Оригинал: www.infoq.com/articles/atdd-from-the-trenches
Если вы когда-нибудь бывали в такой ситуации:

Тогда эта статья для вас — конкретный пример того, как начать разработку через приемочные тесты (Acceptance-test driven development) в действующих проектах с легаси кодом. В ней описан один из способов решения проблемы технического долга.
Это пример из реального проекта, со всеми изъянами и недостатками, а не отполированное упражнение из книги. Так что надевайте свои берцы. Я буду использовать Java и JUnit, без всяких модных сторонних библиотек (которыми, как правило, злоупотребляют).
Предупреждение: Я не утверждаю, что это единственный Правильный Путь, существует много других “стилей” ATDD. Так же в этой статье не так много чего-то нового и инновационного, здесь просто описаны хорошо себя зарекомендовавшие подходы и опыт из первых рук.
ATDD с передовой
Разработка через приемочное тестирование для начинающих
Если вы когда-нибудь бывали в такой ситуации:
Тогда эта статья для вас — конкретный пример того, как начать разработку через приемочные тесты (Acceptance-test driven development) в действующих проектах с легаси кодом. В ней описан один из способов решения проблемы технического долга.
Это пример из реального проекта, со всеми изъянами и недостатками, а не отполированное упражнение из книги. Так что надевайте свои берцы. Я буду использовать Java и JUnit, без всяких модных сторонних библиотек (которыми, как правило, злоупотребляют).
Предупреждение: Я не утверждаю, что это единственный Правильный Путь, существует много других “стилей” ATDD. Так же в этой статье не так много чего-то нового и инновационного, здесь просто описаны хорошо себя зарекомендовавшие подходы и опыт из первых рук.







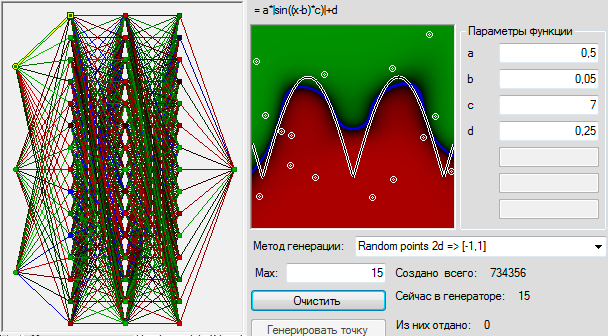 В последнее время на Хабре появилось множество статей о нейронных сетях. Из них очень интересными показались статьи о Перцептроне Розенблатта:
В последнее время на Хабре появилось множество статей о нейронных сетях. Из них очень интересными показались статьи о Перцептроне Розенблатта:  На тему «использование MongoDB вместо memcached» гуглится немало историй успеха. Такое ощущение, что есть широкий класс задач, для которых идея работает неплохо: прежде всего это проекты, где интенсивно используется
На тему «использование MongoDB вместо memcached» гуглится немало историй успеха. Такое ощущение, что есть широкий класс задач, для которых идея работает неплохо: прежде всего это проекты, где интенсивно используется