Освещение растений белыми светодиодами — о КПД и экономической эффективности
7 min
Recovery Mode
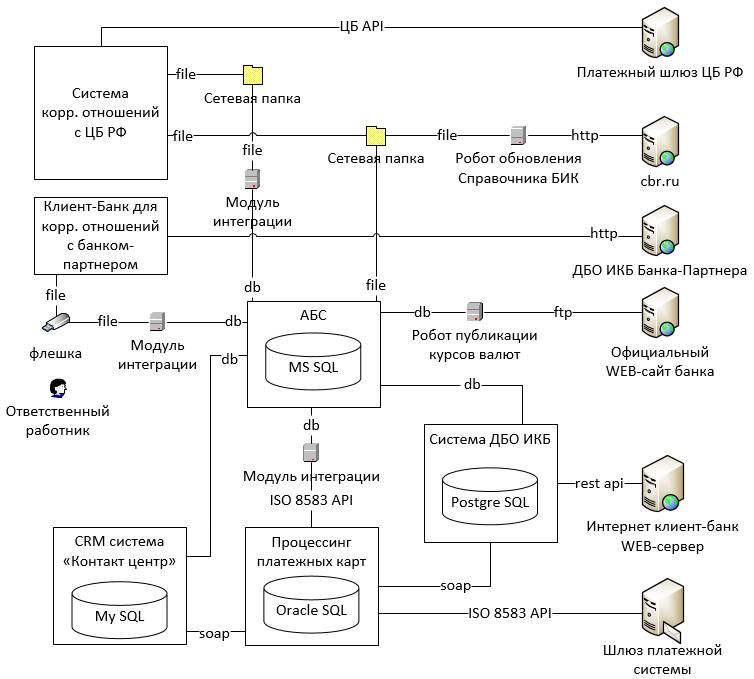
После написания предыдущей статьи у меня самого остался не до конца решенным вопрос — а что же конкретно выгоднее купить и на сколько можно выиграть в дальней и ближней перспективе. Плюс остались некоторые неопределенности по эффективности светодиодов. А вопрос побуждает к поиску ответа на него, поэтому я продолжил разрабатывать это направление. Не скажу что получился материал на полноценную статью, но в качестве дополнения к предыдущей информация содержит существенно важные данные будет полезна.




 Преподаватели готовы разделить с вами все таинства музыкальной теории но не раньше, чем вы научитесь читать эти закорючки самостоятельно.
Преподаватели готовы разделить с вами все таинства музыкальной теории но не раньше, чем вы научитесь читать эти закорючки самостоятельно.