Представляем вам завершающую статью из цикла по Deep Learning, в которой отражены итоги работы по обучению ГСНС для изображений из определенных областей на примере распознавания и тегирования элементов одежды. Предыдущие части вы найдете под катом.


User
Каждый из нас хоть раз выступал перед большой аудиторией, многие делают это постоянно. У всех из нас есть свои страхи перед выступлением и, конечно, же лучшие практики. Ниже вы узнаете, как взаимодействовать с аудиторией в интерактивном режиме.

Все готово, чтобы рассказать Хабр аудитории о применении FPGA в сфере научных высокопроизводительных вычислений. И о том, как на данной задаче надо удалось значительно обскакать GPU (Nvidia K40) не только в метрике производительность на ватт, но и просто с точки зрения скорости вычисления. В качестве FPGA платформы использовался кристалл Xilinx Virtex-7 2000t, подключенный по PCIe к хост компьютеру. Для создания аппаратного вычислительного ядра использовался язык C++ (Vivado HLS).
Под катом текст нашей оригинальной статьи. Там, как обычно бывает, сначала идет долгое описание зачем это все надо и модели, если нет желания это читать, то можно переходить сразу к реализации, а модель посмотреть потом при необходимости. С другой стороны без хотя бы беглого ознакомления с моделью читатель не сможет получить впечатление о том, какие сложные вычисления можно реализовать на FPGA.


Когда речь заходит про машинное обучение, обычно подразумевают большие объемы данных — миллионы или даже миллиарды транзакций, из которых надо сделать сложный вывод о поведении, интересах или текущем cостоянии пользователя, покупателя или какого-нибудь аппарата (робота, автомобиля, дрона или станка).
Однако в жизни обычного аналитика самой обычной компании много данных встречается нечасто. Скорее даже наоборот — у вас будет мало или очень мало данных — буквально десятки или сотни записей. Но анализ все же нужно провести. Причем не какой попало анализ, а качественный и достоверный.
Зачастую ситуация усугубляется еще и тем, что вы без труда можете нагенерить для каждой записи много признаков (чаще всего добавляют полиномы, разницу с предыдущим значением и значением за прошлый год, one-hot-encoding для категориальных признаков и т.п.). Вот только совсем нелегко разобраться, какие из них действительно полезны, а какие только усложняют модель и увеличивают ошибки вашего прозноза.
Для этого вы можете воспользоваться методами байесовой статистики, например, Automatic Relevance Determination.



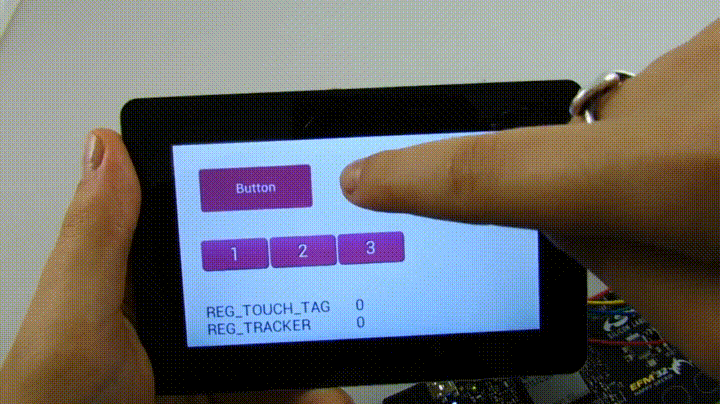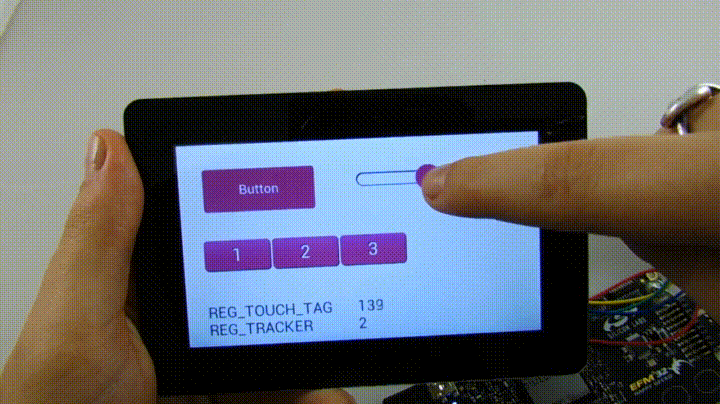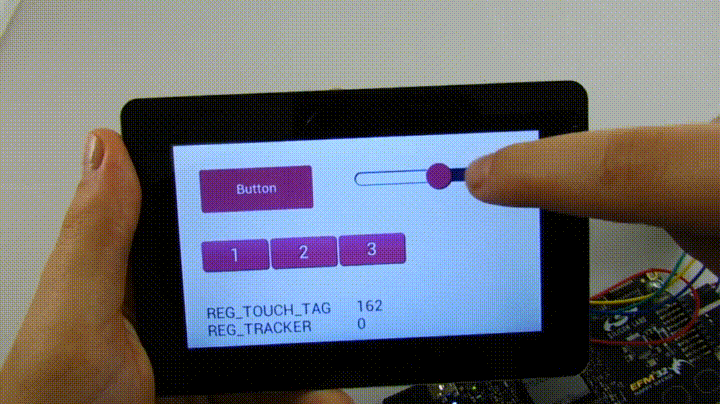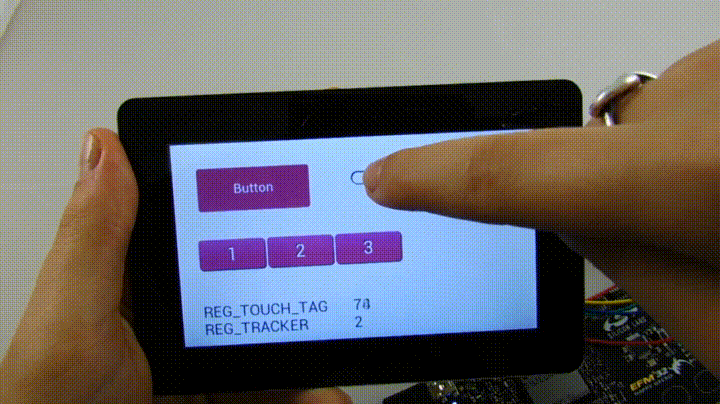
Продолжу обещанный рассказ о том, как можно применять полученную модель на практике, заодно попытаюсь более подробно раскрыть тему эксклюзивности TMVA.
Допустим, Вы работаете в проекте, требующем максимального быстродействия системы (геймдев, картографический сервис или же данные с коллайдера), тогда очевидно, что Ваш код написан на языке, который предельно близок к железу — C/C++. И однажды возникает необходимость добавить к сервису какую-то математику в зависимости от потребностей проекта. Обычно взгляд падает на змеиный язык, который имеет множество удобных математических библиотек для прототипирования идей, но при этом бесполезном в работе с действительно большим объёмом данных и поедающем словно удав все ресурсы машины.

Проект TensorFlow масштабнее, чем вам может показаться. Тот факт, что это библиотека для глубинного обучения, и его связь с Гуглом помогли проекту TensorFlow привлечь много внимания. Но если забыть про ажиотаж, некоторые его уникальные детали заслуживают более глубокого изучения:
Все это круто, но TensorFlow может быть довольно сложным в понимании, особенно для того, кто только знакомится с машинным обучением.
Как работает TensorFlow? Давайте попробуем разобраться, посмотреть и понять, как работает каждая часть. Мы изучим граф движения данных, который определяет вычисления, через которые предстоит пройти вашим данным, поймем, как тренировать модели градиентным спуском с помощью TensorFlow, и как TensorBoard визуализирует работу с TensorFlow. Наши примеры не помогут решать настоящие проблемы машинного обучения промышленного уровня, но они помогут понять компоненты, которые лежат в основе всего, что создано на TensorFlow, в том числе того, что вы напишите в будущем!
Представляю вашему вниманию перевод своей статьи Amazon software engineer interview, изначально опубликованной на английском на sobit.me.

Не так давно со мной связался технический рекрутер из Amazon. Компания организовывала трехдневное онсайт собеседование по найму программистов в их берлинский офис.
Весь процесс, начиная с того, как со мной связались, и заканчивая подписью контракта, занял около двух месяцев. Я хотел бы поделиться опытом, как все прошло, и что, на мой взгляд, помогло мне получить работу.
Если я не упомянул чего-то важного в статье, спрашивайте в комментариях. Постараюсь ответить максимально подробно.

В этой статье мы продолжим рассказывать о похождениях нашей программы распознавания паспорта: теперь паспорт отправится на Эльбрус!

Итак, что же мы знаем про архитектуру Эльбрус?
Эльбрус — высокопроизводительная и энергоэффективная архитектура процессоров, отличающаяся высокой безопасностью и надежностью. Современные процессоры архитектуры Эльбрус могут применяться в качестве серверов, настольных компьютеров и даже встраиваемых вычислителей. Они способны удовлетворить повышенным требованиям по информационной безопасности, рабочему диапазону температур и длительности жизненного цикла продукции. Процессоры архитектуры Эльбрус, как говорят нам публикации МЦСТ [1, 2], предназначены для решения задач обработки сигналов, математического моделирования, научных расчетов, а также других задач с повышенными требованиями к вычислительной мощности.
Мы в Smart Engines попробовали убедиться, правда ли производительности Эльбруса достаточно, чтобы реализовать распознавание паспорта без значительных потерь в скорости работы.

D3.js (или просто D3) — это JavaScript-библиотека для обработки и визуализации данных с невероятно огромными возможностями. Я, когда впервые узнал про нее, наверное, потратил не менее двух часов, просто просматривая примеры визуализации данных, созданных на D3. И конечно, когда мне самому понадобилось строить графики для небольшого внутреннего сайта на нашем предприятии, первым делом вспомнил про D3 и с мыслью, что “сейчас я всех удивлю крутейшей визуализацией”, взялся изучать исходники примеров…