только вид сбоку, описание последовательности действий над данными. Прежде, чем создавать последовательность действий, нужно определить, над чем можно производить эти действия. Т.е., определить предметную область. Структуры данных в конце цепочки я для красоты добавил, т.к. обычно код налагает свои ограничения на данные, которыми он может оперировать (MAX_INT, напирмер). Просто для усиления идеи, что в программировании данные фундаментально первичны.
Когда не выбран алгоритм, это значит, что вообще не понятно, как решать задачу. О каких структурах данных можно говорить в этот момент ?
Классическая последовательность: «Зачем? --> Что? --> Как?»
У автора статьи идёт прямая проекция: Зачем? — это цель; Что? — это структура данных; Как? — это реализация, то есть алгоритм или код.
Но некоторые люди могут действовать только на уровне абстракции «Как?», поэтому для них алгоритм первичен, а структуры данных (не говоря уже о целях) околачиваются где-то на задворках сознания. Может быть, в итоге и получается «некривой» код (по субъективному мнению авторов), но почти всегда он приводит к кривому решению бизнес-задачи. Если вообще что-то решает.
Что? — без понятия — какие-то данные, какие-то операции
Как? — расположить данные в таблицу горизонтально или вертикально и проводить одни и другие операции
Мне в принципе думать об этом сложно) Слишком мало информации о задаче. И здесь, как я полагаю, Вы под структурой данных подразумеваете сервисную структуру, которой оперирует алгоритм. Но люди из Data Driven мира под структурой данных всегда имеют ввиду входные данные, которые Вы всё равно не контролируете — они определяются легаси-кодом и устоявшимися бизнес-процессами. А как вы её там трансформируете для своих нужд — это Ваше внутреннее дело.
Приведу пример: как вы будете хранить коллекцию структур в вашей программе — в векторе, листе или мапе? Это зависит от алгоритма, т.е. от того, как ваши структуры будут добавляться, удаляться и как будет происходить их поиск.
как вы будете хранить коллекцию структур в вашей программе?
Прежде чем писать программу, я напишу документ с требованиями к ней. И пока что там зияющая пустота)
Это примерно техзадание на Chrome (когда он ещё был секретным проектом). Просто, не так ли?
Мы тут с Энди уютно общались про векторы, листы и мапы. И вдруг на тебе — Top10000!
Вроде не очень длинное задание…
Если вы реально хотите что-то делать, то начинать обсуждение надо в контексте бюджета. Если вам реально ничего не надо, то не надо тратить время друг друга.

Браузеры кто-то ведь когда-то делал. И операционки. Линус вообще сделал ядро «в одно рыло». И если вы считаете, что ваш подход для них не годится — то так и скажите. Мы поймём.
А вот это «я буду с вами разговаривать только если вы вначале заплатите миллион долларов наличными» — лучше кому-нибудь другому оставьте.
Важно сначала сформулировать задачу, а потом искать способ её решения.
Ну что Вы! Гораздо эффективнее иметь готовое решение и подбирать подходящие задачи! В своих предыдущих постах Вы именно такой подход описали: Вы умеете хорошо делать работающий прототип решения, которое может «запилить» команда в десяток человек и повторяете за разом раз. Благо задач в мире столько, что всегда можно найти подходящую, было бы решение.
)))
А через 30 лет появляется человек и вдруг замечает «а двухколесный велосипед не всегда самый удобный» и начинает делать нечто, что давно сгнило на перфокартах.
Статья довольно слабая, но вот комментарии отлично иллюстрируют проблему. Все изобретают каких то менеджеров, акторы которые там урон разносят команды и стратегии… Тогда как нам просто нужна функция attack(player, monster) - > (newPlayerState, newMonsterState)
Почему менеджер а, не, например, Игра
Мы сейчас говорим на уровне самой функции "нанеси урон". Кто её будет вызывать, вопрос отдельный.
Ну сириузли, посмотрите FizzBuzz enterprise edition. Он неспроста такой. И реально многие люди делают софт именно так. Люди реально разучились думать в терминах функций. Такое ощущение, что люди думают в стиле "блин, если я просто напишу функцию, это будет нерасширяемо и не по гайдлайнам, пацаны засмеют. Запилю-ка я пару классов. Так, теперь надо DI настроить. И автомаппинг на DTO. И вот этот миддлвейр впилить. Во, теперь энтерпрайзненько".
Вот буквально вчера я правил багу с тем, что при некотором стечении обстоятельств тип не регистрировался и мой DI фреймворк выдавал "не смог зарезолвить зависимость Y" с километровым стектрейсом. Почему я должен ловить это в рантайме? А потому что DI это серьезно, это показывает класс. Люди начинают говорить про SOLID, DDD и прочее, как надо инвертировать зависимости и все такое. Много умных слов, а на деле я пытаюсь понять, почему в рантайме вылез null, тогда как я мог все сконфигурировать в компайл тайм и компилятор бы меня проверил. Но нет, этот подход недостаточно серьезный, обязательно надо обмазаться рантайм рефлексией, а тип получать через сервис, даже если у всех интерфейсов всего 1 реализация. После такого смотришь на ФП с их фри монадами, и понимаешь, что жить-то оказывается можно сильно лучше, не теряя при этом инверсию зависимостей.

Но люди смотрят на ФПшников как на академиков, которые дальше своего носа не видят, и не умеют в "настоящую разработку". При этом лямбды и функции высших порядков уже давно нашли дорогу в мейнстрим языки, стримы/итераторы за ними, сейчас наступает черед тайпклассов, паттерн матчингов и отказа от эксепшнов в пользу адт. Причем именно в серьезной разработке обычно все это эмулируется какой-нибудь внутрикорпоративной либой. И неспроста там происходит, я вам скажу.
Слушайте, это уже разговоры в стиле задачи теорвера про подбрасывание монетки "а что если на ребро? А что если в воздухе зависнет?". Это все за рамками обсуждения, мы обсуждаем конкретную модель. Можно подумать, как будет развиваться в этих рамках модель кода. Ну будет множество монстров, можно добавить какой-нибудь параметр типа сплеша и т.п. Общий смысл не меняется. Просто делаем чистую функцию, которая вычисляет результат. Например, мне сейчас пришло в голову, что атака многих монстров может работать через эту функцию. Просто делаем функцию типа
attackMany(player, monsters) ->
let attackResults = monsters.fold((player, List()), (state, monster) ->
let attackResult = attack(state.player, monster);
(attackResult.player, state.monstersState :: attackResult.monsterState)ну и все.
void attack(Unit & player, vector<Unit> & monsters);Я правильно понимаю?
Не совсем. Без функционального стиля вы не сможете сделать композицию нормально, если она понадобится.
Хороший пример из книжки:
Suppose we’re implementing a program to handle purchases at a coffee shop. We’ll begin with a Scala program that uses side effects in its implementation (also called an impure program).
def buyCoffee(cc: CreditCard): Coffee = { val cup = new Coffee() cc.charge(cup.price) cup }
The line cc.charge(cup.price) is an example of a side effect. Charging a credit card involves some interaction with the outside world—suppose it requires contacting the credit card company via some web service, authorizing the transaction, charging the card, and (if successful) persisting some record of the transaction for later reference. But our function merely returns a Coffee and these other actions are happening on the side, hence the term “side effect.” (Again, we’ll define side effects more formally later in this chapter.) As a result of this side effect, the code is difficult to test. We don’t want our tests to actually contact the credit card company and charge the card! This lack of testability is suggesting a design change: arguably, CreditCard shouldn’t have any knowledge baked into it about how to contact the credit card company to actually execute a charge, nor should it have knowledge of how to persist a record of this charge in our internal systems. We can make the code more modular and testable by letting Credit- Card be ignorant of these concerns and passing a Payments object into buyCoffee.
def buyCoffee(cc: CreditCard, p: Payments): Coffee = { val cup = new Coffee() p.charge(cc, cup.price) cup }
Though side effects still occur when we call p.charge(cc, cup.price), we have at least regained some testability. Payments can be an interface, and we can write a mock implementation of this interface that is suitable for testing. But that isn’t ideal either. We’re forced to make Payments an interface, when a concrete class may have been fine otherwise, and any mock implementation will be awkward to use. For example, it might contain some internal state that we’ll have to inspect after the call to buy- Coffee, and our test will have to make sure this state has been appropriately modified (mutated) by the call to charge. We can use a mock framework or similar to handle this detail for us, but this all feels like overkill if we just want to test that buyCoffee creates a charge equal to the price of a cup of coffee. Separate from the concern of testing, there’s another problem: it’s difficult to reuse buyCoffee. Suppose a customer, Alice, would like to order 12 cups of coffee. Ideally we could just reuse buyCoffee for this, perhaps calling it 12 times in a loop. But as it is currently implemented, that will involve contacting the payment system 12 times, authorizing 12 separate charges to Alice’s credit card! That adds more processing fees and isn’t good for Alice or the coffee shop.
What can we do about this? As the figure at the top of page 6 illustrates, we could write a whole new function, buyCoffees, with special logic for batching up the charges. Here, that might not be such a big deal, since the logic of buyCoffee is so simple, but in other cases the logic we need to duplicate may be nontrivial, and we should mourn the loss of code reuse and composition!
Как это в фунцкиональном стиле решается там описано, но еще столько же текста мне показалось будет слишком много для комментария. Красная книга Scala, поищите, это первая глава :)
Я тоже за систему правил (может просто плоский набор) из которых выбирается самое или просто подходящее. И уже правило модифицирует hp и xp.
Или нам нужна функция attack(player, monster, battlefield, engagementRules, gameConfig) -> (newPlayer, newMonster, newBattlefield). И тут выясняется, что engagementRules, gameConfig и прочие параметры окружения приходится тянуть в добрый десяток функций, поэтому вначале напрашиватся решение "выделить это всё в объект context", а следом "а почему бы нам не передавать этот контекст неявно?" — и у нас появляется this и ООП.
Не всё так плохо в ФП. engagementRules и gameConfig выносятся первыми параметрами, после чего каррированная функция частично применяется и вот у нас уже есть нормальная функция (player, monster, battlefield) -> (newPlayer, newMonster, newBattlefield).
Вот с ростом изменяемых объектов всё хуже. По мере усложнения логики приходится выделять элементарные операции в отдельные функции, после чего вроде бы всё становится нормально, но код начинает удивительно напоминать ООПшный :-)
Ну я не говорю, что это "плохо" или "хорошо", просто заметка о том, как определённая проблема программирования толкает людей к ООП, особенно если они не в курсе про частичное применение. Фактически, вызов конструктора в ООП — это и есть пре-каррирование всех нестатических методов этого класса, т.е.:
new Combat(engagementRules, gameConfig).attack(player, monster);почти эквивалентно
attack(engagementRules, gameConfig)(player, monster)только в ФП каррирование придётся сделать для каждой такой функции отдельно.
Что значит «придётся делать»?
Я имел в виду, что если у нас есть модуль с десятком близкородственных функций — protec(), attac(), trac(), barrac(), connec(),… — и у каждой есть зависимость от (gameConfig, player, ...), и мы хотим их все каррировать до action(player, ...) чтобы не таскать gameConfig по всему коду, то нужно проделать каррирование с каждой функцией в отдельности, и, чтобы не повторять это, сохранить их в какой-то структуре, что уже напоминает класс.
Если же эти функции — члены класса, то мы проталкиваем зависимости один раз в конструкторе, после чего они доступны каждой функции через this.
Оно там бесплатно. А в ООП — нет.
Не вижу большой разницы. В любом случае всё сводится к некоторому "замыканию", только в ООП оно делается через конструктор и сразу для пачки функций, а в ФП — через лямбду и для каждой функции в отдельности. Ну разве что в ООП чуть больше церемоний с объявлением и с наследованием этих "замыканий", плюс приходится в коде различать this- и local-параметры, плюс часто не поддерживается повторное каррирование на методе (т.е. у метода нельзя связать player и оставить monster свободным) — теряется гибкость, да.
Поэтому вам приходится думать, как прокидывать gameConfig аж до Combat, а мне — нет.
В ФП точно так же придётся продумывать, как протащить gameConfig от корня программы до каждого вызова зависимой от неё функции (или делать gameConfig глобальной переменной). В ООП это нужно делать только до вызова конструктора.
Привязывать функции к классу только ради энвайронмента — очень сомнительная идея, как по мне. Вы теперь все функции, которым нужен один и тот же энвайронмент, будете засовывать в один класс? Или создавать по классу на функцию? А когда какой-то функции понадобится энвайронмент A и энвайронмент B одновременно? А когда ей потребуется вызвать функцию, которой нужен только энвайронмент A, и которая уже написана?
Тут все очень просто — в 99% случаев, если нам нужна ф-я с энвайронметом Х, то она прекрасно логически ложится в соответствующий класс, предоставляющий этот энвайромент. Ну а для 1% оставшихся случаев есть паттерно-костыли.
Не придётся, см. выше.
Ну ридер для прокидывания энвайромента — это на самом деле закат солнца руками. Фактически, this делает в точности тоже, но автоматически. А когда компилятор делает что-то за меня автоматически — это всегда хорошо.
И получается god object, ок.
Это если вы весь энвайромент свалите в одну кучу.
Чем написание констрейнта на MonadReader или прямое заворачивание в ReaderT более ручное, чем создание класса и перенос функции в этот класс?
Ф-ю никуда переносить не надо — вы просто внутри имющегося класса пишите ее и все. Как внутри модуля в ФП. И используете как обычную ф-ю. Без монад, трансформеров и прочего бойлерплейта — все эти вещи за вас генерит ООП-рантайм языка.
Компилятор куда скорее за меня выведет нужные инстансы и констрейнты, чем сделает класс.
Так класс уже есть. Вы же сперва типы данных описываете, а потом пишите ф-ю, которая работает на этих типах. Вот когда типы данных описаны — значит, классы с энвайроментом уже есть. В ООП ф-и подчинены типам данных, не наоборот.
Глобально ООП ничего не упростит, а иногда даже наоборот, ибо закон Деметры беспощаден.
Вот неплохой пример, который показывает, как жить с такими параметрами. Как видно, никакого ужаса-ужаса как вы описали не происходит. Частичное применение наше все.
Любопытно, что в этом случае в scala полезно применить implicit аргументы.
Примерно так:
case class Player(power:Int, energy: Int)
case class Monster(hp:Int)
case class Environment(terrainType:Int)
def attack(player: Player, monster: Monster)
(implicit env: Environment): (Player, Monster) = {
val newPlayerState = player.copy(energy = player.energy - env.terrainType)
val newMonsterState = monster.copy(hp = monster.hp-player.power*env.terrainType)
(newPlayerState, newMonsterState)
}
val p = Player(1,3)
val m = Monster(20)
implicit val env = Environment(2)
val (p2, m2) = attack(p, m)
println(p2)
println(m2)и собирать engagementRules, gameConfig и прочие параметры окружения в Context не нужно
Которую мы положим в файл с каким именем?
Зависит от мощности сервера, пропускной способности сетки, мощности и кол-ва рабочих станций. Оба решения имеют свои области применимости. Оба решения плохие, т.к. имеют свои узкие места, которые обязательно вылезут в процессе эксплуатации. Что характерно, достоинства обоих решений, являющиеся продолжением их недостатков, будут восприниматься пользователями как само собой разумеющееся, отдельного упоминания недостойное.
когда class Player ударяет при помощи метода hits() class Monster, где на самом деле нужно изменять данные?
Как мне кажется, здесь должен быть введён ещё один объект а-ля
GameCore, который будет обрабатывать все эти ивенты и прочее. Тогда и структура остаётся ближе к реальной — есть монстр, пушка и игрок, но они лишь объекты, а взаимоотношения между ними задаются правилами игры. И тогда Player.hit должен передаваться просто как ивент к GameCore.handleHit(sender, object), который проверит у sender'а weapon, раскидает ему экспы и object'у хп. Вообще по-хорошему нужно ввести ещё и Playfield, и работать с ивентами в абстрактных координатах, тогда будет проще добавлять мультиплеер например :-)Ну и один класс обрабатывающий все-все ивенты это явно не дело. Он же будет разрастаться с каждой новой фичей.
А в остальном да, ивентами можно очень красиво разделить логику и уменьшать связность системы
А F*ingRealWorld это сообщение обработает: направит объекту Monster, тот ответит сообщением ImSuccessfullyBlockedTheHitNoDamageCaused.
И объект Player получит от F*ingRealWorld ответное сообщение: MonsterUntouchedOblomisLoh…
ООП такое ООП…
F*ingRealWorld
Мне аж интересно, первое слово здесь — это прилагательное или (дее)причастие...
объект-синглтон F*ingRealWorldОбъект-медиатор (есть такой «дизайн-паттерн»), он же объект-менеджер (реализация паттерна «стратегия»), он же потенциальный «God Object» (есть такой антипаттерн).
— коэффициент урона (огненный урон в кислородном мире более эффективен)
— коэффициент опыта (зависит от количества игроков)
— контроль времени (игровая сессия завершилась раньше удара)
и кучу всего остального. Я понимаю, вы имеете ввиду, что в определенный момент разработчику может стать скучно продумывать всю механику и он накостыляет скриптов. Только это никакого отношения не имеет к ООП, гуанокодинг парадигмы не имеет, только плохих разработчиков.
1) Инкапсуляция (в данном случае речь идет об инкапсуляции методов, инкапсуляция полей в «системных» и не только языках будет всегда так как это обусловлено архитектурой современных компьютеров).
2) Наследование / Полиморфизм (строго говоря наследование и полиморфизм тоже можно использовать по отдельности, но смысла в этом очень мало)
К инкапсуляции действительно есть претензии (прежде всего в плане модульности). К наследованию и полиморфизму я так понимаю у автора вопросов нет. Поэтому заголовок конечно странный, без наследования и полиформизма построить сложную и гибкую систему очень тяжело (во всяком случае за адекватные деньги / время), а отказываться от обоих концепций сразу это с водой выплескивать ребенка.
Вы обратите внимание, что он предлагает акторы. В них инкапсуляция ещё сильнее чем в стандартном ооп. Без сообщения там один актор с другим обменяться данными не может. Есть конечно подозрение, что этот "художник" акторам даёт доступ к одной бд… Но там тогда тот ещё форшмак...
Инкапсуляция (в данном случае речь идет об инкапсуляции методов, инкапсуляция полей в «системных» и не только языках будет всегда так как это обусловлено архитектурой современных компьютеров).
Инкапсуляция это объединение данных и логики работающей с этими данными, что такое в вашем понятии «инкапсуляция методов»?
(строго говоря наследование и полиморфизм тоже можно использовать по отдельности, но смысла в этом очень мало)
Полиморфизм прекрасно обходится без наследования. Более того, реализовывать полиморфизм без наследования считается предпочтительнее чем с ним.
ообще говоря, ООП состоит из двух концепций, в общем случае не связанных друг с другом:
А вы гляньте, интереса ради, кто этот термин ввел, и что этот человек в новую парадигму вкладывал, и заметите что никаких двух концепций в виде «инкапсуляция и наследование» там не было. Если что, он ещё жив, в интернете без проблем ищется нужная информация, а на ютубе без проблем можно найти его последние, совсем не давние, доклады.
Инкапсуляция это объединение данных и логики работающей с этими данными, что такое в вашем понятии «инкапсуляция методов»?
В моем понимании инкапсуляция более общее понятие — это вообще объединение функционала имеющего отношение к классу и размещение его внутри класса. Поля это или методы уже вторично. Собственно в определении инкапсуляции и кроется основная претензия к нему, потому как за объединение функционала вроде модули отвечают. А основная функция классов это все же наследование+полиморфизм.
Полиморфизм прекрасно обходится без наследования. Более того, реализовывать полиморфизм без наследования считается предпочтительнее чем с ним.
А по какому критерию (кроме как принадлежности классу) реализуется этот полиморфизм? Пример можно языка какого нибудь, где есть полиморфизм не по принадлежности классу? То есть понятно что полиморфизм можно и явными выражениями задавать, но я на практике такого не припомню.
А вы гляньте, интереса ради, кто этот термин ввел, и что этот человек в новую парадигму вкладывал, и заметите что никаких двух концепций в виде «инкапсуляция и наследование» там не было. Если что, он ещё жив, в интернете без проблем ищется нужная информация, а на ютубе без проблем можно найти его последние, совсем не давние, доклады.
Я рад за этого человека. Но есть много вещей, которые используются и воспринимаются не так как они были изначально созданы. А в той же википедии и куче книжек, да и просто логически пока так.
Я рад за этого человека. Но есть много вещей, которые используются и воспринимаются не так как они были изначально созданы. А в той же википедии и куче книжек, да и просто логически пока так.
А ещё в куче книжек, и в википедии, кстати, тоже, по другому.
Только вот инкапсуляция наследование и полиморфизм были и есть и в процедурных языках, например в том же Си.
А по какому критерию (кроме как принадлежности классу) реализуется этот полиморфизм?
1. Через интерфейсы
2. Все варианты реализации параметрического и ad-hoc полиморфизма
А ещё в куче книжек, и в википедии, кстати, тоже, по другому.
В википедии вроде так:
Основные принципы структурирования в случае ООП связаны с различными аспектами базового понимания предметной задачи, которое требуется для оптимального управления соответствующей моделью:
абстрагирование для выделения в моделируемом предмете важного для решения конкретной задачи по предмету, в конечном счёте — контекстное понимание предмета, формализуемое в виде класса;
инкапсуляция для быстрой и безопасной организации собственно иерархической управляемости: чтобы было достаточно простой команды «что делать», без одновременного уточнения как именно делать, так как это уже другой уровень управления;
наследование для быстрой и безопасной организации родственных понятий: чтобы было достаточно на каждом иерархическом шаге учитывать только изменения, не дублируя всё остальное, учтённое на предыдущих шагах;
полиморфизм для определения точки, в которой единое управление лучше распараллелить или наоборот — собрать воедино.
Абстрагирование это что-то супер абстрактное, оно во всех парадигмах есть. Так что остается только три, которые я и перечислил.
Через интерфейсы
Интерфейсы — это по факту те же классы, только в языках, в которых было лень / тяжело реализовывать множественное наследование. Особенно это эпично сейчас выглядит в Java, где разрешили в интерфейсах добавлять реализацию. Скоро field'ы еще туда добавят, будет еще смешнее, как они будут разницу между интерфейсами и классами объяснять.
Все варианты реализации параметрического и ad-hoc полиморфизма
Вы сейчас теплое с мягким мешаете. Понятно что в ООП и выше речь шла про subtype полиморфизм. Ad-hoc и параметрический полиморфизм — это вообще особенности resolve'инга, то есть синтаксический сахар (про них к примеру большинство языков в run-time забывают, если не считать reflection'а), для удобства именования функций и более правильного вывода типа (иначе скажем функции пришлось называть бы sumInteger, sumString и т.п.)
Скоро field'ы еще туда добавят, будет еще смешнее, как они будут разницу между интерфейсами и классами объяснятьСмысл как раз в том, чтобы данные не добавлять. Только стандартное поведение по умолчанию, включающее в себя другое поведение, которое требуется воплотить в конкретных реализациях («паттерн Template Method»).
В википедии вроде так:
А ещё в википедии так:
ООП имеет уже более чем сорокалетнюю историю, но, несмотря на это, до сих пор не существует чёткого общепринятого определения данной технологии[14]. Основные принципы, заложенные в первые объектные языки и системы, подверглись существенному изменению (или искажению) и дополнению при многочисленных реализациях последующего времени. Кроме того, примерно с середины 1980-х годов термин «объектно-ориентированный» стал модным, в результате с ним произошло то же самое, что несколько раньше с термином «структурный» (ставшим модным после распространения технологии структурного программирования) — его стали искусственно «прикреплять» к любым новым разработкам, чтобы обеспечить им привлекательность. Бьёрн Страуструп в 1988 году писал, что обоснование «объектной ориентированности» чего-либо, в большинстве случаев, сводится к некорректному силлогизму: «X — это хорошо. Объектная ориентированность — это хорошо. Следовательно, X является объектно-ориентированным».
Пример: когда class Player ударяет при помощи метода hits() class Monster, где на самом деле нужно изменять данные? Величина hp объекта Monster должна уменьшиться на attackPower объекта Player; величина xp объекта Player должна увеличиться на уровень Monster в случае убийства Monster. Должно ли это происходить в Player.hits(Monster m) или в Monster.isHitBy(Player p)? Что если здесь нужно учитывать и class Weapon? Мы передаём аргумент в isHitBy или у Player есть геттер currentWeapon()?В таких случаях пишется ECS. Автор статьи точно имеет достаточные компетенции, чтобы его переводить и читать?
Вероятно, вы используете лишь элементы функционального подхода. Так-то в ФП придумано много чего помимо передачи функций в качестве параметров и замыканий, и хотя формально ничего из этих придумок ООП не противоречит, реально мне не известны языки программирования где это всё можно использовать одновременно.
А что касается языков, то практически у большинства современных языков есть как наследование, так и лямбды, замыкания и т.п. Да immutability из коробки лично мне очень сильно не хватает, точнее даже не самой immutability, а инфраструктуры над ней, автоматическое кэширование (где виртуальная машина будет сама решать что и когда кэшировать), поиск twin объектов (то есть одинаковых объектов и замена одних другими), прозрачные отображения (то есть когда возвращается отображение некоторой коллекции, чтобы эта коллекция не сразу отображалась, а по мере необходимости, скажем со второго использования) и т.п. Но я таких языков где это реализовано навскидку не вспомню.
Даже древний Делфи инновационнееВ ООП, точнее в его совмещении с принципом статической типизации, основной, на мой взгляд, вопрос — в множественном наследовании если не классов, то хотя бы типов: чтобы объект мог принадлежать к двум разным типам, ни один из которых не является потомком другого. Концепция «интерфейсов» этот вопрос блестяще решает. Как там у Дельфи с этим вопросом?
Даже древний Делфи инновационнее был чем все современные котлины-мотлины/скалы-шмалы вместе взятые — его делали для людей
Простите, но что в древнем Делфи было такого инновационного, если сравнивать с современными языками?
Не понимаю почему нельзя использовать и то и другое — что мешает?
p.s. я сам такой. Но в такие моменты включаю критическое мышление, профилировщик, и думаю в первую очередь о целях, а не о том как бы это всё наворотить посовременнее и напихнуть как можно больше технологий ради технологий, что будет медленнее в рантайм.
Там наоборот много костылей до сих пор тянется, как раз из за этой самой совместимости, отсутствие которой сделало бы язык гораздо логичнее и удобнее.
А если вы реально «переживаете править две строки» — то что-то явно не так в вашем проектеВ нашем проекте всё так. Но SPEC 2000 — это тест скорости. Эталон. Он не должен менять вообще, никак.
И те две строки, что пришлось менять — это то место, где разработчики нарушили спеки, описанные в документации. Но всё равно — изменение этих мест значит, что мы уже не можем на 100% доверять тем числам, что получали ранее. Так как теперь мы имеем уже другую программу.
А вы хотите заставить нас что-то менять при выходе каждой минорной версии. Качмар.
Отсюда забивание на обратную совместимость (python, php), ради эфимерной «красоты языка» (психам же насрать на совместимость, главное внутренняя красота и современные технологии).
Довольно спорное утверждение. C++ хорош с его обратной совместимостью?
Например на игры, графический интерфейс, ООП ложится хорошо, в других областях ИМХО, гораздо хуже.
А вот еще и не плохая статья как готовить ООП: OOP is dead, long live OOP
Да, еще эти фабрики фабрик фабрик фабрик.
Проблема, на мой взгляд, в том что реализация ООП в конкретном языке всегда формальна. Из этого вытекает простой факт, что в какой то момент мощности языка перестает хватать для того чтобы модель соответствовала реальности. В DDD сделали "хитрость" — там нигде не сказано, что концепции/сущности должны напрямую соответствовать объектам. Напрямую говориться, что есть объекты служебные типа например ConnectionPool, которые к предметной области отношения не имеют. И так как в конечном итоге DDD это не формальная модель, то там и проблем с этим нет. Ну оно и понятно — если бы модель DDD напрямую соответствовала тому что в коде, так и программист был бы не нужен. Хватило бы и аналитика, который умеет в DDD.
Изначально же ООП так и задумывался, разве нет? Потом оказалось что мало кто умеет нормально моделировать реальный мир и все ищут готовые паттерны, чтобы под копирку кучу фабрик фабрик наделать где надо и где не надо. Тогда стали популярны паттерны.
Нет, не задумывался он так.
Алан Кей про историю создания ООП
Шизофреническая инкапсуляция объектов

Кто мне пояснит, чем функция, которая вызывает функцию, которая вызывает функцию, которая вызывает функцию, которая вызывает функцию… принципиально отличается от глубокой инкапсуляции?
Не троллю, серьёзно спрашиваю!
Инкапсуляция требует связи данных с логикой, поэтому в случаях, когда взаимодействуют сразу несколько объектов логика может быть ГОРАЗДО более раздробленной, а структура программы гораздо более сложной.
Структура данных != Класс. Работа через структуры != моделирование объектного мира. Использование сеттеров, геттеров, опционалов замыканий генериков — еще больше отодвигает от настоящего ООП, который задумывался в бородатые годы, усугубляет текущие проблемы, делает код сложнее и запутаннее. Достаточно посмотреть на метрики и быстродействие софта.
Боюсь, что практика «категорически не использовать goto» есть только в структурном программировании, основным идеологом коей является Вирт и его последователи.
Остальные люди высказываются более осторожно: говорят, что без понимания «для чего» этот оператор использовать не стоит.
А в остальном, это вполне нормальный оператор, который иногда помогает упростить код или добавить микрооптимизаций.
З.Ы. за всю мою карьеру, мне этот оператор понадобился лишь 3 раза.
Кроме того, Вы и исключения/перехватываемые паники осуждаете?
Есть конечно checked эксепшены в Java, но кажется народ уже понял насколько это ужасно с ними работать ) но попытка хорошая
Даже перехват паник (те хе исключения, вид сбоку) необходим в определенных ситуациях и присутствует и в Go, и в Rust.
А вот неразумное, повсеместное, ничем не ограниченное и синтаксически «удобное» злоупотребление исключениями — беда, хот checked, хоть unchecked.
То есть данные все равно хранятся в РСУБД, так как ничего лучше для таких задач на текущий момент не придумано, но работают с базой крайне извращенным способом. В результате дикие тормоза и проблемы.
Но привязывать объекты к функциями действительно не очень. Так же тайпклассы ту же проблему решают гораздо лучше
А при чём тут тайпклассы?
Одна из очень плохих проблем ООП — иерархии. Если вы налажали с иерархией объектов поменять её на какую-то другую очень сложно. Все время спотыкаюсь в этом в тех же шарпах, где основной используемый интерфейс ICollection реализует кучу мусорных методдов типа CopyToArray, IsReadOnly, IsResizable и так далее. И выкинуть это уже нельзя, потому что обратная совместимость.
Были бы тайпклассы, можно было бы для всех стандартных классов сделать параллельную адекватную иерархию, а эту задеприкейтить. Но, увы, в оопэ так нельзя.
Ну вот, собственно тайпклассы это и возможность создать несколько иерархий. В мейнстрим языках их щас собственно пропихивают с помощью шейпов и концептов.
Ну вот, собственно тайпклассы это и возможность создать несколько иерархий.
Только у тайпклассов нет иерархии.
Это нельзя назвать иерархией?
Это можно назвать иерархией. Но только в таком случае у слова "иерархия" будет не то значение, как у слова "иерархия" применительно к ООП.
В случае ООП, если что-то MonadPlus — оно автоматически становится Monad. В случае тайпклассов — если что-то не Monad, то оно не может стать MonadPlus.
Но это одно же и то же.
В чем одно и то же? Это принципиально разные вещи, которые совершенно по-разному работают. В хаскеле что-то, являющееся MonadPlus, не станет Monad, вы просто не сможете MonadPlus написать. То есть "иерархия" тайпклакссов обращена в противоположную сторону.
А ООП вы не сможете объявить свой класс как реализующий MonadPlus пока не напишете все методы требуемые интерфейсом Monad.
Итоговая разница — в одно объявление.
требуемые интерфейсом Monad
При чем тут интерфейс, мы же про иерархии? Интерфейсы не наследуются, с-но и в иерархию не входят по определению, это контракты, как и тайпклассы. Мы же про множества значений — то есть про классы (реализации интерфейсов) и инстансы (реализации тайпклассов). Чтобы сделать Foo < Bar вам достаточно сказать: class Foo extends Bar {};
В случае хаскеля вам надо сперва сделать инстанс Bar для типа и только потом можно будет для него объявить инстанс Foo. Более того, вы можете сделать инстанс Foo для любого Bar и тогда с точки зрения ООП Foo < Bar, а с точки зрения хаскеля Bar < Foo.
Тайпкласс в ФП соответствует интерфейсу в ООП.
Тайпкласс в ФП соответствует интерфейсу в ООП.
Я же это и сказал: "Интерфейсы не наследуются, с-но и в иерархию не входят по определению, это контракты, как и тайпклассы".
Мы говорим не об интерфейсах и тайпклассах (они не входят ни в какие иерархии), а о классах и инстансах тайпклассов (реализациях интерфейсов). Они как раз иерархию и образуют.
А давно в ООП интерфейсы завезли? :)
А в каком месте ООП диктует какие должны быть иерархии объектов, и кто мешает используя ООП не реализовать в интерфейсе кучу «мусорных», как вы говорите, методов?
Ну вот у вас есть B который наследуется от A. А через год вы поняли, что плохо, что он так наследуется, но сделать ничего нельзя, потому что у вас миллионы клиентов, и обратную совместимость надо оставлять. Что делать в такой ситуации? Вариант "надо было думать раньше" только не надо предлагать, это не решение.
Ну вот у вас есть B который наследуется от A. А через год вы поняли, что плохо, что он так наследуется, но сделать ничего нельзя
А с тайпклассами-то в чем разница? Типа была у нас реализация тайпкласса для типа Х, а потом поняли, что это плохо, не должно быть ее. И что, как удалить-то, не нарушая обратную совместимость?
С тайплкассами делаем тайпкласс АА и тайпкласс ВВ. Реализуем их как надо. На А и В вешаем "деприкейтед", и говорим использовать только АА и ВВ. Профит.
Не понял. У нас была проблема — есть реализация тайпкласса, которую надо удалить. Как ее удалить, не нарушая обратную совместимость?
А описанное выше можно и с классами сделать — делаем класс АА и класс BB, A и B депрекейтим, и говорим использовать только AA и BB. С-но, на практике так и делают.
Удалять не надо, надо сделать параллельную иерархию. Ну вот например, я знаю, как надо спроектировать правильно эти коллекции. С тайпклассами я сделаю своих тайпклассов и реализую для стандартной библиотеки, и все будет работать. В случае ООП мне нужно влезть в исходники этих самых List/Array/..., чего я сделать конечно же не могу.
По вашему, это свойство ООП как такового, или скорее популярных языков? В каком-нибудь self или vba нет вообще никаких классов. Может быть можно придумать (или уже придумали) язык, который
- Является OO
- Поддерживает параллельную независимую классификацию тех же объектов.
В случае ООП мне нужно влезть в исходники этих самых List/Array/...
Зачем? Просто делаешь параллельную иерархию и ее используешь, как в хаскеле. Проблема-то в какой момент возникает?
Вы про то что нельзя добавить к типу реализацию дополнительного интерфейса? Ну это не свойство ООП, это свойство конкретных реализаций.
ООП в вакууме не особо интересно. То что можно сделать язык, где так будет — это одно. Но пока их нет — их нет. И можно рассматривать это как свойство ООП, как свойственное всем объектам этого класса, пусть и не присущее им идеологически.
Ну в тс можно через prototype-костыль. В шарпе "почти" можно (если бы можно было группировать extension методы в интерфейсы)
Уточнение: с версии 1.8
И основное тут не prototype-костыль (это как раз фича javascript, которая там была изначально), а declare module
Энтерпрайз на ТС не пишут. На ТС пишут обычно представление, это вообще не в ту степь.
Extension методы это просто немного сахара, толку с них никакого, ибо на них нельзя обобщаться.
Что-то похожее предлагают в пропозале, и само его существование намекает на то, что я прав.
Энтерпрайз на ТС не пишут. На ТС пишут обычно представление, это вообще не в ту степь.
Какая разница, кто что на чем пишет или нет? Вот язык с ООП, где можно. И не какая-то эзотерика, а вполне себе мейнстрим.
Что-то похожее предлагают в пропозале, и само его существование намекает на то, что я прав.
Как раз наоборот, пропозал намекает на то, что невозможность описанного расширения существующего класса ортогональна ООП.
Так что надо говорить не о том что "в ооп так нельзя", а о том что "в джаве так нельзя" или "в шарпе так пока нельзя" и т.д..
Какая разница, кто что на чем пишет или нет? Вот язык с ООП, где можно. И не какая-то эзотерика, а вполне себе мейнстрим.
Потому что это не сложная бизнес-логика, а просто валидация ввода в большинстве случаев. Когда я писал десктопное приложение на шарпах, там точно так же на 10к строк логик было 30к строк валидации.
Для валидации и бизнес-правил несколько различаются требования к расширяемости и пр.
Как раз наоборот, пропозал намекает на то, что невозможность описанного расширения существующего класса ортогональна ООП.
ООП == как в мейнстрим языках. Если проблемы нет в каком-нибудь смоллтоке это никак не влияет на поинт того, чего в ООП сделать нельзя. Вот когда в джаве появится, тогда и значит что можно. Если в джаве нет, значит нельзя.
Потому что это не сложная бизнес-логика, а просто валидация ввода в большинстве случаев.
Не понял при чем тут это. Хочешь — пиши бизнес-логику на тс, тебе не мешает никто.
ООП == как в мейнстрим языках.
тс в 2019 — вполне мейнстрим язык.
Вот когда в джаве появится, тогда и значит что можно. Если в джаве нет, значит нельзя.
Ну так и говори, что "в джаве нельзя", при чем тут все ООП.
С появлением default methods не будет никаких проблем поправить иерархию и в .net.
Как вы поправите? Вот нужно из ICollection выпилить IsResizable или перестать наследовать массив от IList. Как это сделать?
Точно так же как и с тайпклассами:
для всех стандартных классов сделать параллельную адекватную иерархию, а эту задеприкейтить
Вы не можете так в ООП, потому что вы буквально пиште в ООП class B: IFoo, IBar, A.
И что? Это как-то мешает добавить в этот список ещё один интерфейс? Или задеприкейтить класс B и написать новый?
Потому что исходник класса стандартной (или любой другой) библиотеки вы менять не можете.
люди прочитают определение термина «ООП» и поймут, что это не про понты с абстракциями, а про объединение данных и методов их обработки
Алан Кей такого не говорил. Если вы считаете что есть какое-то однозначно верное определение, так поведайте его уже миру, наконец, и распишите конкретно в чем был не прав Алан.
p.s.
Но что такое ОО?© Чистая Архитектура
Один из возможных ответов на этот вопрос: «комбинация данных и функций». Однако, несмотря на частое цитирование, этот ответ нельзя признать
точным, потому что он предполагает, что o.f() — это нечто отличное от f(o).
Это абсурд. Программисты передавали структуры в функции задолго до
1966 года, когда Даль и Нюгор перенесли кадр стека функции в динамическую память и изобрели ОО.
Не первый раз замечаю, что на западе, а теперь и у нас, любят писать статьи с категоричными и броскими заголовками. Наверное, это тренд такой, статья более популярной и хайповой получается.
Вопрос — автор знаком со SmallTalk?
«Давайте вернемся в конец 90-х и попробуем без ООП написать все те программы и системы, которые существуют и развиваются до сих пор»
А так то да, очень удобно, с позиции уже существующих экосистем и решений, начать призывать отказаться от ООП, как от какой-то ереси.
Осталось только переучить ту гору разработчиков на «правильный стиль» )
Вобщем кликбейт и пук в лужу.
А так то да, очень удобно, с позиции уже существующих экосистем и решений, начать призывать отказаться от ООП, как от какой-то ереси.
Если оторваться от сопров про ООП, не вижу причин с течением времени отказываться от устаревших технологий и решений в пользу более современных/продвинутых/более подходящих под новые задачи.
Когда в руках молоток, все вокруг кажется гвоздями, да?
Вобщем, мне не подошел ООП, поэтому БЫСТРА переставайте его использовать )
По моему опыту, самая серьёзная проблема ООП заключается в том, что оно мотивирует игнорировать архитектуру модели данных и применять бестолковый паттерн сохранения всего в объекты, обещающие некие расплывчатые преимущества.
То есть мотивирует игнорировать архитектуру данных?
Наоборот — объект это и есть архитектура данных. Просто в тот же самый объект помещаются и методы работы с данными.
Именно поэтому и нужно хорошо разбираться в архитектуре приложения и какими данными оно манипулировать, чтобы правильно нарезать приложение на объекты. От непонимания этого и получается кривая ООП реализация, чем грешат начинающие и нежелающие разобраться в принципах.
То же слепое следование паттернам приводит к той же ошибке.
Ну вот зачем мне ссылка в виде ID, если можно в виде типизированной переменной? Только чтобы отложить обнаружение ошибки со времени компиляции на время исполнения. Это же так круто, слышать вопли пользователя — ааа, у меня ClassCastException!
посмотрите это видео:
youtu.be/Tb823aqgX_0
Однако же, вот этот пример интересен:
Пример: когда class Player ударяет при помощи метода hits() class Monster, где на самом деле нужно изменять данные? Величина hp объекта Monster должна уменьшиться на attackPower объекта Player; величина xp объекта Player должна увеличиться на уровень Monster в случае убийства Monster. Должно ли это происходить в Player.hits(Monster m) или в Monster.isHitBy(Player p)? Что если здесь нужно учитывать и class Weapon? Мы передаём аргумент в isHitBy или у Player есть геттер currentWeapon()?
Тут явно надо больше классов :) Как минимум сама операция атаки должна описываться отдельным классом. А ведь есть ещё и экипировка, и различные стратегии взаимодействия, в зависимости от экипировки.
Я к тому, что если всё более-менее адекватно спроектировать, применяя, допустим, DDD, то это не так уж и страшно. Хотел бы я посмотреть на подобную модель, которая будет реализована с другими подходами. В частности на её поддержку и расширение.
Параграф «Какой же подход использовать вместо ООП?» очень понравился, но занимает относительно малую часть статьи, а список «дополнительное чтение» еще больше удивляет.
P.S. Я знаю что это перевод, просто надеюсь что комент оттолкнет кого нибудь от написания hate-driven статей
Опуская менее важное:
-Player : Actor -
Player::Fire() {
_weapon->Fire(this);
}
Weapon::Fire(Actor aOwner) {
HitInfo* hit;
if(Physics::Raycast(aOwner.transfrom.position, aOwner.transfrom.forward, _fireDist, Globals::c_affectableLayer, hit)) {
IAffectable* affectable = hit->hitCollider->GetComponent(IAffectable);
if(affectable) {
affectable->takeEffect(_damageEffect, aOwner);
}
}
}
- Monster : Actor -
Monster::takeEffect(IEffect* aEffect, Actor aEffectOwner) {
ActorValue targetValue = _values[aEffect->targetValue];
aEffect->OnApply(aEffectOwner, this, targetValue);
targetValue ->Apply(aEffect);
}
ActorValue::Apply(IEffect* aEffect) {
// и тут уже пошла логика применения изменения используя дескриптор эффекта.
// в простейшем случае:
_value += aEffect->getDelta();
}
let player = {
attackPower: 5,
xp: 0
};
let monster = {
hp: 50,
level: 10
};
function isMonsterAlive(monster)
{
return monster.hp > 0;
}
function playerHitsMonster(player, monster)
{
monster.hp -= player.attackPower;
if (!isMonsterAlive(monster))
player.xp += monster.level;
}
Минимально необходимое количество структурированных данных и функций для решения поставленной задачи. Минимальная стоимость реализации и поддержки ведёт к максимальной прибыли от внедрения решения в бизнес-процесс (в случае, если гипотеза геймдизайнера оказалась верна и этот функционал стал приносить прибыль). А что дадут в денежном эквиваленте все эти Actor, ActorValue, HitInfo, Globals, Physics, IAffectable, IEffect? Лишнее время на проектирование, написание и отладку, лишние сущности и связи между ними, больше рисков словить баги.
Прелести ООП в примитивных задачах понять нельзя.
Вобщем, Ваш код больше похож на хаки джуна, это своеобразная мимикрия под продакшн-код в геймдеве. Я такого добра много видел на проектах второкурсников — они его по выходным по ночам до 4 утра отлаживали перед выставками, а потом оно всё равно тормозило, глючило и падало.
Нагородить абы каких абстракций — это не помогает. А с возрастом и опытом понимаешь — даже если нагородить «правильных» абстракций — это тоже не помогает. В итоге Time To Market рулит процессом и определяет стиль программирования.
Мой код не имеет внешних зависимостей. Его можно уже брать и использовать. А Ваш код имеет кучу внешних зависимостей, которые нельзя описать без дополнительной информации от заказчика. Мой Time To Market — 10 минут. Ваш — если всё-таки возьмётесь довести свой код до работоспособного состояния — пара дней. Эффект для пользователя один и тот же.
Теперь считаем: 1 час разработчика стоит $100. За готовую демку платят $1000.
Я заработал $980.
Вы в убытке на $600.
Вот Вам и примитивные задачи)
Почему физика — это namespace, а не объектЭто класс со статическими методами.
Что это за такой GlobalsГлобальные константы. в данном случае хранит битовую маску слоев с IAffectable объектами.
Где идёт разделение игровой логики, физической модели, геометрической модели и рендеринга?Это игровая логика, использующая физику. За рендеринг обычно отвечает конвейер визуализации — это другая степь.
Коллайдер — это геометрия, а не физикаВ гейм-деве часто коллайдеры используются как часть физической модели (примитивы — для упрощения расчетов).
Физика опять же бывает разная: кинематика, динамика, инверсная кинематика.Физика использовалась только для определения столкновений динамических объектов — Актора и пули(которая для упрощения примера двигалась моментально, да и ее класс мы опустили).
Инверсная кинематика (IK) обычно используется в гейм-деве для анимаций конечностей (ходьба по ступенькам, толкание дверей и т.п.), а не для расчетов физики.
даже если нагородить «правильных» абстракций — это тоже не помогаетВ этом и суть ООП — правильные абстракции уменьшают количество повторяющегося кода, логических ошибок и упрощают расширение приложения. В простых приложениях это конечно «стрельба из пушки по пернатым», но даже средняя по сложности игра — это уже далеко не простое приложение — без ООП тут можно попасть в Бедлам.
Мой Time To Market — 10 минут. Ваш — если всё-таки возьмётесь довести свой код до работоспособного состояния — пара дней. Эффект для пользователя один и тот же.Подскажите плиз где за такие демки как ваша платят по 1к? Она не рабочая. Она решает одну тривиальную задачу в вакууме. Как, впрочем, и мой набросок (хотя в нем хотя бы подразумевается какой-то намек на способ интересующего взаимодействия).
Теперь считаем: 1 час разработчика стоит $100. За готовую демку платят $1000.
суть ООП — правильные абстракции уменьшают количество ...
Ну так у Вас и не пахнет правильными абстракциями. ООП — как следует из названия — ориентирован на объекты. Это значит, что не должно быть статических методов и глобальных констант. Всё должно быть реализовано на объектах. А иначе уже идёт процедурное программирование в стиле C из 1970х. Но у Вас всё хуже — у Вас дикая смесь одного, другого и, скорее всего, чего-то третьего.
То, что принято использовать в низкобюджетном геймдеве, не является правильным ООП. Это просто какая-то традиция, вероисповедание, исторически сложившееся нелогичное нагромождение случайных шаблонов. Поэтому не стоит приводить это как пример использования ООП.
Она не рабочая. Она решает одну тривиальную задачу в вакууме.
Определитесь, пожалуйста, моя демка нерабочая или всё-таки решает задачу?)
Мой код запускается и работает прямо в консоли Вашего браузера. Да, у него нет 3Д и партиклов. Но в постановке задачи этого и не было. Соответственно я пошёл по кратчайшему пути и дошёл быстро. Я могу показывать свою демку заказчику описанной логики взаимодействия Игрока и Монстра уже сейчас.
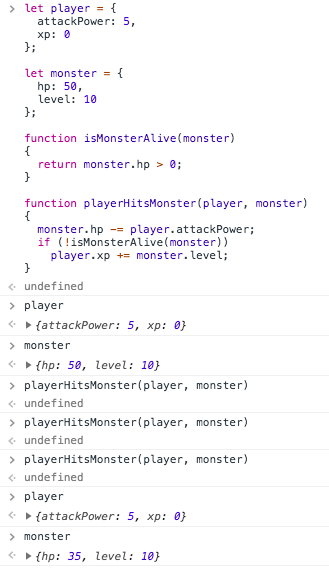
А Вы когда сможете?
Ваш код больше похож на хаки джуна, это своеобразная мимикрия под продакшн-код в геймдеве. Я такого добра много видел на проектах второкурсников.
А с возрастом и опытом понимаешь
Ну так у Вас и не пахнет правильными абстракциями
Но у Вас всё хуже — у Вас дикая смесь
То, что принято использовать в низкобюджетном геймдеве
нелогичное нагромождение случайных шаблоновЭто не конструктивно.
не должно быть статических методов и глобальных констант. Всё должно быть реализовано на объектах.Мои Globals да, попахивают, лучше эту константу хранить в спец. классе (да хоть в том же Физикс), но по сути это останется глобальной константой.
Без статических методов можно обойтись, но зачем? Это будет не оптимально — нужно выделять и освобождать память там, где это не нужно. Это просто методы, которые можно использовать без создания экземпляра класса. Почему статические методы противоречат концепции ООП?
Определитесь, пожалуйста, моя демка нерабочая или всё-таки решает задачу?)Она не рабочая как демка. С таким же успехом можно было написать просто log(50-5) — т.е. это хардкод для одного случая. Мы по-разному смотрим на задачу: я вижу проблему взаимодействия Monster-Player, Вы, на сколько я понял, проблему отнимания хп. Первая решается при помощи ООП (особенно если подразумевается такое взаимодействие между различными объектами, а не только уловными Monster и Player), для второй, безусловно, ООП оверкил.
А Вы когда сможете?Используя какой-то Unreal или Unity — к вечеру, но моя демка будет являться продуктом в который можно поиграть и, т.к. я потратил лишние 20 мин на проектирование структуры и еще 40 на имплементацию доп. слоев абстракций, можно будет в дальнейшем расширять, не переписывая все с 0.
Это не конструктивно.
Абсолютно согласен, что писать такой код как у Вас — это неконструктивно. BTW, по правилам русского языка «не» с краткими прилагательными пишется слитно, если их полная форма употребительна. В нашем случае существует употребляемое полное прилагательное «неконструктивный».
Без статических методов можно обойтись, но зачем?
Затем, чтобы показать пример ООП в обсуждении про ООП. Иначе у читателей возникнут сомнения в Вашей адекватности.
Почему статические методы противоречат концепции ООП?
Потому что это по сути те же глобальные переменные. Они нарушают принцип инкапсуляции. Глобальные константы также нарушают инкапсуляцию. Согласно ООП ничто извне не должно менять поведение объекта. А что Вы делаете?
const int Global::magicOOPNumber = 5;
...
function MyLovelyGamedevClass::Fire(IMonster *victim)
{
victim->takeItAsADamage(this->power * Global::magicOOPNumber);
}
Я могу только предположить, что на основании того, что вы используете C++, вы утверждаете, что ваш код — это ООП. Но, к сожалению, C++ — это не объектно-ориентированный язык. Это мешанина из всех известных человечеству концепций. Чисто теоретически на нём можно написать ООП код, но у вас, увы, это пока что не получается. Как и у всех, кого я знаю)
С таким же успехом можно было написать просто log(50-5)
Позвольте не согласиться. Успеха тут не получится, потому что это — не валидный JS-код.
console.log(50-5);Вот так будет работать, но в чём смысл? Это просто однократная арифметическая операция с магическими числами.
Важно, чтобы было понятно какова семантика входных и выходных данных. И потом уже эту семантику можно подключать к системам ввода/вывода. Также важно оформить типичные операции над данными в функции, которые можно вызывать повторно и использовать для разных сущностей в игре.
В моём коде тоже описывается взаимодействие между игровыми сущностями. Тут есть и hp, и xp, и сила удара, и уровень Монстра. Просто я оформил игровую сущность как структуру данных и не стал накручивать несуществующие в тексте статьи дополнительные требования (типа 3д, физики, affectableLayer'ов и прочего оверинжиниринга).
А Вы пытаетесь реализовать то же самое взаимодействие тех же самых сущностей через объекты. Но это не ООП, это не компилится, и у этого до сих пор нет скринов — а вечер уже близко.
что писать такой код как у Вас — это неконструктивно
у читателей возникнут сомнения в Вашей адекватности
можно написать ООП код, но у вас, увы, это пока что не получается. Как и у всех, кого я знаю
это не ООПСпасибо конечно за урок русского (не родной язык), но это все по прежнему нисколько не конструктивно и довольно высокомерно.
Согласно ООП ничто извне не должно менять поведение объекта. А что Вы делаете?На самом деле там нет изменения объекта через константу, там оптимизация рейкаста при помощи константы. Из этого я делаю 2 вывода:
1) да, для текущей задачи это и правда было излишеством — сори, писал с оптимизацией по привычке.
2) хороший код должен быть очевиден даже для джуна и т.к. Вы его не поняли, то код и правда не так хорош.
Но это не ООП, это не компилится, и у этого до сих пор нет скринов — а вечер уже близкоХм, а ведь и правда сказал. Ок, вот демка (как оказалось заняло это на Юнити около 40 мин):
а вот и код (интересующая часть практически не отличается от предоставленной изначально): https ://drive.google.com/open?id=1lw5Q7JRDzu3ET5OLs0ATA1Rw5s3iW5De
Я лично не буду писать никакой графики и интерактива — ничего этого в описании задачи в оригинальной статье не было. Я выбрал наиболее лаконичный способ реализовать описанное в статье взаимодействие сущностей и вполне себе доволен этим. Мой билд занял 15 минут жизни (вместе с презентацией), весит 301 байт и я могу его демонстрировать.
Ваш билд весит 36 863 414 байт, до сих пор не готов к демонстрации и уже занял как минимум 2 часа на изготовление и презентацию.
Да у вас у самого проект не 3ДЭто 3д-графика и 3-д мир, но да все события происходят в плоскости. Но я согласен и на 2-д игру взглянуть.
Спор о преимуществах ООП подхода и мой тезис был о том, что такой подход раскрывается лучше в более сложных задачах. Мне правда интересно посмотреть на толковую игровую логику использующую «не ООП» — был бы рад увидеть такой даже уже готовый игровой код. В случае, если Вы действительно хотите убедить кого-то в своей правоте (а не просто потешить свое самолюбие), это был бы конструктивный аргумент.
Вот игра в сторе, созданием которой я руководил: crystal slots. Серверная часть написана без ООП, на ней вся игровая и бизнес- логика крутится. DSL для настройки правил игры присутствует. Исходники, конечно, не покажу. Но можете их купить за N x $100k, если есть большое желание.
Attack(a,b:Unit);
И тогда нам неважно, кто кому наносит урон: игрок монстру, монстр игроку, питомцы из нового обновлния, PVP или же у монстроботов появилось несколько враждующих фракций (пока боты дерутся игрок может постоять в сторонке и потом добить выживших и собрать лут). Также упрощает создание монстров с инвентарем, дабы поднимали вещи и при смерти выкидывали и/или тушка была временным сундуком-инвентарем. Инвентарь дает еще возможность собирать броню (бронированный зомби). Ладно, инвентарь можно вынести в отдельную запись.
Мало того, можно все данные заключить в Record (записи). А далее использовать классы-хелперы (если выбранный ЯП позволяет), которые дают возможность вызова методов у обычных переменных (вызываются методы класса-хелпера).
Проблема ООП — неограниченный полет фантазии. И потом попробуй разбери, как оно работает и работает ли вообще.
Мало того, можно все данные заключить в Record (записи). А далее использовать классы-хелперы (если выбранный ЯП позволяет), которые дают возможность вызова методов у обычных переменных (вызываются методы класса-хелпера).
Мне кажется, это называется процедурным программированием.
a = (0xFF55.toStr).addBold; // преобразование в строку константы, добавление html-тега;На втором месте по удобству — функции, типа
a = HtmlBold(IntToStr(0xFF55)); // выполнение функций идет от вложенных справа до внешних слева, т.е. обратный от порядка чтения слева направо;И самое неудобное — чисто процедурами, иногда могут потребоваться доп.переменные:
IntToStr(0xFF55, a); // аргументы inVar, outVar;
HtmlBold(a,a); // иногда вход и выход совмещаются;Идеально — грамотно сочетать процедурный и ООП стиль. Не понимаю, когда обычную процедуру оборачивают в класс ради создания класса при условии отсутствия каких-либо переменных. Особенно про всякие преобразования. Тогда уже создавать классы-хелперы, которые позволяют создать слабую связь между данными и методами, заставляя разработчика проектировать архитектуру данных.
Чем-то мне это напоминает «каждая мать хочет, чтобы ее сын женился, но ни на одной из существующих женщин». В каждой концепции есть изъяны, но если вам и для ваших задач подходит, это не повод от неё отказываться :)
Надо почитать мысли Алана Кея, чтобы понять что ООП это не про классы.
Еще есть книга МЧМ Фредерика Брукса написанная аж в 80е годы. Там тоже расскрывается тема разных ООП подходов. Классы — это лишь один из подходов.
Как только разобраться в том что есть ООП — все эти холивары начинают походить на цирк и спор слепых людей о цвете помидора.
Так что, на мое мнение, статья не более чем лукавство, и очень напоминает методику продвижения «серебряных пуль» для начинающих и/или невникающих.
Насколько я понимаю, возможность повторного использования кода в ООП — лишь "бесплатный бонус". Создавалось оно, чтобы уменьшить сложность программ.
Парадигма ООП позволяет структурировать код ПО и избавиться от дублирования, но не упрощает ни его написание, а в сложных проектах не упрощает и его понимание.
В разрезе вопроса о сложности ПО нужно определиться с критерием «сложность» — сложность по реализуемым функциям, данным и т.д., или сложность по исходному коду.
Определите, чем одно отличается от другого
Парадигма ООП позволяет структурировать код ПО и избавиться от дублирования, но не упрощает ни его написание, а в сложных проектах не упрощает и его понимание.
По сравнению с чем? ОО помогает абстрагировать интерфейс от деталей реализации и разбиение на независимые компоненты. Код разбитый на куски понимать легче чем код одним куском.
По сравнению с чем?
В контексте обсуждаемой статьи — по сравнению с без ООП.
Определите, чем одно отличается от другого
Разве нет разницы между реализации сложной функции лаконичным кодом, а простой функции через «пень-колоду»?
ОО помогает абстрагировать интерфейс от деталей реализации и разбиение на независимые компоненты.
Всегда ли нужна абстракция? Если абстракция самоцель, то зачем она нужна, ведь цель ПО в реализации возложенного на него функций и процессов. «Независимость» в ООП — так себе аргумент, особенно при наличии композиции, ассоциации и агрегации. Да и само наследование в ООП подразумевает зависимость дочернего от родительского.
Код разбитый на куски понимать легче чем код одним куском.
Функции и модули чем не куски? Навскидку, для php, чтобы не было «портянкой» пишите хоть по одной функции в файле и подключайте.
В процессе дискуссии о парадигме ООП вы ввели в дискуссию понятие «компоненты». Что вы подразумеваете под «компонентами», так как в классической парадигме ООП «компонентами ООП» иногда называют ее принципы: инкапсуляцию, наследование и полиморфизм?
Если вы имеете ввиду визуальные, функциональные и т.д. компоненты, то они могут быть реализованы как с, так и без ООП. Так что, в этом случае, отношение указанных компонентов к парадигме ООП вторично, и не определяют внутреннюю реализацию. Например, визуальные web-компоненты на основе jQuery, в части их множества, в исходном их коде, ООП не используется.
По моему мнению, на текущий момент времени, в классическом понимании «ООП или не ООП» — это вопрос языка, предпочтений и целесообразности, иногда и инструмента.
Всегда ли нужна абстракция? Если абстракция самоцель, то зачем она нужна, ведь цель ПО в реализации возложенного на него функций и процессов.
Всегда ли нужно сокрытие несущественных деталей? Конечно, они же не существенны, и понять логику работы программы проще когда проще сосредоточиться исключительно на важных вещах.
«Независимость» в ООП — так себе аргумент, особенно при наличии композиции, ассоциации и агрегации. Да и само наследование в ООП подразумевает зависимость дочернего от родительского.
ООП которое подразумевает независимость не подразумевает обязательное наследование.
Функции и модули чем не куски? Навскидку, для php, чтобы не было «портянкой» пишите хоть по одной функции в файле и подключайте.
Если разбить портянку на 10к строк на 100 файликов по 100 строк и вызвать их по очереди портянка никуда не денется, сложность программы не уменьшиться, а скорее ещё и увеличиться, за счет количества файлов.
Парадигма ООП позволяет структурировать код ПО и избавиться от дублирования, но не упрощает ни его написание, а в сложных проектах не упрощает и его понимание.
в классическом понимании
Это каким? Уже «пониманий» 10 вывели только под этим постом. «Классическое» из первоисточников для того и было создано, чтобы сложностью управлять, путем разделения программы на на независимые и децентрализованные «объекты» с собственным жизненным циклом.
Всегда ли нужно сокрытие несущественных деталей?
Зачем же вы их реализуете в коде, если они «несущественные»? Специально вбил в поиск «несущественных деталей» и, сразу вездесущая Википедия. Несущественными детали внутренней реализации объекта могут стать только на следующем уровне иерархии при рассмотрении его как завершенного и отвечающего всем предъявляемым к нему требованиям, поэтому однозначное определение «несущественные» не корректно.
Абстракция — это один из методов системного анализа, где система (подсистема) абстрагируется в виде «черного ящика». И было сказано, что абстракция — не должна быть самоцелью, так как цель — реализация задачи, потому что для конечного потребителя глубоко наплевать как и что вы «абстрагировали». И ничего не было сказано про скрытие или раскрытие — это не хороший прием дискуссии, когда вы присваиваете оппоненту заведомо ложное высказывание, а потом его опровергаете.
Если разбить портянку на 10к строк на 100 файликов по 100 строк и вызвать их по очереди портянка никуда не денется
Формально портянка-таки денется, опять же фразы «по очереди» не было.
ООП которое подразумевает независимость не подразумевает обязательное наследование.
Там было еще указано про композицию, ассоциацию и агрегацию.
Ну а в последнем абзаце произведен вопрос и неточный (опять эта «независимость» и неопределенный критерий «сложность») ответ на него же. Откуда взялось эта «независимость» в парадигме ООП? С точки зрения системного анализа, который и явился прародителем ООП, «независимость» рассматривается в разрезе целой системы, как самодостаточной, органичной и завершенной формы. Постоянно про нее (независимость) говорят, но никто и никогда не видел, наверное, только если все приложение (система, подсистема) представляет собой реализацию в виде одного объекта или без оного.
В контексте обсуждаемой статьи — по сравнению с без ООП.
Судя по уровню вопросов буду считать "Без ООП" для вас это процедурное программирование, а не какие-нибудь монадические комбинаторы.
«Независимость» в ООП — так себе аргумент, особенно при наличии композиции, ассоциации и агрегации. Да и само наследование в ООП подразумевает зависимость дочернего от родительского.
Есть зависимое, есть независимое, абстракции помогают сделать больше частей программы независимыми.
Функции и модули чем не куски? Навскидку, для php, чтобы не было «портянкой» пишите хоть по одной функции в файле и подключайте
Вопрос, что это будут за функции — вот, например функция enumerate в питон. Она приписывает каждому элементу входящей последовательности число по порядку:
# это работает одинаково
# для строк
list(enumerate("Hello, world"))
[(0, 'H'), (1, 'e'), (2, 'l'), (3, 'l'), (4, 'o'), (5, ','), (6, ' '), (7, 'w'), (8, 'o'), (9, 'r'), (10, 'l'), (11, 'd')]
# для списов чисел
list(enumerate(range(500, 600, 10)))
[(0, 500), (1, 510), (2, 520), (3, 530), (4, 540), (5, 550), (6, 560), (7, 570), (8, 580), (9, 590)]И вообще для всего, что можно представить в виде последовательности. Это достигается за счет того, что enumerate работает с абстракцией без знания конкретной реализации — ему надо знать, что исходный список состоит из каких-то элементов, не важно каких и все.
Разве нет разницы между реализации сложной функции лаконичным кодом, а простой функции через «пень-колоду»?
Язык это средство выражения — он может только выразить ту же функциональность в другой форме.
Всегда ли нужна абстракция?
В программировании без абстракции никак. Число — это тоже абстракция. Даже при вождении машины — сейчас можно не знать как именно она работает и пользоваться.
Функции и модули чем не куски?
Функции и модули — это куски просто в ООП больше способов выделить кусок за счет абстрагирования.
Слово "компоненты" я использовал в неформальном значении — как относительно независимый кусок программы.
«Без ООП» для вас это процедурное
Привожу ссылку с Хабра «Забытые» парадигмы программирования
В программировании без абстракции никак.
Если вы никогда не писали на низком уровне (машинный код, ассемблер и тд), то это не значит, что ваше высказывание истинно. Простой пример: АСУ ТП, когда микроконтроллер имеет только входные данные и управляет исполнительным механизмом — абсолютно никакой абстракции (значение вход, уставка, реакция, управляющий выход и обратная связь).
относительно независимый
Уже лучше.
Ваш пример абстракции реализации функции enumerate в python — он про абстракцию, но не про разделение кода на куски в цитате которую вы взяли. Путаница между «цели и средства», так как пример доказывает наличия абстракции, но не опровергает или не утверждает разделение кода по различным подключаемым файлам, как средство повышения читабельности кода.
Язык это средство выражения — он может только выразить ту же функциональность в другой форме.
В «другой форме» не может, а может только в форме этого языка, то есть в своей форме. Вопрос был в лаконичности кода. Простой пример: Для неизменного тягового организма, способность увеличения скорости гужевого транспортного средства увеличивается, при исключения лица женского пола из числа пассажиров, перевозимых этим гужевым транспортным средством.)
А чтобы было ближе к программированию, то на Хабре найдется все: Индусский код в Микрочипе
Если вы никогда не писали на низком уровне (машинный код, ассемблер и тд), то это не значит, что ваше высказывание истинно.
Если вы не понимаете определение слова "абстракция" то это не значит что ваше высказывание истинно.
Простой пример: АСУ ТП, когда микроконтроллер имеет только входные данные и управляет исполнительным механизмом — абсолютно никакой абстракции (значение вход, уставка, реакция, управляющий выход и обратная связь).
Простой пример: у некого племени камень лежащий около воды и камень лежащий в лесу обозначались разными словами. А просто слова "камень" не было, и это все абстракции (просто разного уровня). Отсутствие абстракции наверное, это просто взять конкретный камень и начать долбить им конкретный кокос.
А все эти ваши контроллеры, порты, числа, биты — это все абстракции.
Ваш пример абстракции реализации функции enumerate в python — он про абстракцию, но не про разделение кода на куски в цитате которую вы взяли.
А функция это что не один из кусков, на которые разделен код? Пример одновременно про абстракцию и про разбиение на куски. Потому, что это связанные явления — выделение абстракции позволяет отделить код, который занимается обходом коллекции от реализации конкретной коллекции и соответственно выделить обобщенные алгоритмы работы с ними в отдельную библиотеку.
не опровергает или не утверждает разделение кода по различным подключаемым файлам, как средство повышения читабельности кода.
Отвергает, в PHP без ООП вы просто такой функции сделать не сможете и этот кусок у вас буден размазан в разных копиях. Именно больший уровень абстракции позволяет выделять код в разные куски.
В «другой форме» не может, а может только в форме этого языка, то есть в своей форме.
Почему эта форма не может быть названа "другой" по отношению к форме на другом языке?
Простой пример:
Исходная поговорка про скорость вообще ничего не утверждала. При перекодировании внесли ошибку. :D
Если вы не понимаете определение слова «абстракция» то это не значит что ваше высказывание истинно.
Ну тогда назовите правильное, на ваш взгляд, определение абстракции в парадигме ООП (ведь мы никуда не уходили из рамок дискуссии, или уже ушли?) и приведите пример из низкоуровневого языка программирования, где существует абстракция. Там где вы, например, не учитываете тот или иной регистр используемый в текущей программе.
Отсутствие абстракции наверное, это просто взять конкретный камень и начать долбить им конкретный кокос
То есть все-таки не все абстракция? Или все? С точки зрения процесса познания, абстрагирование — неотъемлемая часть этого процесса. Или мы уже не про парадигму ООП, а про философию?
А функция это что не один из кусков, на которые разделен код? Пример одновременно про абстракцию и про разбиение на куски.
Про это уже мной неоднократно написано, что разговор был про разделение, а вы все про абстракцию, которую вы сами впихнули и продолжаете доказывать ее неотвратимость.
в PHP без ООП вы просто такой функции сделать не сможете и этот кусок у вас буден размазан в разных копиях
А кто-то писал про ее необходимость в такой именно реализации? Как же это раньше PHP без ООП функционировал с многомиллионной армией разработчиков!?
Почему эта форма не может быть названа «другой» по отношению к форме на другом языке?
Для начала перечитайте приведенное вами определение языка, в котором ни слова про «другой» язык не было. Или это тоже ваша «абстракция», в виде скрытия незначимого, вами умалчиваемого, а впоследствии представляемого за аргумент? Ну так зачем вы аргументируете свойством «другой», если ваша абстракция считает сей момент незначительным?
Исходная поговорка про скорость вообще ничего не утверждала
В указанном мной варианте есть словосочетание «способность увеличения». Пожалуйста, будьте внимательнее! Из курса школьной физики F=am -> a=F/m, F = const, так как «для неизменного тягового организма». Можете предложить свой вариант, с точки зрения физики.
PS: За сим откланиваюсь, ибо дальнейшую дискуссию, в ключе постоянного расширения ее рамок в одностороннем порядке, и при невнимательности к аргументации оппонента, считаю нецелесообразной.
Ну тогда назовите правильное, на ваш взгляд, определение абстракции в парадигме ООП (ведь мы никуда не уходили из рамок дискуссии, или уже ушли?) и приведите пример из низкоуровневого языка программирования, где существует абстракция.
Пожалуйста ассемблер Mov AX, 5
5 — это число, что есть абстракция, может обозначать и 5 баранов и 5 программистов и уровень какого-то сигнала
Там где вы, например, не учитываете тот или иной регистр используемый в текущей программе.
Регистр это тоже абстракция — ваш код может исполняться внутри ВМ и вообще ассемблер транслируется в микрокод.
А кто-то писал про ее необходимость в такой именно реализации?
Никто не писал. Никакой необходимости нет, просто в одном языке есть возможность сделать высокоуровневую абстракцию а в другом языке только низкоуровневую. Соотвественно в одном языке это можно выделить в отдельный кусок, переиспользовать его и понять один раз, в другом придется писать и читать понимать несколько копий одного и того же. Как у того народа где "камень у воды" и "камень в лесу" — это разные понятия.
Для начала перечитайте приведенное вами определение языка, в котором ни слова про «другой» язык не было.
Вполне возможно я не совсем точно выразился, но мы вроде достигли понимания того, что я имел ввиду.
В указанном мной варианте есть словосочетание «способность увеличения». Пожалуйста, будьте внимательнее! Из курса школьной физики F=am -> a=F/m, F = const, так как «для неизменного тягового организма». Можете предложить свой вариант, с точки зрения физики.
Я не так хорошо разбираюсь в кобылах, я просто сказал, что в исходной поговорке не содержится этого утверждения. Может скорость кобылы чем-то ограничена сверху и она не может конвертировать облегчение в ускорение. )
сим откланиваюсь, ибо дальнейшую дискуссию, в ключе постоянного расширения ее рамок в одностороннем порядке, и при невнимательности к аргументации оппонента, считаю нецелесообразной.
Как угодно
А все эти ваши контроллеры, порты, числа, биты — это все абстракции
Видимо, все-таки философия, а не ООП. П — значит программирование, то есть заведомое ограничение предметной области. Если мы рассматриваем программную абстракцию от аппаратной, то это системотехника или программирование!? Прошу обратить внимание! на «программную абстракцию от аппаратной», а не «программную от программной». Хотя, какая уже разница мы уже про философию.)
Если мы рассматриваем программную абстракцию от аппаратной
Я не очень понял грамматически фразу мы "рассматриваем от" или "программная абстракция от"?
Разговор про абстракции начался с того, зачем они нужны. Вкратце — без них не получится написать кода, но абстракции более высокого уровня нужны чтобы писать его меньше, легче понимать и делать меньше ошибок. ООП позволяет создавать более высокоуровневые абстракции по сравнению с процедурным программированием без ООП.
В ФП есть, кстати, тоже свои способы.
Имеется в виду, что ООП создан для того, чтобы уменьшить сложность, вносимую программистом в предметную область, для её моделирования. Как раз чтобы упростить понимание сложных систем, решающих сложные задачи. Разделяй и властвуй.
С точки зрения системного анализа, для создания модели реализуемой предметной области (моделирования), он должен произвести декомпозицию, с последующим агрегированием, но ни в коем случае не изменять предметную область, тем более в сторону усложнения. Представляете себе картофелеуборочный комбайн со снеговой лопатой — это пример изменения предметной области «уборка картофеля в части функциональной подсистемы выкопать» с последующей реализацией.)
Неточно выразился. Дополнительная сложность вносится в систему: сложность системы = сложность предметной области + дополнительная сложность, вносимая при том или ином способе его моделеирования. ООП создано уменьшать эту дополнительную сложность.
дополнительная сложность, вносимая при том или ином способе его моделеирования
Предлагаю точнее — сложность самого процесса моделирования систем, процессов и явлений реального мира. Поэтому часто и упоминается Системный анализ, как прародитель ООП. Потому что в свое время Системный анализ стал эволюционной ступенью развития методологии познания, так и ООП стал ступенью развития разработки ПО расширяющий его в прикладной сфере (не в смысле прикладное ПО, а в смысле прикладное использование методологии).
ООП создано уменьшать эту дополнительную сложность.
Как приближенная проекция действительности, смоделированная в соответсвии с методологией Системного анализа, которая (методология) позволяет более рационально и регламентированно произвести это проецирование.
PS: Немного покопался и нашел небольшую статью Системный анализ (Systems Analysis) достаточную для воспоминания и краткого ознакомления. Может кому пригодиться.
1. Допустим, у нас несть некий объект, который в ответ на вызов его функций делает внутри себя что-то сложное. Например, что-то анализирует, накапливает. Потом в ответ на вызов других функций он возвращает некие результаты этого своего внутреннего процесса. Это замечательное применение ООП и инкапсуляции. Мы имеем черный ящик, которым можно пользоваться не вникая как он работает. Внутри него есть данные, но они скрыты и как они устроены вообще знать не нужно. А если понадобится, его можно будет реализовать в разных вариациях, организовав иерархию наследуемых классов. Ничего лучше и не придумаешь.
2. Допустим, у нас есть список сходных сущностей и нам нужно выполнить для них всех некую операцию, детали которой зависят от конкретного типа сущности. Тогда, мы используем ООП и полиморфизм. И опять, все красиво, полиморфная часть кода записана внутри класса. Ничего лучше и не придумаешь.
3. Допустим, у нас есть некий простой объект, который изначально вводится ради его полей, в которых он хранит данные (например, доменный объект, юнит в игре, видимый элемент в графическом редакторе). Допустим, мы запрограммировали в этом объекте некое «поведение» — функции, работающие с его данными более сложные, чем обычные setter-ы. Это ООП, который я никогда не мог понять. Для меня это ужасное и вредное применение ООП. Сценарии поведения чуть посложнее сразу становятся страшно запутанными. Где заканчивается поведение одного класса и начинается поведение другого? Почему так много вариантов как это можно реализовать и чего ради все эти мучения? Что будет если поведение придется дорабатывать? Что если поведение объектов зависит от того какая задача сейчас решается (случай имитационного моделирования)? Почему я должен ломать голову об этом уже сейчас и чего ради вообще все эти сложности?
Во много раз проще описать поведение в отдельных функциях (статичных или в виде отдельных классов-обработчиков). Возможно есть некие особые виды ПО, с которыми я не сталкивался и в которых доменно-подобные объекты с поведением что-то дают. Для меня это загадка.
Вы написали что-то вроде "Допустим, у нас код плохой, и сценарии запутаны. Зачем нужны эти сложности". Код плохой это наверно не очень хорошо, только причем тут ООП. И без ООП было бы так же запутано. Если б вы пример какой-то привели, можно было бы проверить, связано это с ООП или нет.
Могут решаться задачи нахождения каких-то общих показателей для схемы, поиска требуемых изменений схемы или переключений в схеме. Хорошая ли идея, пытаться представить требуемые алгоритмы как поведение доменных объектов? Это очень сложно. Допустим, это удалось. В чем преимущества такого решения? Какого-то скрытия сложности не получается, потому что алгоритмы моделирования и оптимизации сами по себе проще чем тем те же алгоритмы представленные в виде поведения доменных объектов.
Другой пример — пишем графический редактор, позволяющий редактировать табло с бегущими строками, расписаниями и др. Объекты здесь — это видимые на табло редактируемые элементы. Понятно, что в эти объекты удобно спрятать сложный и полиформыный код, типа функций рисования, удаления, перемещения при редактировании. Но стоит ли пытаться поместить саму логику редактирования в методы этих объектов? Эта логика работает сразу с несколькими объектами разных классов и это эту логику не сложно понять. Зачем делить эти алгоритмы на части по методам отдельных классов?
Покажете пример кода без ООП, где эти задачи решены?
Доменные объекты — выключатели, трансформаторы, узлы и ветви графа схемы.
каких-то общих показателей для схемы, поиска требуемых изменений схемы или переключений в схеме. Хорошая ли идея, пытаться представить требуемые алгоритмы как поведение доменных объектов?
А где у вас доменный объект "Схема"? Он у вас в 3 задачах появляется. Вот в этом объекте и будет эта логика.
Но стоит ли пытаться поместить саму логику редактирования в методы этих объектов? Эта логика работает сразу с несколькими объектами разных классов
Не стоит. Значит у вас в предметной области есть объект, который вы не учли, он и содержит логику взаимодействия разных классов.
Не вижу проблемы. Если кто-то сделал в объекте поведение, не свойственное объекту, значит это неправильное проектирование. Если с процедурами то же самое сделать, это тоже будет неправильно. Как это связано с ООП? Проблемы на мой взгляд обычно возникают когда хотят запихнуть поведение в уже существующие классы, без введения дополнительных. Вот как со схемой в вашем примере.
Мне понятны ваши доводы, но непонятна точка зрения Belikov, ратующего за связь кода с данными любой ценой.
Допустим, в модели с combat-менеджерами мы не можем взять отдельный объект и понять из его кода как он себя ведет в битве. Нужно изучать систему combat-менеджеров. Это видимо и есть главный недостаток. Но ведь в чистой ООП-модели по одному объекту тоже не будет ничего понятно. Будет только понятно, что он ждет чего-то абстрактного и реагирует. Хорошо, если этому абстрактному удалось дать вменяемое название, не требующее пару страниц разъяснений всей концепции. И так далее.
В общем, у меня ощущение, что свободное от анемичных элементов ООП — это технология для очень простых задач или для некого узкого круга задач, с которыми я не сталкивался. В большинстве случаев чистое ООП требует введения очень сложных и довольно неустойчивых абстракций. Точно так же как в случае ФП если задаться целью работать исключительно с чистыми функциями, то все становится очень не просто.
Да нет, поведение должно быть связано с объектом. Только в том примере с игрой в предметной области оно находится не в том объекте, в который его пытаются поместить в коде.
Т.е. если у нас несть некий алгоритм поведения объектов, который легко режется на части по объектам, и эти части хорошо дорабатываются в дальнейшем а мы его не порезали и реализовали как единое целое в неком менеджере — тогда это антипатерн, анемичная модель. Если же этот алгоритм не получается порезать однозначным и естественным образом, не сочиняя дикие неустойчивые абстракции, то тогда и не нужно это делать. Он просто не относится к доменным объектам на самом деле, он относится к объектам уровнем выше.
Если алгоритм можно было разделить по классам, но программист этого не сделал, возможно он плохо владеет ООП. Если алгоритм был неделим по сути, но его ухитрились раскидать по методам классов, так, что теперь концепция системы стала не для средних умов, тогда этот программист применяет концепции ООП не по назначению.
А если у нас есть общее поведение группы объектов, которое теоретически можно порезать по объектам
Нет, резать его по объектам не надо. Если есть группа объектов, которая ведет себя как целое, значит это самостоятельный объект со своим поведением, и для него нужен отдельный класс, в полях которого будет список входящих в него объектов.
Главное делать наиболее точную модель предметной области, а если где-то упрощаем, то надо определять, корректно ли такое упрощение, и что именно нам это дает. Например, про ту же гранату. Необязательно моделировать 1000 осколков при взрыве, можно получить объекты в радиусе поражения, допустим их 2, и смоделировать всего 2 осколка. Это корректное упрощение, потому что моделирование остальных осколков ни на что не влияет.
При этом, формально данные объектов находятся внутри объекта-группы и он имеет право ими оперировать.
Оперирование данными конкретного объекта можно и скорее всего нужно поместить в его класс. В класс группы надо помещать только то, что связано с несколькими объектами.
Алгоритмы поведения доменных объектов — часть модели домена. В зависимости от платформы и соглашений они могут представлены методами объектов-сущностей, другими объектами (сервисами, стратегиями и т. п.), функциями/процедурами, методами базовых классов. При моделировании домена у нас как бы нет уровня выше, "выше" — инфраструктура, UI, API и прочие *I
Чем вас наследование так пугает? Это же просто использование интерфейсов, которые четко описывают возможные взаимоотношения между объектами.
Свободное от анемичных элементов ООП как раз наоборот хорошо подходит для систем сложным поведением. DDD как раз для таких проектов задумывался. По сути это «OOP done right».
Как раз в DDD основные типы объектов есть: полноценные объекты со своим состоянием и поведением — Entity, объекты с состоянием, причём иммутабельным, но без поведения — ValueObject, и объекты по сути без состояния, но с поведением — Service. Ну и на практике часто интерфейсы, "объекты" без состояния и поведения, хотя на каких-то языках их возможно придётся реализовывать абстрактными классами, а то и вообще без них обходиться, на уровне соглашений и документации, особенно если нет множественного наследования.
А наследование страшно тем, что очень часто им пользуются для выражения других сложных отношений кроме "наследник является подмножеством предка", например для "наследник ведёт себя так же как предок" или "наследник реализует тот же интерфейс, что предок
и как предок".
По-моему у вас слишком узкое трактование наследования. Реализация интерфейса — это очень мощный инструмент (хотя это уже полиморфизм, как мне правильно выше написали). Он позволяет описать контракт взаимодействия между объектами, не делая их явно зависимыми друг от друга. В данном примере, монстр может получать урон и стена может получать урон, они никак не связаны, но за счет интерфейсов мы можем работать с ними единообрзно. И такая система легко расширяется, т.е. если еще какой-то объект может получать урон, достаточно в нем реализовать интерфейс и уже готовая часть системы с ним автоматически состыкуется.
Наследование в плане взаимодействия — это лишь часть общего контракта класа, который так же включает и реализуемые интерфейсы, и постусловия, и предусловия, и инварианты. Наследование реализует отношение "является", реализация интерфейса скорее "способен", даже если в синтаксисе разницы никакой нет.
Обычная для меня задача выглядит примерно следующим образом. Случается некое событие. Есть граф из связанных объектов (модель). Нужно для этого графа объектов проанализировать что с чем связано, какова общая схема этих связей, сформировать некие сводные результаты, в зависимости это этих результатов нужно создать и вернуть некие новые объекты или внести изменения в существующие.
Этот алгоритм допустим, содержит в 100 или 500 строк кода.
Сам по себе он не очень прост, но разобраться как он работает можно.
Если я создам отдельный класс, в который засуну этот алгоритм, по сути ничего от ООП я не внесу. Это будет фактически класс с одним публичным static методом и множеством приватных.
Настоящим ООП это стало бы, если бы я разделил этот алгоритм между классами модели. Так, чтобы их совместное поведение давало бы тот же результат, что и единый алгоритм. Но это неимоверно сложная задача, для ее решения придется наворочать кучу кода и изобрести много довольно искуственных сущностей и концепций. И даже если она будет решена, впоследствии понять как поведение отельных объектов дает требуемое «эмерджентное» поведение всей системы будет тоже очень сложно. Понять алгоритм, в котором функция вызывает другие функции гораздо проще. Тогда надо ли стремиться к ООП в подобных ситуациях?
Зависит от алгоритма. Если получается, что в приватных методах идёт работа только с одним-двумя типов объектов или их коллекций, то возможно имеет смысл вынести этот приватный метод в один из этих двух объектов или в третий. А возможно не имеет. Смтреть надо
В ООП нет такого явного перехода между состояний и самих состояний в разы больше (по сути это комбинации всех состояний объектов в каждый момент времени). Но фишка в том, что все эти состояния явно перечислять и не нужно — они инкапсулированы в поведении отдельных объектов. И если поведение отдельных объектов и связи между ними реализованы правильно, мы предполагаем что и вся система будет работать как надо. Это как рабочие на конвейере, каждый из которых знает свою часть работы — что он получает от других рабочих, что дает на выходе и во сколько обед. ) Но в то же время есть общая схема, как должен быть устроен весь конвейер. То есть получается декомпозиция системы на подсистемы которая сильно облегчает понимание системы и уменьшает сложность. Можно видеть задачу на нескольких уровнях — когда надо — опуститься до уровня прикручивания отдельной гайки, а в другой ситуации увидеть как система работает на высоком уровне. Подход с одним большим классом такой картины не дает. Преимущества ООП особенно ярко проявляются когда алгоритм уже становится слишком сложным чтобы засунуть его в один большой класс и вообще держать в голове целиком.
И эти сущности и концепции не искуственные, а как раз наоборот — соответствуют объектам реального мира (или той предметной области, которая автоматизируется). Это тоже облегчает понимание. За счет правильной комбинации получается нужное поведение. Я обычно привожу в пример радиоэлектронику — когда есть достаточно ограниченный набор элементов (транзисторы, резисторы и т.д.), но соединив их по-разному можно получить разные устройства.
Есть неплохая книга на эту тему: Г. Буч «Объектно-ориентированный анализ и проектирование с примерами приложений». Там как раз теоретические основы ООП хорошо изложены.
Сейчас, кстати, тот же подход с новой стороны используется — это микросервисы. Идея по сути та же — разделение системы на отдельных агентов, каждый из которых обладает состоянием и поведением и взаимодействует с другими по четко описанным контрактам.
Главное не забывать, что ООП — только один из способов смотреть на предметную область. Иногда удобнее смотреть на неё как на поток преобразуемых данных, иногда как на реализацию математической структуры (тех же монад). В общем, защищаться от терминального ООП головного мозга.
Вы видимо много писали с использованием Redux или похожих подходов.Не совсем так. Я почти не сталкивался с задачами web и всегда работал над задачами моделирования и визуализации на c# (до него на c++).
Он хорошо подходит когда логика достаточно проста и количество возможных состояний небольшое. Тогда действительно можно охватить взглядом весь алгоритм целиком и просто его реализовать.Я понимаю о каких задачах вы говорите. В таких задачах реакция сущностей на возмущение довольно простая, но сложность заключается в том, что в сумме вся совокупность реакций может порождать бесконечное разнообразие сложных ситуаций. В этом случае действительно очень сложно сделать единый алгоритм, который правильно работал бы во всех случаях жизни. Каждый раз мы что-то да не предусмотрим. Гораздо проще реализовать отдельные сущности с поведением, каждая из которых действует по своим правилам и заботится только «о себе», и если эти правила верные, то совместное поведение сущностей автоматически «породит» верный алгоритм обработки в ответ на каждое возможное возмущение.
Мне кажется, проблема в том, что подобные задачи не настолько распространены, как это кажется сторонникам чистого ООП. Для меня подобная ситуация обычно встречается только на уровне обмена сообщениями между крупными объектами-синглтонами, каждый из которых содержит сотни и больше строк код. То что должно происходить с более мелкими объектами (99% сложности программы) никогда не бывает достаточно простым, чтобы его можно было представить как совокупность поведения отдельных сущностей. Всегда нужно одновременно учитывать состояние неопределенного множества объектов, и множества параметров текущей решаемой задачи, о которых эти объекты понятия не имеют. При этом сам алгоритм может содержать тысячи строк но без всяких проблем декомпозируется на функции, в которых вызываются функции и так далее.
Грубый пример, доводящий проблему до абсурда — для принятия решения нужно собрать много информации о доменных объектах в матрицы, решить систему уравнений и разложить результаты обратно по объектам. Алгоритм решения системы уравнений теоретически можно разложить по объектам, но это будет очень сложная и не эффективно работающая программа.
Преимущества ООП особенно ярко проявляются когда алгоритм уже становится слишком сложным чтобы засунуть его в один большой класс и вообще держать в голове целиком.Или у нас может не быть очевидного поведения у подсистем, но зато может быть очевидный всякому алгоритм, который легко представляется в виде выполнения функций, внутри которых выполняются функции и так далее. Тогда пытаться вывернуть его наизнанку и представить как поведение отдельных сущностей означает все неимоверно усложнить. И почти все ситуации, с которыми мне приходилось сталкиваться были именно такими.
Г. Буч «Объектно-ориентированный анализ и проектирование с примерами приложений»Да, с нее я когда-то и начал.
И эти сущности и концепции не искуственные, а как раз наоборот — соответствуют объектам реального мира (или той предметной области, которая автоматизируется).Но это почти никогда так не работает. Во-первых, в моделировании всегда есть какое-то упрощение. Т.е. сущности могут вести себя согласно правилам, но в ситуациях, когда эти правила создают слишком много сложностей мы оставляем за собой право срезать углы в модели. Если эти правила закодированы в поведении объектов, тогда резать углы просто не получится или придется менять всю архитектуру. Во-вторых, ирония в том, что даже атомы в физике подчиняются квантовой механике, которая требует решения уравнений, включающий по сути состояния всей вселенной на входе. Т.е. в реальном мире нет никакой инкапсуляции. Инкапсуляция свойственна только выдуманным нами объектам, вроде «документа».
Пограничная задача: нужно организовать опрос неких источников сигналов согласно заданному расписанию для разных групп и типов, учесть случаи, когда данные получить не удалось и прочие. Дальше, нужно предоставлять эти данные по запросам.
Можно реализовать это в виде анемичной модели: сделать набор менеджеров, отвечающих за опрос, обработку и ответы. Каждый менеджер содержит набор алгоритмов, выполняющих последовательость действий, проверок и др.
Можно реализовать это объектно, где будут опрашивающие по расписанию объекты, передающие свои запросы в общую очередь, дальше каждый отдельный тег данных будет оповещаться о получении новых данных, обрабатывать и сохранять эти данные, отвечать на запрос данных. Или еще как-то (есть много вариантов). Кто-то попытается решить задачу первым способом, кто-то вторым. ИМХО, в первом случае все выглядит проще и кода меньше и есть почти один способ это реализовать. Преимущества второго способа в плане понятности, перспектив доработки и так далее довольно спорные.
Мне кажется, проблема в том, что подобные задачи не настолько распространены, как это кажется сторонникам чистого ООП.
Думаю просто многие не умеют видеть задачу таким образом.
Или у нас может не быть очевидного поведения у подсистем, но зато может быть очевидный всякому алгоритм, который легко представляется в виде выполнения функций, внутри которых выполняются функции и так далее.
А для меня вот это кажется более редкой ситуацией. Это уже какие-то математические вычисления по-моему. Я больше разными бизнес-приложениями занимаюсь.
Но это почти никогда так не работает. Во-первых, в моделировании всегда есть какое-то упрощение. Т.е. сущности могут вести себя согласно правилам, но в ситуациях, когда эти правила создают слишком много сложностей мы оставляем за собой право срезать углы в модели. Если эти правила закодированы в поведении объектов, тогда резать углы просто не получится или придется менять всю архитектуру. Во-вторых, ирония в том, что даже атомы в физике подчиняются квантовой механике, которая требует решения уравнений, включающий по сути состояния всей вселенной на входе. Т.е. в реальном мире нет никакой инкапсуляции. Инкапсуляция свойственна только выдуманным нами объектам, вроде «документа».
Так а 100% точную модель реального мира описывать и не нужно. Это именно модель с уровнем абстрации и инкапсуляции соответствующим решаемой задаче. При решении задач небесной механики у нас целая планета — материальная точка, а в других задачах мы опускаемся до уровня атомов. В каких-то задачах трение учитывается, в каких-то им можно пренебречь.
Если правила создают сложностей, то нужно не срезать углы, а изменять модель чтобы эти правила ложились в нее естественным образом. Это нормальный и естественный процесс, который проходит достаточно безболезненно при должном умении. Но многие почему-то этого боятся и живут в иллюзии, что они нарисуют красивые диаграммы, напишут код и все так и будет работать. В реальной жизни так не бывает.
Пограничная задача: нужно организовать опрос неких источников сигналов согласно заданному расписанию для разных групп и типов, учесть случаи, когда данные получить не удалось и прочие. Дальше, нужно предоставлять эти данные по запросам.
Можно реализовать это в виде анемичной модели: сделать набор менеджеров, отвечающих за опрос, обработку и ответы. Каждый менеджер содержит набор алгоритмов, выполняющих последовательость действий, проверок и др.
Можно реализовать это объектно, где будут опрашивающие по расписанию объекты, передающие свои запросы в общую очередь, дальше каждый отдельный тег данных будет оповещаться о получении новых данных, обрабатывать и сохранять эти данные, отвечать на запрос данных. Или еще как-то (есть много вариантов). Кто-то попытается решить задачу первым способом, кто-то вторым. ИМХО, в первом случае все выглядит проще и кода меньше и есть почти один способ это реализовать. Преимущества второго способа в плане понятности, перспектив доработки и так далее довольно спорные.
То что ООП дает больше вариантов реализации — это как плюс так и минус. Минус в том, что это требует знаний, навыков и опыта. Именно поэтому, как мне кажется сейчас и стали более популярны простые языки вроде Go. Из-за того что программирование стало слишком массовым. А плюс — что правильная модель делает задачу более простой и понятной.
А для меня вот это кажется более редкой ситуацией. Это уже какие-то математические вычисления по-моему. Я больше разными бизнес-приложениями занимаюсь.Не обязательно математические вычисления, просто анализ чего-то, оптимизация, анализ и фиксация событий в неких достаточно сложных системах, визуализация, графические редакторы и др.
Если правила создают сложностей, то нужно не срезать углы, а изменять модель чтобы эти правила ложились в нее естественным образом. Это нормальный и естественный процесс, который проходит достаточно безболезненно при должном умении.«Срезание углов» в данном случае не выбор программиста, так поставлена задача моделирования: что-то моделируется как есть, а в каких-то случаях мы сразу получаем упрощенный ответ, не имея возможности все моделировать. Допустим, мы разложили все это в объекты. Потом постановка задачи меняется. Теперь срезание углов требуется по-другому и в других местах. Если у нас все написано в виде монолитных алгоритмов, в которых функции вызывают функции, тогда все очень легко доработать: нужно просто найти и поменять требуемые функции. Если поведение разложено по объектам, то очень вероятно что придется сносить всю архитектуру классов и изобретать ее по новой. Потому, что архитектура объектов вынужденно отражала не реальный мир, а выдуманный неустойчивый мир методики моделирования.
То что ООП дает больше вариантов реализации — это как плюс так и минус.Много вариантов реализации — всегда минус т.к. следующему программисту придется разобраться какой конкретно их вариантов выбран. Если вариант только один, то что принцип работы кода можно понять даже не видя всего кода.
Минус в том, что это требует знаний, навыков и опыта. А плюс — что правильная модель делает задачу более простой и понятной.Хорошо когда опыт привлекается для построения по настоящему гибкой и прозрачной системы. Я постоянно сталкиваюсь с ситуацией, когда грубо заменив большую часть функций в программе на static я получаю кардинальное упрощение и контроль в ситуациях, когда программа своей сложностью уже просто доводила до отчаяния.
Возможно по каким-то причинам я не смог научиться правильному ООП. Но у меня впечатление, что концепция ООП, согласно которой данные должны быть связаны с кодом — это не универсальный принцип разработки для любых задач. Это прием, позволяющий совладать со сложностью в определенных ситуациях. В всех других ситуациях он создает проблемы вместо того чтобы их решать.
То же самое можно сказать об идее все реализовывать только на чистых функциях.
«Срезание углов» в данном случае не выбор программиста, так поставлена задача моделирования: что-то моделируется как есть, а в каких-то случаях мы сразу получаем упрощенный ответ, не имея возможности все моделировать. Допустим, мы разложили все это в объекты. Потом постановка задачи меняется. Теперь срезание углов требуется по-другому и в других местах. Если у нас все написано в виде монолитных алгоритмов, в которых функции вызывают функции, тогда все очень легко доработать: нужно просто найти и поменять требуемые функции. Если поведение разложено по объектам, то очень вероятно что придется сносить всю архитектуру классов и изобретать ее по новой. Потому, что архитектура объектов вынужденно отражала не реальный мир, а выдуманный неустойчивый мир методики моделирования.
Я точно также могу сказать что модель легко доработать — достаточно найти и поменять отдельные классы. ) Это просто два способа декомпозиции — процедурный и ОО. И вполне может быть такое изменение которое точно также потребует изменить весь ваш алгоритм, а не только отдельные функции. Но на практике я не сталкивался с необходимостью радикально переделать архитектуру классов.
Много вариантов реализации — всегда минус т.к. следующему программисту придется разобраться какой конкретно их вариантов выбран. Если вариант только один, то что принцип работы кода можно понять даже не видя всего кода.
А почему вы кстати решили что при алгоритмическом подходе он только один? Ту же сортировку можно множеством разных способов реализовать.
Хорошо когда опыт привлекается для построения по настоящему гибкой и прозрачной системы. Я постоянно сталкиваюсь с ситуацией, когда грубо заменив большую часть функций в программе на static я получаю кардинальное упрощение и контроль в ситуациях, когда программа своей сложностью уже просто доводила до отчаяния.
Я кажется понял в чем дело. Видимо вам попадался код от архитектурных астронавтов, которые любят усложнять из любви к искусству и создавать кучу фабрик-фабрик-фабрик и применяют паттерны где надо и где не надо. Я это тоже не считаю правильным ООП и тоже стараюсь упрощать такие вещи.
Возможно по каким-то причинам я не смог научиться правильному ООП. Но у меня впечатление, что концепция ООП, согласно которой данные должны быть связаны с кодом — это не универсальный принцип разработки для любых задач. Это прием, позволяющий совладать со сложностью в определенных ситуациях. В всех других ситуациях он создает проблемы вместо того чтобы их решать.
То же самое можно сказать об идее все реализовывать только на чистых функциях.
Согласен что ООП не для всех задач хорошо подходит.
Я кажется понял в чем дело. Видимо вам попадался код от архитектурных астронавтов, которые любят усложнять из любви к искусству и создавать кучу фабрик-фабрик-фабрик и применяют паттерны где надо и где не надо.Да, однажды такой случай был. Как раз для упомянутой выше задачи сбора сигналов с устройств. В большинстве других случаев этим астронавтом был я сам, а код коллег оказывался даже менее ООП-ориентированным, чем мой.
А почему вы кстати решили что при алгоритмическом подходе он только один? Ту же сортировку можно множеством разных способов реализовать.Это сложный вопрос. Например, я реализовывал графический редактор для подготовки чего-то похожего на презентации. Я реализовал поведение объектов при редактировании следующим образом: создается набор синглтонов-обработчиков, каждый из которых получает на входе возмущение (например, событие мыши) и всю модель графических объектов. Его задача — внести требуемые изменения в модель и возможно сгенерировать новые возмущения. Это «анемичный» ООП, т.к. поведение объектов вынесено в отдельные внешние функции.
Как это написать, есть не так много вариантов. Мы знаем события от мыши и клавиатуры, на которые нужно реагировать и дальше алгоритм обработки по сути должен сделать две вещи: классифицировать ситуацию и внести изменения согласно ситуации. Для какого-то креатива простора очень мало. Если нужно изменить некий аспект поведения, мы находим функцию, которая либо классифицирует ситуацию, либо вносит изменения и дорабатываем или перекрываем ее. Понятно, что каждая функция в свою очередь вызывает множество более мелких функций, часть из которых используется повторно и так далее. И, да, каждая из функций, вносящих изменения в модель в принципе может иметь неопределенные побочные эффекты, будучи не ограничена ни функциональной чистотой, ни инкапсуляцией.
Допустим, я захотел бы сделать это на чистом ООП. Тогда уже в архитектуре классов нужно учесть множество факторов. Например, некоторые правила поведения объектов недоступны в режиме просмотра и доступны в режиме редактирования (как объекты узнают о текущем режиме?). Сходные графические объекты в разных приложениях, созданных на базе одной библиотеке должны вести себя по разному (нужно гибко наследовать поведение). Как реализовать, скажем поведение сгруппированных объектов? Как конкретно объект-группа узнает, что одного из его child выбрали мышью? Это все требует очень приличных интеллектуальных усилий и вариантов решения каждой проблемы будет очень много. Потребуется изобрести определенные концепции, абстракции, теории. Если теории не учтут что-то придется все переделывать и переосмысливать. Тому кто потом захочет это сопровождать нужно будет разбираться в принятых решениях. Я пытался делать такие вещи и при этом каждый раз задавался вопросом — «почему я этим всем занимаюсь?».
концепция ООП, согласно которой данные должны быть связаны с кодом — это не универсальный принцип разработки для любых задач.
ООП не запрещает вам создавть объекты без данных или без кода. А часто вообще не запрещает не создавать объекты :)
Если у нас все написано в виде монолитных алгоритмов, в которых функции вызывают функции, тогда все очень легко доработать: нужно просто найти и поменять требуемые функции.
Если бы всё так просто было. Не просто функции вызывают функции, а функции принимают функции как параметры, функции возвращают функции как параметры, функции частично применяют функции, функции принимают решения какую из функций вызвать путём вызова других функций. При том типы данных, которые все эти функции обрабатывают описаны совсем в других местах, а некоторые функции с ними ещё и манипулируют, добавляя или удаляя элементы (и хорошо если иммутабельно). Может в чисто функциональных языках это гораздо проще, но в языках вроде функциональных, но где вся, или почти вся функциональщина заключается в том, что функции — сущности первого класса, причём нетипизированные, вот это "просто найти и поменять" может превращаться в ад.
Объекты можно видеть по разному. Например "вычисление" тоже может быть объектом.
Но ИМХО основная сомнительная посылка статьи:
структура данных определяет необходимый код
Сошлюсь на известную классическую книгу Вирта, не содержащую ООП:
Алгоритмы + структуры данных = программы
Об алгоритмах автор забыл? Умолчал?
Простое преобразование данных превращается в кучу неуклюжих взаимопереплетённых методов, вызывающих друг друга, и причина этого только в догме ООП — инкапсуляции.
Недавно в другом обсуждении писал про виртовкий (не ОО) Паскаль:
Простейшая инкапсуляция уже есть в записях (record). Далее понятие о наследовании приходит в таких простых примерах:Но автор борется с ветряными мельницами — многие ЯП не настаивают на использовании ООП, как не настаивают на использовании записей (record) и IDE. Не хотите использовать визуальное средство разработки — чертите на бумажке окошки вашей программы, меряйте линейкой координаты и записывайте в ресурс в виде текста. Бывают случаи ограниченного использования ООП, из собственного опыта: для игрового бота взял интерпретатор Паскаля (Вирт и др.), написанный не в ООП, и приделал IDE, сделанное в ООП.
type TCoord = record // координаты точки x, y : integer end; TRect = record // прямоугольник leftTop, RBot : TCoord; end;
Если данные программы, например, хранятся в табличном, ориентированном на обработку данных виде, то можно создать два или более модулей, каждый из которых работает с той же структурой данных, но различным образом. Если данные разбиты на объекты с методами, то это больше невозможно.Снова сошлюсь на свой опыт: ООП не мешает (а помогает) использовать столь нелюбимые автором графы в различных представлениях.
огромные спагетти-графы объектов, указывающих друг на друга, и методы, получающие огромные списки аргументов.
Давным давно для одного коммерческого проекта делал GUI на упомянутом Macintosh 68K под упомянутым ResEdit. Списки аргументов были гораздо больше, чем м.б. с применением ООП. Чтобы убедится достаточно посмотреть многотомниик Inside Macintosh тех лет — там много примеров.
Сочетание разброса данных по множеству мелких объектов, активное использование косвенности и указателей, отсутствие правильной архитектуры данных приводят к низкой скорости выполнения. Такого обоснования более чем достаточно.Это не обоснование, а голословное утверждение. Необходимы примеры со сравнением времени выполнения.
Пожалуй единственная мысль, возникшая по прочтении этой статьи, с каковой мыслью согласен: при большом желании можно сделать очень плохой код, как с применением ООП, так и без.
Если человек хочет писать бизнес логику на SQL, то кто ему доктор? Уже некоторые базы данных дают REST API, которое дёргает функции внутри самой БД.
Но по сути статья бредовая.
Пишу на Delphi, достаточно толстые проекты, миллион строк+. Без ООП была бы каша из типов, хранилищ данных и функций, их обрабатывающих. С ним всё проще: понятно, где данные хранить и как их обрабатывать — всем занимается один класс.
«понятно, где данные хранить и как их обрабатывать — всем занимается один класс» — похоже на использование классов в качестве неймспейсов для «мнемонического» разделения кода, а не для описания семантики модели.
God object это больше про зависимости. По хорошему какие хранить и как обрабатывать данные внутри себя исключительно дело самого объекта, а остальные компоненты должны полагаться лишь на его поведение.
Я понимаю, что автор имел ввиду просто сращивание в коде структуры данных и методов их обработки, а не бизнес-функции разрабатываемой инфосистемы, и подчёркнуто нелепо отвечал так, будто оппонент написал класс TDataHranenieAndObrabotka. Чтобы намекнуть на то, что ООП немношк не про сращивание методов со структурами, а то, что оппонент описал, это, скорее, про модульность, а не про ООП.
God object это больше про ответственности.
цель -> архитектура данных -> код
Дело в том, что подобный подход напрямую определяет зависимости у которых «порядок менять ни в коем случае нельзя!», и именно на этом я бы хотел заострить внимание аудитории.
Но для начала, давайте немного поговорим о терминологии, чтобы мы правильно друг друга понимали, общались едиными терминами:
Цель — субъективно я понимаю это как конечное желаемое состояние системы. Цель сама по себе абстрактна, она не предполагает ни средства, ни пути достижения, ни является автоматически доказуемой (то есть мы не можем обладая только целью утверждать о ее достижимости в принципе, так как это требует доказательной базы).
Например: цель — сделать двигатель, который будет перемещать транспортное средство быстрее скорости света; или, скажем, реализовать проект, который поглотит 120% емкости рынка (при очевидном максимуме в 100%).
Я хочу обратить внимание на то, что цель (правильнее сказать, не каждая цель, не все цели) не всегда является правильной исходной точкой при построении системы, так как адекватность цели требует доказательств (в идеале), поэтому позволю себе внести некоторую поправку (будем считать это первой аксиомой в построении системы) — необходимо определить целевую функцию с оптимизацией по целевым критериям, то есть построение системы должно иметь как минимум смысл с точки зрения «реализуемости», в противном случае реализация может стать попыткой реализовать невозможное (вне зависимости от дальнейшей структуры данных и логики).
Я считаю это важным при построении дальнейших рассуждений.
Архитектура данных — субъективно я понимаю это как конкретную конфигурацию представления данных (из бесконечного множества конфигураций), понятную инженеру и выбранную им с точки зрения оптимизации по целевым критериям.
Архитектура данных не определяет логику, этот слой системы абстрагирован от цели также как и абстрагирован от функционала. Конфигурация представления данных является отдельной сущностью, производной действий инженера. Чуть ниже я раскрою смысл акцента внимания на этом.
Код (логика) — субъективно я понимаю это как конечный алгоритм созданный с учетом определенных требований (целевых критериев). При этом алгоритм не определяет структуру входных данных, он лишь предполагает ее наличие, и это предположение основано на целевых критериях, которые выбраны или приняты инженером, также как выбраны и приняты инженером структуры выходных данных.
Цель, архитектура данных, код (логика).
Цель не определяет архитектуру данных.
Архитектура данных не определяет цель и не определяет логику.
Логика не определяет цель и не определяет исходную структуру данных, а лишь предполагает исходную структуру данных.
Я хочу обратить внимание, что эти сущности изолированы сами по себе, а связи между ними определяются на уровне сознания разработчика(ов). Именно интерпретация (конкретная частная) формирует сквозные зависимости между целью, конкретной конфигурацией представления структуры данных и логикой, предполагающей структуру данных.
Связи между «слоями» являются ментальной проекцией и не выражены формально, даже если цель и структуру данных, а также код создает один и тот же человек.
Причем тут ООП или «что ты несешь?!»
Дело в том, что структурные ограничения, функциональное программирование, объекто-ориентированное представление, парадигмы построения, методы декомпозиции, управления, оптимизации — все это является способами «соединения слоев» в рамках ограничений на уровне восприятия сознанием сущностей и связей между ними.
Никто не мешает писать логику с точки зрения манипуляции атомарными единицами информации, без каких-либо ограничений, представляя часть атомарных сущностей данными, а часть инструкциями… Но это невероятно сложная задача для нашего сознания на современных масштабах систем. Люди вынуждены выдумывать способы уменьшения роста уровня сложности создаваемых систем. Именно для этого создаются концепции и парадигмы. Упрощение — это всегда ограничение.
Говоря об ООП (в контексте статьи), нельзя утверждать, что это «плохо», так как это лишь способ представления композиции функционала и контекста (данных), созданный с определенными целями, в частности для достижения инкапсуляции, полиморфизма и наследования.
Говоря о том, что ООП не так хорош, необходимо более убедительно представить, чем не столь хороши по отдельности инкапсуляция, полиморфизм и наследование, а также в первую очередь постараться осознать для самого себя, «а правильно ли я осознаю эти концепции»?
Вероятно «неудобство» и ограничения связанные с использованием ООП (с учетом конкретных примеров) вполне могут быть метафорически представлены ситуацией, когда ключом на 13 может быть неудобно откручивать гайку на 11, а возможно даже и ситуацией, когда ключом на 13 неудобно или невозможно закручивать саморез…
Инкапсуляция — субъективно понимается мной как способ абстрагирования. В свою очередь абстрагирование — это самый эффективный способ резкого снижения уровня сложности системы. Инкапсуляция — крайне эффективный метод контроля уровня сложности.
Это не плохо само по себе.
Наследование — субъективно понимается мной как способ расширения абстракций (инкапсулированных сущностей) с целью адаптации алгоритма к изменениям целевых критериев с учетом минимальных изменений. В свою очередь минимизация изменений уменьшает рост уровня сложности системы в отличие от полностью альтернативной реализации «с нуля». В некотором смысле это похоже на вынесение общего множителя за скобки при увеличении уровня сложности формулы.
Это не плохо само по себе.
Полиморфизм — субъективно понимается мной как способ организации расширения поведения в зависимости от контекста без необходимости увеличения количества абстракций и расширения абстракций через наследование. При полиморфизме общий уровень сложности системы изменяется минимально, так как полиморфное поведение описывается в рамках базовой абстракции.
Это не плохо само по себе.
Так я хочу показать вам, что можно рассматривать данные парадигмы в рамках ООП с точки зрения контроля уровня сложности. Вы должны осознать, что вы используете ООП не для кого-то, а для себя лично, для вашего сознания и ограничений на уровне сознания при восприятии системы в целом. Это напрямую влияет на общую производительность и возможности поддержки и масштабирования.
Нет плохих систем или хороших, есть те, которые удовлетворяют или не удовлетворяют целевым критериям.
Плохо спроектированные системы быстро становятся слишком сложными, а потому их очень сложно и как следствие дорого поддерживать и масштабировать.
Хорошо спроектированные системы легко адаптировать, так как они воспринимаются простыми и при минимальном вложении труда удовлетворяют целевым критериям.
Устали? Осталось потерпеть одну минутку!
Недостаточно просто понимать, что есть некоторые представления (парадигмы) о методах управления уровнем сложности при проектировании логики, так как это один из способов композиции низкого уровня.
Сами по себе эти принципы применяются при формировании сущностей (абстракций), которыми мы непосредственно оперируем при построении систем: классы и абстрактные классы, интерфейсы, трейты, примеси и т.д.
Уровни совершенно разные: от физических явлений, представляемых «сигналами», через совокупности сигналов представляемых «инструкциями», через совокупности инструкций представляемых «мнемониками ассемблера» и т.д. вплоть до реализации той или иной парадигмы в конкретной реализации вашего любимого языка программирования высокого уровня.
Каждый масштабный уровень системы обладает своим набором возможных абстракций.
А потому каждый масштабный уровень системы обладает своими методами оптимизации композиций абстракций.
Именно поэтому на уровне композиции таких абстракций (классы, интерфейсы, абстрактные классы) возникают сложности, так как для них не применимы инкапсуляция, наследование или полиморфизм, — все эти методы уровнем ниже. Именно в этот самый момент мы попадаем в волшебный мир тонкостей архитектуры (дизайна) систем с точки зрения композиции составляющих ее сущностей в самом широком смысле этого слова.
В этот момент мы открываем для себя принципы проектирования ООП, такие как SOLID:
S (The Single Responsibility Principle) — принцип единой ответственности (SRP).
O (The Open Closed Principle) — обозначает принцип открытости/закрытости (OCP).
L (The Liskov Substitution Principle) – принцип подстановки Лисков, описывающий возможности заменяемости экземпляров объектов (LSP).
I (The Interface Segregation Principle) — принцип разделения интерйесов (ISP).
D (The Dependency Inversion Principle) — принцип инверсии зависимостей (DIP).
Эти принципы основаны на ООП, основаны в своей сути на инкапсуляции, наследовании и полиморфизме, но находятся на один уровень выше в системе.
К чему это я? Да к тому, что говорить «хорошо» или «плохо» как минимум слишком ограниченно, причем ограниченно контекстом восприятия. При действительно масштабном представлении системы происходит своего рода «мульти-интерпретация» в рамках которой парадигмы, методы проектирования или методы разработки в целом (Waterfall, SCRUM, Kanban) являются лишь инструментами в ваших руках, и целесообразность их применения зависит от степени осознания их изначального предназначения.
P.S.
Мартышка к старости слаба глазами стала;
А у людей она слыхала,
Что это зло еще не так большой руки:
Лишь стоит завести Очки.
Очков с полдюжины себе она достала;
Вертит Очками так и сяк:
То к темю их прижмет, то их на хвост нанижет,
То их понюхает, то их полижет;
Очки не действуют никак.
«Тьфу пропасть! — говорит она, — и тот дурак,
Кто слушает людских всех врак:
Всё про Очки лишь мне налгали;
А проку на-волос нет в них».
Мартышка тут с досады и с печали
О камень так хватила их,
Что только брызги засверкали.
Автор, кажется, из прошлого века заехал. В 2019 ООП — это про поведение, то есть про интерфейсы к данным. С-но, данные как раз можно представлять как угодно, в отрыве от ООП-структуры приложения.
Объектно-ориентированное программирование — чрезвычайно плохая идея, которая могла возникнуть только в Калифорнии.
Что за бредовая цитата? Почему Калифорния обязательно означает плохую идею? Там родилось и множество хороших.
Существенная часть кода — это рекурсивный обход леса деревьев с преобразованиями поддеревьев. Например для вычисления выражений с константой, разворачивания циклов и рекурсии итд.
Допустим у вас есть N=200 алгоритмов преобразования дерева и M=100 типов узлов. Эти N и M независимы. Каждый из N должен делать специфические действия для каждого из N.
Если вы структурируете код без OOP, у вас универсальная функция обхода дерева + один тип узла Node + N=200 функций для локального преобразования дерева типа:
transformation_1 (Node * & rp)
{
switch (rp -> op)
{
case OP_CONSTANT: // Делай что-то для константы
case OP_PLUS: // Делай что-то для PLUS
…
default: // Ничего или по умолчанию
}
}
transformation_2 (Node * & rp)
…
Если же вы решили сделать иерархию типов узлов, например:
class NodePlus: Node {… }
class NodeConstant: Node {… }
— и при этом сделать все 200 преобразований деревьев виртуальными функциями, то у вас будет N * M = 20000 маленьких виртуальных функций типа:
NodePlus::transormation_1 ()
NodePlus::transormation_2 ()
…
NodeConstant::transormation_1 ()
NodeConstant::transormation_2 ()
…
Как вы будете группировать эти функции по файлам? Группировать по алгоритмам или по классам? Если по алгоритмам, то вы раскидаете один класс по 200 файлам, что просто увеличивает количество набитого вами кода и никак не помогает уменьшить сложность. Если по классам, то оно резко увеличивает сложность, так как теперь, чтобы понять каждый алгоритм, программисту нужно будет просматривать не один, а 100 файлов.
OOP годится для определенных программ, например для GUI. В других программах он приводит к тому, что программисты занимаются не полезной работой, а борьбой за/против OOP, из-за чего получаются непонятные, большие, медленные программы.
Disclaimer: я использую C++ и OOP с 1993 года, и пришел к выводу о неоходимости использовать OOP сдержанно после года через три после начала его использования. Желание наплодить классов и иерархий — это желание либо новичка, либо человека, которые пишет GUI или подобные легко укладывающиеся в классы приложения. Весь софтвер, которые делает сложную работу с графами — just say NO to OOP.
— и при этом сделать все 200 преобразований деревьев виртуальными функциями, то у вас будет N * M = 20000 маленьких виртуальных функций типа:Не путайте, пожалуйста, ООП и «виртуальные функции» — это не одно и то же.
Весь софтвер, которые делает сложную работу с графами — just say NO to OOP.Серьёзно? А нельзя взглянуть на ваш компилятор? Ну чтобы сравнить его с LLVM'ом? Который использует ООП — и очень серьёзно (но не так наивно, как вы описали, с комбинаторным взрывом, конечно).
Код LLVM мне, лично, кажется куда более понятным чем год GCC, к примеру. Хотя, вроде как эти десятиэтажные макросы в GCC и должны упрощать работу с кодом…
Если не трудно, ткните меня в код LLVM с классами для узлов деревьев выражений или чего-нибудь подобного.
то у вас будет N * M = 20000 маленьких виртуальных функций типа:
NodePlus::transformation_1 ()
NodeConstant::transformation_1 ()
Зачем? Почему нельзя сделать отдельный класс, который будет заниматься трансформациями дерева? Single responsibility и все такое.
С проблемой каши из кода, при подходе DFS по синтаксическим нодам со свитчами и процедурами я столкнулся уже при N = 7, и M = 30.
Также, у каждого типа синтаксической ноды есть множество принципиально различных атрибутов, нужных для анализа и принятия решений, что есть жирный, статически типизированный плюс (привет Roslyn).
Один такой визитор будет инкапсулировать один из N алгоритмов для всех M нод. В случае дубляжа кода можно воспользоваться как полиморфизмом так и наследованием.
Визитор это просто способ реализации паттерн матчинга в ООП языках по сути. Он работает только при фиксированной иерархии, иначе ваше VisitXXX начинают разъезжаться.
Ну так оператор switch тоже только с фиксированным набором констант работает.
Матч это и есть крутой свитч, который работает с АДТ. В том же сишарпе он сейчас так и выглядит
switch foo {
case MyTypeA typeA: ...
case MyTypeB typeB: ...
}только обычно он еще позволяет интроиспекцию
match foo {
Ok(Some(Foo {x = 5})) => ...
}Проверит, что объект является Result со значением Ok (выражение посчиталось эксепшна), в котором лежит Option со значением Some (то есть результат выражения не null), в котором лежит структура Foo у которой поле x имеет значение 5.
… И что из этого следует?
У вас аргумент в стиле "а на поверхности солнца температура 6000 градусов". Верно, но отношения никакого не имеет.
Визитор это классическое решение expression problem для случая фиксированной иерархии. То, что матч решает нативно, собственно. В случае динамической иерархии он перестает работать, очевидно: нужно дописать метод VisitNewType и обновить все визиторы.
В данном случае аргумент "а на поверхности солнца температура 6000 градусов" я вижу у вас.
Тут выше комментатор показывал код:
switch (rp -> op)
{
case OP_CONSTANT: // Делай что-то для константы
case OP_PLUS: // Делай что-то для PLUS
…
default: // Ничего или по умолчанию
}и утверждал, что аналог на ООП будет ужасен. Ему ответили про паттерн visitor. Да, разумеется, оба этих решения подходят только для фиксированных иерархий. Да, разумеется, в нормальные языки давно уже завезли match, который тоже подходит только для фиксированной иерархии.
Не понятно только к чему вы это всё пишите.
Да, я выпал из контекста. В данном случае иерархия у нас очевидно фиксированная, и визитор как раз хорошо подходит. Прошу прощения, аналог на ООП тут будет выглядеть нормально.
Ну как-то попытку завести tagless final на джаве я видел тут. Можете глянуть, если интересно.
Ну я же линканул. Вся разница в том, что приходится чутка больше руками писать:
The difference between Haskell and Java is that in Haskell for every pair of a typeclass and a type there can be at most one instance declaration, and once this instance declaration is defined, it remains implicitly in the scope and is passed around automatically by the compiler. In Java, there can be many implementations of a given generic interface instantiated with a given type, and these implementation are entities in the program that have names and have to be passed around explicitly.
В частном случае C#, в пределах одной сборки и без сильных статических гарантий вида "в фазе разрешения имен нам недоступна вся информация о типах" — помогут partial классы и интерфейсы. Фактически, в любой класс можно дописать произвольное число членов из произвольного файла.
С другой стороны Visitor это не только паттерн матчинг но и SRP точка. Как раз та самая логическая группировка процедур обработки узлов.
И в довесок к ништякам — Visitor есть очень удобный интерфейс для использования в DFS. Тоесть отлично разделяются алгоритм обхода дерева и алгоритм преобразования.
Также есть вопрос к процедурному обходу — по читабельности:
В «безвизиторном» варианте обхода дерева с огромной вариативностью алгоритмов, вопрос группировки всех этих процедур встает очень остро, и, по сути, решается внимательностью и совестью разработчика. Это ок — если разраб один. Это очень не ок когда разрабов несколько и у каждого немного свое мнение, а среди них еще и затаился человек-снежинка.
Итого. В данном случае, визитор это:
— SRP
— Читабельность
— Строгая типизация
То есть больше, чем просто паттерн матчинг фиксированной иерархии в одном модуле.
Но спешу успокоить, уже никто не пишет в ооп стиле, потому что не знает что это такое. Например, разработчики базы данных, делают анемичную модель, функции оборачивают командами и называют это ооп. Либо, разработчик, в базовые классы, выделяет общий функционал, опираясь на DRY и тоже это называет ооп. В геймдеве часто используется компонентная система, и это тоже называют ооп.
Так что ооп никто не использует, можно расслабиться и писать тот код, который нужен для текущего проекта.
Об этом говорит Ален Кей — автор идеи ООП. Об этом писал в 80е годы Фредерик Брукс в своей книге МЧМ. Про это написано в Википедии. Есть куча примеров в которых ООП не на классах (а на прототипах и/или компонентах) побеждает на рынке. Но ребята с комплексом утенка упорно не хотят это замечать )
С ООП на классах тоже все нормально можно делать, только многословнее.
Проблема не в классах, а в том, как их проектируют. При этом львиная доля проблем с проектированием — злоупотребление наследованием.
Отказ от него там, где нет "противопоказаний" тоже ни к чему хорошему не приводит.
Тут в целом хорошо работает широко известное в узких кругах правило "Abstract or Final": каждый класс должен быть либо абстрактным, либо финальным. Чтобы его нарушить, нужны очень веские причины.
Когда я об этом правиле узнал, я проанализировал два довольно крупных проекта, над которыми я работал. Везде, где я нашел наследование не от абстрактного класса (такого было очень мало, кстати), это был по сути хак для срезания углов.
Разумеется, это правило не отменяет принципы SOLID, это просто хороший маркер: если возникает необходимость наследоваться не от абстрактного класса, наверняка где-то тут нарушается SRP, LSP или ISP (а обычно все сразу).
Как вы реализуете DOM с его Node, Element, HTMLElement и тд реализующими довольно развесистый API?
Из свежего: есть в предметной области в пределах одного контекста некий набор сущностей физического мира со строго ограниченным количеством типов с большой долей идентичного поведения в ИС и вариантами специфичного. Бизнес использует один термин для всего набора "такие-то сущности", а специфичные варианты прямо разделяет по типам: "такая-то сущность такого-то типа". Была именно иерархия наследования: абстрактная такая-то сущность, пара абстрактных наследников (одушевленные и неодушевленные, главное различие в наличии first/last name у первых и name+description у вторых) и специфичные наследники от последних. Решили переделать через композицию: неабстрактная "такая-то сущность", с полями "тип" и "конкретная сущность", да методами getAs<специфичная сущность>: ?<специфичная сущность>.
Если точнее то в крупных/сложных системах надо уметь делать ООП не только на классах.
Пока вы делаете что то мелкое и простое — можно жить с ООП только на классах.
Но как только система становится достаточно большой, в команде появляется 5-10-50 разработчиков — упор на классы влечет проблемы. Часть описана в этой статье, часть гуглится по фразе «проблема хрупкости базового класса».
Это не значит что надо отказаться от классов. Это значит что надо учить другие ООП методологии: компоненты и прототипы. Там же событийная архитектура. Это существенно прокачивает гибкость. И позволяет упрощать разработку больших систем.
Событийная архитектура прекрасно делается на классах.
Компоненты тоже.
От прототипного, честно говоря, в общем и целом вижу больше вреда, чем пользы, хотя в ряде частных случаев и удобно. (Хотя я, возможно, зря сужу по Javascript и надо посмотреть внимательнее на Self).
В общем, повторюсь — проблема не в классах, а в том, как их проектируют. Спроектировать плохо можно на чем угодно.
Базовый класс? Да можно обойтись вообще только интерфейсами (или pure abstract class-ами) и делегированием, если интуитивно не получается избежать таких проблем.
Зачем прикручивать ооп, к рсубд, если можно сразу использовать оосубд типа OrientDB? :-)
Я не очень понял о чём вы.
Да точно так же, иерархия классов и их экземпляры.
А для чего ещё бд может использоваться?
Так, и какие вы видите проблемы с этим у оосубд?
Так проблема-то в чём? В реляционной базе тоже можно так сделать, нужно лишь суррогатный автоинкрементный ключ добавить.
Или даже можно его не добавлять, просто вообще без PK обойтись. Это будет глупо, но такая возможность есть.
Скажите денормализация? Ответ неверный. Денормализация — это способ оптимизации, когда каждая запись является такой же уникальной и отображает сам факт поступления данных (если таблица для записи) или материализованное представление — если для чтения.
Не может быть в таблице двух записей с одинаковыми первичными ключами. Суррогатные ключи — тоже оптимизация и правильная схема гарантирует, что каждому значению суррогатного ключа соответствует уникальное значение первичного ключа и функционально зависящие от него атрибуты.
Потенциальная возможность сделать какую-нибудь чепуху ещё не является руководством к действию. Кто вам мешает сделать правильную схему-то? Вот ни за что не поверю, что в объектной СУБД нельзя сделать индекс (иначе зачем она вообще нужна?). А если можно сделать индекс, то наверняка можно сделать и уникальный индекс, т.е. ограничение уникальности. После этого вопрос о том, является ли это ограничение первичным ключом, будет просто переливанием из пустого в порожнее.
Кстати, по поводу "использование ее storage engine не по назначению" и "просто замороченный доступ к файлам с данными".
Что делать в ситуации, когда нам требуется этот самый "замороченный доступ к файлам с данными"? Вот буквально, пользователь должен иметь возможность загрузить на сервер вложение, просмотреть их список, и скачать вложение обратно. Где тут искать уникальный первичный ключ? :-)
ООП требует передавать повсюду длинные списки аргументов или непосредственно хранить ссылки на связанные объекты для быстрого доступа к ним.В каком месте ООП требует этого? ООП? Требует? Этого?
Аналогия со стеной — стенки вредны, потому что о них часто ударяются головой, каждый житель дома хоть раз да ударялся о стену, предлагаю отказаться от стен.
Аналогия с пистолетом — слишком легко выстрелить себе в ногу, по статистике пистолеты чаще вредят, чем приносят пользу, следует отказаться от оружия.
Аналогия с ООП — хреновое понимание данных, попытка наспех провести границы объектов где ни попадя, активное применение антипаттенов и прочие грехи приводят к неприятным последствиям, поэтому предлагаю отказаться от ООП в пользу чего-нибудь другого.
Если мышление человека оперирует абстракциями с ярлыками терминов, то от объектной ориентации полностью отказаться не получится. Любой инструмент может помогать и мешать — выбирайте инструмент под задачу.
А причина одна —
Код пишется под задачу. ООП позволяет быстро и прозрачно прикручивать фичи. Это важно на реальных проектах, поэтому ООП популярно. Вне контекста задачи споры о том, хорошо ООП или плохо — как абстрактное сравнение эффективности молотка, и, например, зубила.
Хотя я сам в последнее время все больше становлюсь апологетом ФП, не могу не высказаться за пользу ООП и статьи, которые показывают, как на ООПэ проектировать итеративно без проблем.
И так у нас есть Monster и Player ну и допустим, что мы разрабатываем какую-то мультиплеерную игру. В данном кейсе будет куда рациональнее использовать ООП, т.к. у нас есть бесчисленное множество игроков и монстров и куда удобнее читать их параметры через monster.getHealth(), player.getCurrentWeapon() и т.д. В противном случае все это выглядело бы в виде одного большого костыля.
По поводу введения новых фишек, которые могут «взорвать» весь уже написанный код. Тут проблема только в том, что многие люди не умеют писать код так, чтобы к нему можно было что-то добавить, а пишут прямолинейно только то, что им дали в ТЗ. И самое просто решение данного кейса — научить людей вариативности и гибкой разработке.
Злоупотребление ООП действительно иногда приводит к крайне тяжело поддерживаемому спагетти коду. Чаще всего это происходит, когда объединяют объкты данных с объектами ответственными за их обработку. Иначе говоря, пихают всю обработку прямо в объекты данных. А если еще и визуальные представления пихают прямо внутрь этих же объектов данных — то вообще туши свет.
Данные безусловно лучше отделять от объектов обработчиков и тем более от объектов представлений этих данных. Но к этому итак приходят почти все в больших и серьезных проектах.
Но вот отказ от ООП как такового — это уже слишком.
Хорошо еще конечно, когда язык так же позволяет делать что-то обычными процедурными подходами в одном модуле/юните, а не извращаться с созданием абсолютно ненужных в данном случае static классов.
Собственно ООП заключается в объединении данных с объектами, ответственными за их обработку.
Объекты данных нужно отделять от объектов обработки. Собственно так в больших проектах чаще всего и и делается.
А объекты обработки используется как своего рода прокси интерфейс-оболочка поверх выбранных конкретных данных.
Есть некоторые случаи, когда в объектах нужны только данные, ну и геттеры/сеттеры (и то сеттеры под вопросом), но они должны возникать только после после ответа на вопрос "а действительно ли нельзя тут же эти данные и обрабатывать?". То есть именно если нельзя, ну или очень сложно обработать данные в пределах объекта, то тогда выносится обработка вовне. И то не факт, что в отдельный обработчик, а не в другой объект со своим состоянием.
Да, но если все данные и хранить в тех же объектах, которые их обрабатывают и тем более представляют на экране, то тогда на практике это и приводит к жуткому спагетти-коду. Автор в этом прав.
Про «представляют на экране» ничего не было. Модели на чтение/запись можно разделять.
Не делайте классы содержащие по 20 параметров если все эти параметры не нужны для каждой операции и не будет у вас «спагетти кода», а если что и приводит к «спагетти коду», так это неумение в coupling/cohesion/разделение зон ответственности от разработчиков.
Ждал его повторного рассмотрения в конце без ООП. Но нет (. Жаль, так было бы нагляднее.
Player{
hit(){
_context.hit(this);
}
}
И уже контекст решает с кого и что снять. а Player и Monster не более чем контейнеры, а битва это «бизнес логика» игры.
Зачем вам классы для объединения данных если вы не помните что такое struct, union и enum в обычном С?
Чем быстрее вы забудете ООП, тем лучше для вас и ваших программ