Добрый день, Хабрахабр. Это еще один пост в рамках моей программы по обогащению базы данных крупнейшего IT-ресурса информацией по алгоритмам и структурам данных. Как показывает практика, этой информации многим не хватает, а необходимость встречается в самых разнообразных сферах программистской жизни.
Я продолжаю преимущественно выбирать те алгоритмы/структуры, которые легко понимаются и для которых не требуется много кода — а вот практическое значение сложно недооценить. В прошлый раз это было
декартово дерево. В этот раз —
система непересекающихся множеств. Она же известна под названиями
disjoint set union (DSU) или
Union-Find.
Условие
Поставим перед собой следующую задачу. Пускай мы оперируем элементами
N видов (для простоты, здесь и далее — числами от 0 до N-1). Некоторые группы чисел объединены в множества. Также мы можем добавить в структуру новый элемент, он тем самым образует множество размера 1 из самого себя. И наконец, периодически некоторые два множества нам потребуется сливать в одно.
Формализируем задачу: создать
быструю структуру, которая поддерживает следующие операции:
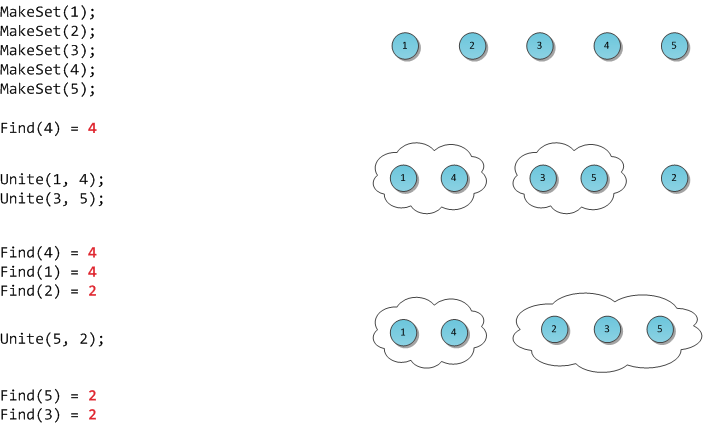
MakeSet(X) — внести в структуру новый элемент X, создать для него множество размера 1 из самого себя.
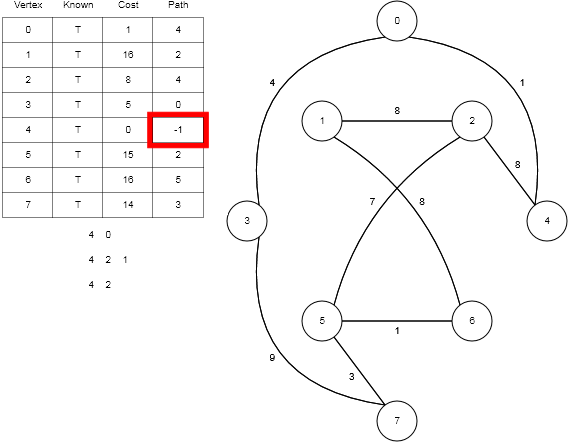
Find(X) — возвратить
идентификатор множества, которому принадлежит элемент X. В качестве идентификатора мы будем выбирать один элемент из этого множества —
представителя множества. Гарантируется, что для одного и того же множества представитель будет возвращаться один и тот же, иначе невозможно будет работать со структурой: не будет корректной даже проверка принадлежности двух элементов одному множеству
if (Find(X) == Find(Y)).
Unite(X, Y) — объединить два множества, в которых лежат элементы X и Y, в одно новое.
На рисунке я продемонстрирую работу такой гипотетической структуры.

 Фреймворк Sencha Ext JS стал индустриальным стандартом для разработки корпоративных веб-приложений благодаря обширной библиотеке виджетов, мощной поддержке работы с данными и богатым набором инструментов разработки. Со дня релиза Ext JS 1.0 в 2007 году в нашей отрасли многое изменилось, а веб-приложения несомненно стали больше и сложнее, чем когда-либо ранее.
Фреймворк Sencha Ext JS стал индустриальным стандартом для разработки корпоративных веб-приложений благодаря обширной библиотеке виджетов, мощной поддержке работы с данными и богатым набором инструментов разработки. Со дня релиза Ext JS 1.0 в 2007 году в нашей отрасли многое изменилось, а веб-приложения несомненно стали больше и сложнее, чем когда-либо ранее.




 Несколько человек спрашивали меня, в контексте моего предыдущего поста о значимых типах, почему же всё-таки значимые типы располагаются на стеке, а ссылочные нет.
Несколько человек спрашивали меня, в контексте моего предыдущего поста о значимых типах, почему же всё-таки значимые типы располагаются на стеке, а ссылочные нет. Не знаете чем заняться в майские праздники? Решение есть!
Не знаете чем заняться в майские праздники? Решение есть!

 Когда я был студентом, у меня сложилась иллюзия, что программировать я уже умею, а Computer Science — это просто. Действительно, ведь я создавал сайты с динамическим контентом, писал игры, получал призы на олимпиадах и без проблем сдавал экзамены в университете. Однако это было лишь хобби, а я был любителем. Чтобы начать путь профессионала, я пошёл в школу Яндекса.
Когда я был студентом, у меня сложилась иллюзия, что программировать я уже умею, а Computer Science — это просто. Действительно, ведь я создавал сайты с динамическим контентом, писал игры, получал призы на олимпиадах и без проблем сдавал экзамены в университете. Однако это было лишь хобби, а я был любителем. Чтобы начать путь профессионала, я пошёл в школу Яндекса.