
Библиотека dplyr в R позволяет манипулировать данными, проводить фильтрацию, выборку, сортировку, группировку данных и многое другое.
В этой статье как раз и рассмотрим эту библиотеку.

Аналитик
Библиотека dplyr в R позволяет манипулировать данными, проводить фильтрацию, выборку, сортировку, группировку данных и многое другое.
В этой статье как раз и рассмотрим эту библиотеку.
Всем привет!
--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------

В Отусе я прошла курс ML Advanced и открыла для себя интересные темы, связанные с анализом временных рядов, а именно, их сегментацию и кластеризацию. Я решила позаимствовать полученные знания для своей дипломной университетской работы по ивент-анализу социальных явлений и событий и описать часть этого исследования в данной статье.
Шаг 1. Сбор данных
В качестве источника данных я взяла информационно-новостной ресурс Лента.ру, так как с него легко парсить данные, новости разнообразны и пополняются в большом объеме ежедневно. Для теста я спарсила новости за последний год (март 2023 – март 2024) с помощью питоновских BeautifulSoup и requests.
В коде происходит процедура сбора заголовка, даты и тематики новостей:
В последнее время на хабре стали появляться статьи, начинающиеся с рассказов про свободное время на самоизоляции и, как итог, появившихся троллейбусов из буханки. Возможно, администрации стоит задуматься о добавлении нового хаба — Самоизоляция..
Вот и у меня появилось свободное время, которое я посвятил анализу своих сделок в Тинькофф Инвестициях. Есть 2 типа людей: одни прекрасно строят многомерные массивы у себя в голове, пробегаясь по ним for-циклом в IPython Notebook, другим же нравится "щупать" цифры, раскладывая их по полочкам в Excel. Себя я отношу ко второй категории, поэтому все свои сделки аккуратно заносил в Google Sheets.
Под катом я расскажу, как автоматизировал свою рутину при помощи Google Apps Script и API от Тинькофф Инвестиций.

Ну что теперь будем писать про VPN вот так?
Кстати, в Китае вместо слова VPN вы часто можете встретить «Science Online»(科学上网), «ladder»(梯子), или «Internet accelerator»(上网加速器), все это обозначает VPN. В России, кажется еще все не так плохо, но это не точно. С первого марта писать о VPN на русскоязычных площадках нельзя, наказание для площадок — блокировка на территории России. При этом считаются как новые статьи, так и статьи, опубликованные до вступления в силу приказа о запрете. В скором времени, крупные ресурсы будут блокировать любую информацию о VPN, поэтому мы настоятельно советуем подписываться на телеграм каналы разных VPN, в том числе на наш. Мы не знаем сколько еще статей нам отведено на Хабре, и как хабр дальше будет показывать статьи со словом VPN в разных странах.
А теперь о хорошем.
Самый ожидаемый нашими пользователями бесплатный VPN AmneziaFree v.2 c защитой от блокировок наконец‑то готов. Должны признаться, последнее время мы много работали над self‑hosted приложением AmneziaVPN, а так же над протоколом AmneziaWG (или по простому — AWG, его мы используем в бесплатном VPN), поэтому работа над проектом AmneziaFree v.2 немного затянулась. В любом случае, мы очень рады, что наконец можем пригласить Вас присоединиться к числу пользователей нашего бесплатного сервиса. Все так же, как и раньше, без регистрации, рекламы и ограничении по сроку работы.
Бесплатный VPN AmneziaFree v.2, можно использовать только для популярных недоступных на территории России сайтов (не будем их перечислять, вы и сами их знаете), список достаточно большой, поэтому, скорее всего, то что вам надо в нем есть. При этом, не заблокированные в России сайты, будут открываться напрямую, без VPN. То есть напрямую с Вашего IP‑адреса.

Упаковка интервалов — это классическая задача SQL, которая подразумевает переупаковку групп пересекающихся интервалов в соответствующие им непрерывные интервалы. В математике интервал — это подмножество всех значений данного типа, например целых чисел, между двумя некоторым разными значениями. В базах данных интервалы могут проявляться в виде интервалов даты и времени, представляющие такие вещи, как сеансы, периоды назначения, периоды госпитализации, расписания или числовых интервалов, представляющие такие вещи, как диапазоны мильных столбов на дороге, диапазоны температур и т.д.

Когда люди задумываются о профессии data scientist-а они в первую очередь вспоминают нейронные сети, которые создают красивые картинки или ведут с человеком псевдоосмысленные диалоги. Существует огромное количество материалов посвященных такого рода моделям, и они безусловно крайне интересны любому человеку, увлеченному анализом данных. Тем не менее, фактически только небольшая часть data scientist-ов занимается подобными моделями, поскольку внедрение их не может в большинстве случаев принести существенной прибыли, а data scientist это достаточно высокооплачиваемая профессия. При этом существенная часть специалистов работает в банковской сфере, основными моделями которой (порядка 80-90% от общего числа моделей) являются модели PD (probability of default), отвечающие на фундаментальный вопрос банков: каковая вероятность того, что заемщик не вернет кредит.
Информации по данным моделям, обзорных статей, описания подводных камней и т.п. достаточно мало и начинающий специалист может столкнуться с настоящим информационным голодом и даже провалить собеседование из-за незнания элементарной терминологии. Именно этот информационный пробел мне хотелось бы заполнить данной статьей. За время работы в банковской сфере мне удалось поучаствовать в разработке нескольких десятков моделей данного класса, и я хотел бы сосредоточится не на конкретной технике моделирования (она может быть разной в каждом конкретном случае), а на практических аспектах разработки и подводных камнях, которые удивили меня в свое время.

Приветствую!
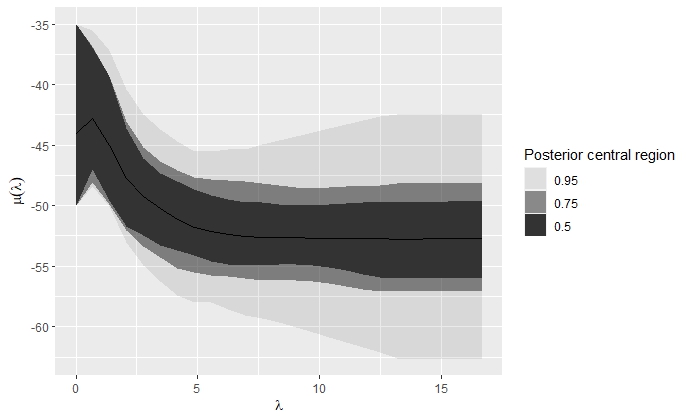
Stan - это библиотека на C++, предназначенная для байесовского моделирования и вывода. Она использует сэмплер NUTS, чтобы создавать апостериорные симуляции модели, основываясь на заданных пользователем моделях и данных. Так же Stan может использовать алгоритм оптимизации LBFGS для максимизации целевой функции, к примеру как логарифмическое правдоподобие.
Для облегчения работы с Stan из языка программирования R доступен пакет rstan, который предоставляет интерфейс R для Stan.
Сегодня мы и рассмотрим этот пакет.

Привет, Хабр!
Сегодня мы поговорим о временных рядах, и как мы можем работать с ними, используя ЯП R. Временные ряды позволяют понять динамику процессов, изменяющихся со временем, и предсказывать тенденции.
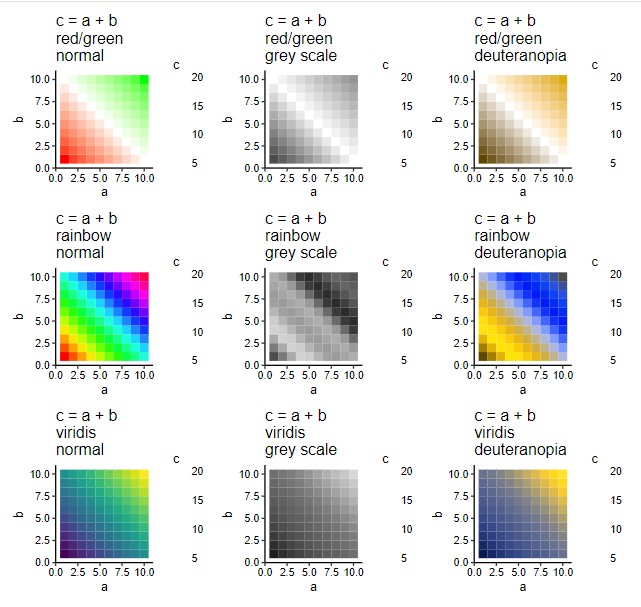
Scripts/ на Github есть файлы .Rmd, генерирующие показанные ниже графики. Для их работы требуются R, RStudio и пакет rmarkdown.
Привет, Habr!
Меня зовут Остапенко Настя, я лидирую направление BI в компании Axenix. Год назад мы выпустили статью с большим обзором Российского рынка BI. На этот раз мы проведем сравнение трех популярных Open-Source BI-платформ: Apache Superset, Metabase и относительно нового участника - Yandex Datalens, который совсем недавно стал доступен в качестве Open-Source продукта.

Привет! Меня зовут Аня!
Хабр я читаю уже давно, решила что теперь и у меня есть интересный материал, чтобы с вами поделиться :)
В начале 2023 года начала заниматься Telegram каналами и за 10 месяцев я создала 6 каналов в Telegram, на которые подписано уже более 70 000 подписчиков.
До Telegram я занималась парсингом данных сайтов на VB, созданием сайтов (wordpress, tilda) и бизнес-презентациями. Был даже свой собственный интернет-магазин детских товаров 2 года (опыт был неудачным, тогда еще нельзя было продавать через маркетплейсы ))
Я расскажу вам о своем опыте создания и монетизации Telegram-каналов, об ошибках, которые я допустила в начале своего пути, и постараюсь сформулировать основные принципы и возможности заработка в этой сфере (кстати считаю, что IT -тематика одна из самых перспективных сегодня для создания телеграм-канала)
Меня зовут Валя Борисов, и я — аналитик в команде Ozon. Задача нашей команды — создавать инструменты для мониторинга и анализа скорости.
Наши усилия направлены на то, чтобы в реальном времени следить за тем, как быстро работают наши сервисы и платформа. Благодаря инструментам, которые мы создаём и поддерживаем, команды разработки получают представление о том, как пользователи видят работу нашего сайта или приложения. Мы помогаем выявлять причины деградации скорости и определять узкие места в инфраструктуре.
Наши дашборды играют ключевую роль в предоставлении информации о скорости работы платформы. Вместе с командой аналитиков я занимаюсь созданием и поддержкой этой системы в Grafana. Мы стремимся делать ее не только информативной, но и быстрой, стабильной и удобной для всех пользователей. В этой статье я хочу поделиться методами и приемами, к которым мы пришли в процессе работы.

Хотя сейчас я работаю в ИТ-отрасли, много лет назад я верстал рекламную газету, и с тех пор дизайн – мой профессиональный навык и увлечение за пределами профессии.
Сделать диаграммы привлекательными гораздо проще, чем вы думаете. Получить рекомендации на все случаи жизни не выйдет, но освоить несколько приемов в Excel и узнать азы теории, вы сможете за 10 минут.
Из тридцатилетнего опыта и десятков прочитанных книг я выбрал семь полезных приемов. Их мы и разберем в этой статье в блоге ЛАНИТ.
В заметке рассказывается о функционале достаточно простого пакета familial, реализующего весьма оригинальную идею о проверке статистических гипотез, связанных с семейством центральных параметров. Концепция данного семейства была изначально разработана Питером Хубертом в статье «Robust estimation of a location parameter».

Современный мир насыщен данными, анализ информации становится критически важным инструментом для принятия обоснованных решений. Однако просто иметь данные не достаточно – необходимо извлечь из них ценную информацию. В этом процессе статистические тесты и проверка гипотез играют важнейшую роль. Они позволяют нам сделать выводы на основе данных, опираясь на строгие методы анализа, и тем самым способствуют принятию обоснованных решений.
Статистические тесты – это мощный инструмент, который позволяет провести объективную оценку данных и проверить гипотезы, основанные на этой информации. Они позволяют определить, насколько вероятно, что наблюдаемые различия или закономерности случайны, а не реально существующие в популяции. Статистические тесты позволяют избежать ошибок и предоставляют научно обоснованный подход к анализу данных.

Биом Уиттекера, также известный как метод классификации экосистем, делит экосистемы на поверхности земли на различные типы на основе таких факторов, как географическое распределение и условия окружающей среды.Этот метод классификации был предложен американским экологом Робертом Уиттакером (Robert Whittaker) в 1962 году, целью которого является улучшение понятий и описаний разнообразия и функций экосистем. Уиттакер использует два фактора для классификации биологических сообществ: осадки и температуру.

Меня зовут Игорь Звягин, я профессиональный веб-разработчик, в этой статье я хочу рассказать, как пришел к мнению, что мы живем в компьютерной симуляции, почему это не тревожит и какие интересные возможности это предоставляет.
В этой статье:
Поговорим про эксперимент с двумя щелями (оптимизация вычислений) и этот же эксперимент с отложенными выбором (нарушение причинно-следственных связей, изменение прошлого). Существующие объяснения эффекта наблюдателя способны объяснить лишь первые версии эксперимента, но абсолютно бессильны перед вариацией эксперимента с квантовым ластиком и отложенной обратной связью.
Обсудим квантовую запутанность (оптимизация вычислений).
Поговорим про Парадокс теории вероятностей – игра Пенни. В нашей реальности не существует независимых событий, что может говорить о том, что все случайности созданы благодаря псевдослучайным числам. Приведу код, который вы сможете запустить у себя на компьютере, запросить реальные случайные числа и проверить, насколько предсказательная формула оказалась близка к реальности.
Обсудим возможность существования мультивселенной и параллельных миров.
Также поговорим про эффект Манделы и Ложные воспоминания, что поговорит о том, что прошлое можно менять при определенных условиях.

Как с помощью двух мощных инструментов с открытым исходным кодом можно совместить привычный для пользователей интерфейс, надежность и мощь SQL, гибкость Python и командную работу как в Google Spreadsheet?
В разных областях деятельности приходится строить графики. Построить график на компьютере можно десятками если не сотнями способов. В этот тексте я показал как строить графики при помощи интерпретируемого языка программирования Python.