В процессе работы над диалоговой системой (http://habrahabr.ru/post/235763/) мы столкнулись с непреодолимой, на первый взгляд, проблемой – в реальных, боевых условиях работы, производительность системы ASR оказывалась значительно ниже ожидаемой. Одним из компонентов, сказывающимся на производительности, неизменно оказывался шум на заднем фоне, принимающий самые разнообразные формы. Особенно неприятными для ASR в наших экспериментах были трудно-нейтрализуемые шум городской улицы и шум массовых скоплений людей.
Стало ясно, что проблему придется решить, или реальной ценности от голосовой системы просто не будет.
Стало ясно, что проблему придется решить, или реальной ценности от голосовой системы просто не будет.



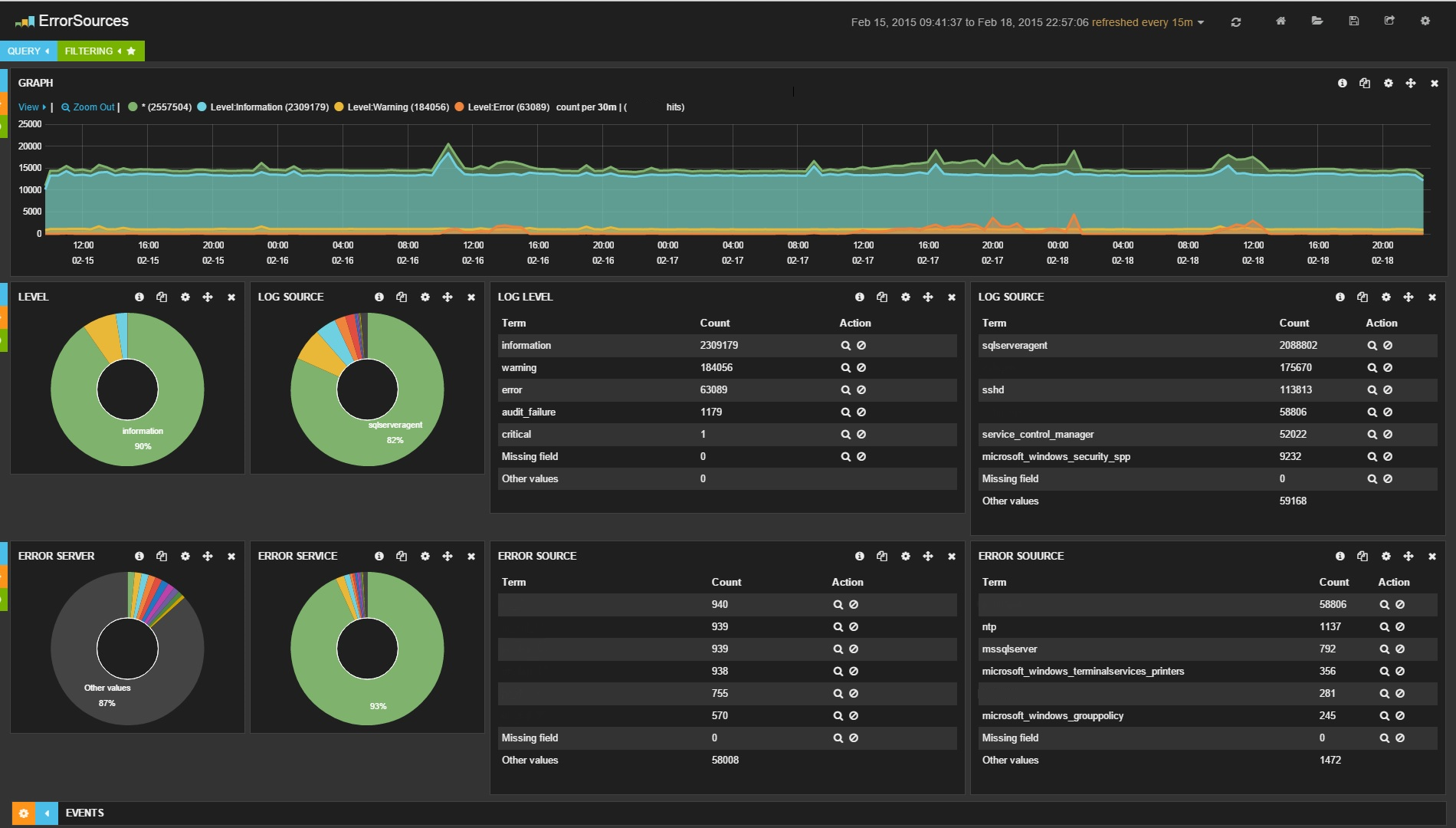

 Очередной компьютер с жалобой на рекламу в браузере — как обычно по словам пользователя ничего не запускалось, но факт налицо — реклама вылазит почти на каждом сайте из всех щелей и подменяются поисковые запросы. Обычно большинство подобных проблем решаются сразу же за пять минут с помощью
Очередной компьютер с жалобой на рекламу в браузере — как обычно по словам пользователя ничего не запускалось, но факт налицо — реклама вылазит почти на каждом сайте из всех щелей и подменяются поисковые запросы. Обычно большинство подобных проблем решаются сразу же за пять минут с помощью