В конце февраля вышла шестая версия платформы для мониторинга Grafana. В материале мы расскажем подробнее об особенностях этого релиза и новых возможностях инструмента.


User



В предыдущем посте мы масштабировали набор реплик MongoDB и познакомились со StatefulSet. Сейчас мы займемся оркестрацией кластера высокой доступности Elasticsearch (с другими мастер-нодами, нодами данных и клиентскими нодами) и задействуем ES-HQ и Kibana.
Как поднять High-Availability Kubernetes кластер и не взорвать мозг? Использовать Kubespray, конечно же.
Kubespray — это набор Ansible ролей для установки и конфигурации системы оркестрации контейнерами Kubernetes.
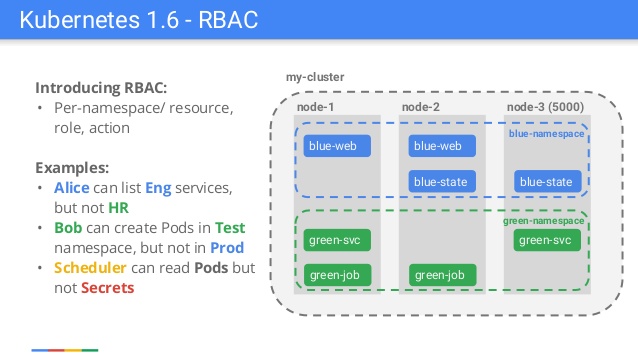
Kubernetes является проектом с открытым исходным кодом, предназначенным для управления кластером контейнеров Linux как единой системой. Kubernetes управляет и запускает контейнеры на большом количестве хостов, а так же обеспечивает совместное размещение и репликацию большого количества контейнеров.
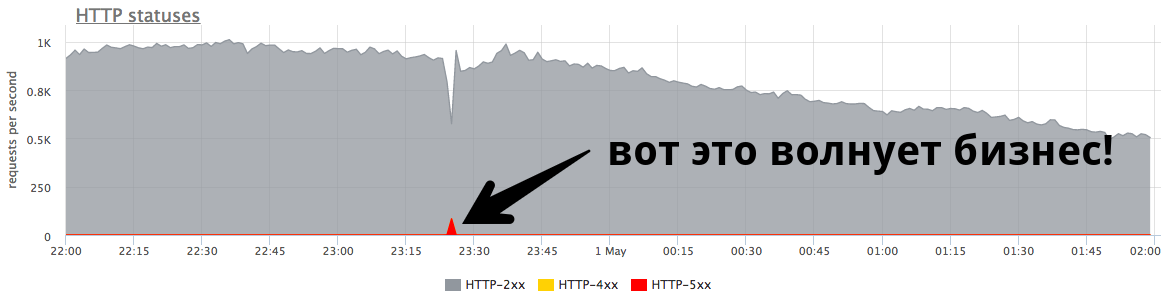
Осторожно, под катом 4 скриншота elasticsearch и 9 скриншотов prometheus!
В этой статье описывается возможность/идея/концепт изменения глобальных настроек на локальных серверах команд в большой инфраструктуре используя Gitlab CI и Ansible.
Допустим у вас имеются 20 команд разработчиков и 1 команда админов/DevOps. Как менять на всех серверах пароли админов? Как добавить корневой сертификат Предприятия на все сервера? И т.д.
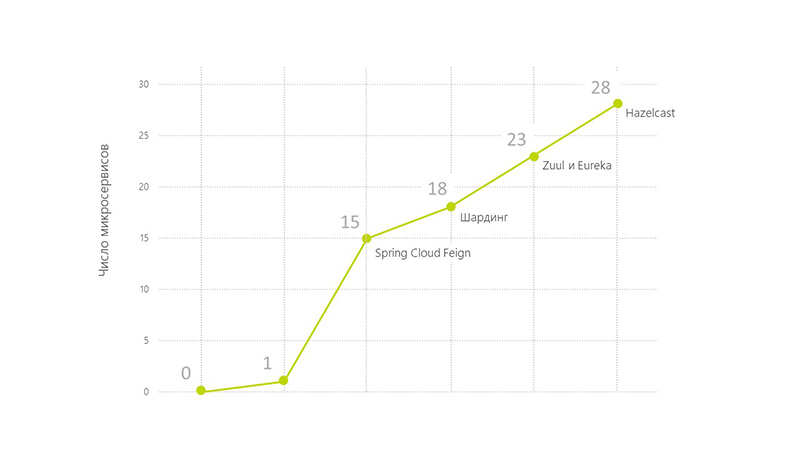
helm init + helm install больше не работал. Внезапно нам потребовалось добавлять «странные» элементы вроде ServiceAccounts или RoleBindings ещё до того, как разворачивать чарт с WordPress или Redis (подробнее об этом см. в инструкции).


Когда мы были детьми, мы многого не понимали, что на данный момент является абсолютно очевидным. "Почему я не могу есть одни конфеты? Почему бутерброды — не еда, я же это ем? Почему я не могу спать с хомяком? Зачем чистить зубы каждый день, да еще целых два раза?!" Действительно, зачем? Но будучи взрослыми, зрелыми людьми, мы не задаемся подобными вопросами.
Похожая ситуация происходит и в мире IT (возможно, это касается любой профессиональной деятельности). Многих вещей на начальных стадиях мы можем не понимать. "Зачем, да и вообще кому нужны всякие Symfony, если есть WordPress? Зачем тратить время на автоматическое тестирование, если и так все работает? Git? Linux? SOLID, DRY, DDD, TDD? Что за страшные слова?". Новичкам сложно понять, зачем нужно так много всего. Осознание приходит со временем и вскоре такие вещи становятся не только понятными, но и очевидными.
Хочу рассказать свою историю того, как я дорос до Docker и что этому поспособствовало.

/home повреждены или дистрибутив не поддерживает директивы cloud-init.