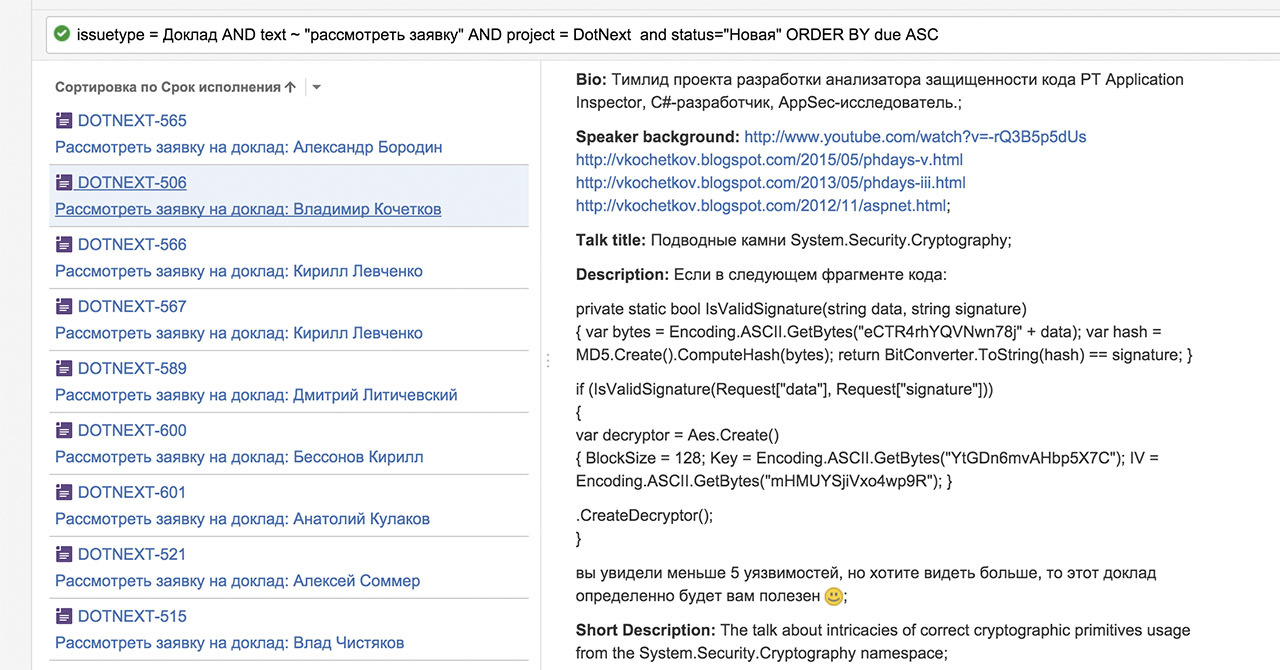
Мы уже ни раз приводили полезные руководства и подборки источников для разработчиков. На этот раз мы решили продолжить тему контейнеров, которую мы затрагивали ранее, и рассказать о подборке тематических ресурсов на GitHub.


User



 Недавно выдалась минутка посмотреть почему старый тестовый сервер безбожно тормозил… К нему я не имел никакого отношения, но меня одолевал спортивный интерес разобраться, что с ним не так.
Недавно выдалась минутка посмотреть почему старый тестовый сервер безбожно тормозил… К нему я не имел никакого отношения, но меня одолевал спортивный интерес разобраться, что с ним не так.D:\SQL_2012\SYSTEM\MSDBData.mdf
D:\SQL_2012\SYSTEM\MSDBLog.ldf
SELECT name, size = size * 8. / 1024, space_used = FILEPROPERTY(name, 'SpaceUsed') * 8. / 1024
FROM sys.database_files
name size space_used
------------ -------------- ---------------
MSDBData 42626.000000 42410.374395
MSDBLog 459.125000 6.859375

 Совсем недавно гитлаб героически выкатил версию 8.0 своего конкурента гитхабу. Из интересного — движок continuous integration теперь встроен в платформу, а значит доступен в качестве бесплатного сервиса для всех желающих на gitlab.com. Совместно с бесплатными приватными репозиториями это делает облачный сервис гитлаб не только удобным местом для хранения кода, но также тестирования и деплоя. О последнем я и расскажу под катом.
Совсем недавно гитлаб героически выкатил версию 8.0 своего конкурента гитхабу. Из интересного — движок continuous integration теперь встроен в платформу, а значит доступен в качестве бесплатного сервиса для всех желающих на gitlab.com. Совместно с бесплатными приватными репозиториями это делает облачный сервис гитлаб не только удобным местом для хранения кода, но также тестирования и деплоя. О последнем я и расскажу под катом.Тестирование и анализ производительности — тема, которую хотелось бы обсуждать побольше. Мы начинаем публикацию перевода руководства от небезызвестной команды Patterns&Practices о том, с чем нужно есть ключевые показатели производительности. За перевод — спасибо Игорю Щегловитову из Лаборатории Касперского, нашему бессменному автору материалов про тестирование. Остальные наши статьи по теме тестирования можно найти по тегу mstesting



[@tsafin — Обладателя премии Тьюринга Майкла Стоунбрейкера представлять не надо, он и его студенты из Беркли и MIT создали, по ощущениям, большую часть реляционных и нереляционных баз данных за последние пару десятилетий. Ingres и Postgres, C-Store и Vertica, H-Store и VoltDB – вот лишь малая часть проектов и фирм, на который Майкл и его студенты повлияли напрямую, а ведь еще есть множество форков и деривативов…
Т.о. когда он критикует что-то, будь то NoSQL или Hadoop, то индустрии стоит, как минимум, прислушаться, а лучше попытаться измениться.
Мне показалось интересной его точка зрения на Hadoop, высказанная в статьях 2012 и 2014 года, и было интересно проследить развитие точки зрения «классика» за такой короткий промежуток времени.
Первую статью «Possible Hadoop Trajectories», опубликованную в «Comunications of ACM» http://cacm.acm.org/blogs/blog-cacm/149074-possible-hadoop-trajectories/fulltext, Стоунбрейкер написал в мае 2012 года в соавторстве с Джереми Кепнером (Jeremy Kepner), который в тот момент работал как старший технический персонал в MIT, и как исследователь в MIT Mathematics Department и MIT Computer Science and AI Lab. Эта статья, написанная в соавторстве, кажется более дерзкой и задорной, по сравнению со второй, написанной уже им самим двумя годами позже (да и, чего уж там, первая статья написана IMHO в лучшем стиле), но я публикую их в связке, т.к. контекст за прошедшие пару лет сильно изменился, и было бы нечестно по отношению к экосистеме Hadoop/HDFS оставлять это незамеченным.