С ростом популярности web-приложения его поддержка неизбежно начинает требовать всё больших и больших ресурсов. Первое время с нагрузкой можно (и, несомненно, нужно) бороться путём оптимизации алгоритмов и/или архитектуры самого приложения. Однако, что делать, если всё, что можно было оптимизировать, уже оптимизировано, а приложение всё равно не справляется с нагрузкой?

@scriptbunnyread-only
User
Apache Hadoop (Доклад Владимира Климонтовича на ADD-2010)
17 min
Tutorial
Представляем вашему вниманию доклад Владимира Климонтовича, сделанный им на конференции Application Developer Days, в котором он поделился своим опытом обработки ОЧЕНЬ БОЛЬШИХ объемов данных, и использование для этого NOSQL-подходов, в частности Apache Hadoop.

Ниже представлены текстовая версия доклада + видео + аудио и слайды презентации. Спасибо belonesox за работу над подготовкой материалов доклада.
Ниже представлены текстовая версия доклада + видео + аудио и слайды презентации. Спасибо belonesox за работу над подготовкой материалов доклада.
Работа с URL и их хранение
3 min
Ну вот одна из самых вкусных частей БД – она хранит миллиарды разных ссылок, и производит доступ к ним в произвольном порядке.
Сначала очевидно можно заметить что все URL сгруппированы в рамках сайта, т.е. все ссылки внутри 1 сайта можно хранить вместе для скорости. Я выделил URL сайта, и стал хранить список сайтов отдельно – сейчас их 600 тыс и отдельная таблица БД описанной раньше легко с ними справляется. В памяти постоянно находится AVL дерево с CRC всех известных сайтов, и проверяя первым делом существование URL я получаю ID сайта ему соответствующего, если он уже есть в базе.
Остальную часть ссылки – кроме названия сайта я отрезаю, и считаю CRC для нее, назовем ее Hash. Таким образом любая ссылка относительно однозначно имеет индекс (ID сайта, Hash). Все ссылки можно отсортировать по Hash в рамках отдельного сайта, и тогда можно легко искать существующую или нет – пробегать по списку все ссылок данного сайта пока не встретим с нужным Hash или не встретим больший Hash – значит ссылки нет. Ускорение не очень большое, но в 2 раза, все таки, в среднем.
Сначала очевидно можно заметить что все URL сгруппированы в рамках сайта, т.е. все ссылки внутри 1 сайта можно хранить вместе для скорости. Я выделил URL сайта, и стал хранить список сайтов отдельно – сейчас их 600 тыс и отдельная таблица БД описанной раньше легко с ними справляется. В памяти постоянно находится AVL дерево с CRC всех известных сайтов, и проверяя первым делом существование URL я получаю ID сайта ему соответствующего, если он уже есть в базе.
Остальную часть ссылки – кроме названия сайта я отрезаю, и считаю CRC для нее, назовем ее Hash. Таким образом любая ссылка относительно однозначно имеет индекс (ID сайта, Hash). Все ссылки можно отсортировать по Hash в рамках отдельного сайта, и тогда можно легко искать существующую или нет – пробегать по списку все ссылок данного сайта пока не встретим с нужным Hash или не встретим больший Hash – значит ссылки нет. Ускорение не очень большое, но в 2 раза, все таки, в среднем.
Построение индекса для поисковой машины
4 min
Полное содержание и список моих статей по поисковой машине будет обновлятся здесь.
В предыдущих статьях я рассказывал про работу поисковой машины, вот и дошел до сложного технически момента. Напомню что разделяют 2 типа индексов – прямой и обратный. Прямой – сопоставление документу списка слов в нем встреченного. Обратный – слову сопоставляется список документов, в которых оно есть. Логично, что для быстрого поиска лучше всего подходит обратный индекс. Интересный вопрос и про то, в каком порядке в списке хранить документы.
На предыдущем шаге DataFlow от модуля-индексатора мы получили кусочек данных в виде прямого индекса, ссылочной информации и информации о страницах. Обычно у меня он составляет около 200-300mb и содержит примерно 100 тысяч страниц. Со временем я отказался от стратегии хранения цельного прямого индекса, и храню только все эти кусочки + полный обратный индекс в нескольких версиях, чтобы можно было откатиться назад.
Устройство обратного индекса с виду, простое, – храним файл, в нем в начале таблица адресов начала данных по каждому слову, потом собственно данные. Это я утрировано. Так получается самый выгодный для оптимизации скорости поиска формат — не надо прыгать по страницам — как писали Брин и Пейдж, — 1 seek, 1 read. На каждой итерации перестроения, я использую 20-50 кусочков информации описанных выше, очевидно загрузить всю инфу из них в память я не могу, тем более что там полезно хранить еще кучу служебных данных об индексе.
В предыдущих статьях я рассказывал про работу поисковой машины, вот и дошел до сложного технически момента. Напомню что разделяют 2 типа индексов – прямой и обратный. Прямой – сопоставление документу списка слов в нем встреченного. Обратный – слову сопоставляется список документов, в которых оно есть. Логично, что для быстрого поиска лучше всего подходит обратный индекс. Интересный вопрос и про то, в каком порядке в списке хранить документы.
На предыдущем шаге DataFlow от модуля-индексатора мы получили кусочек данных в виде прямого индекса, ссылочной информации и информации о страницах. Обычно у меня он составляет около 200-300mb и содержит примерно 100 тысяч страниц. Со временем я отказался от стратегии хранения цельного прямого индекса, и храню только все эти кусочки + полный обратный индекс в нескольких версиях, чтобы можно было откатиться назад.
Устройство обратного индекса с виду, простое, – храним файл, в нем в начале таблица адресов начала данных по каждому слову, потом собственно данные. Это я утрировано. Так получается самый выгодный для оптимизации скорости поиска формат — не надо прыгать по страницам — как писали Брин и Пейдж, — 1 seek, 1 read. На каждой итерации перестроения, я использую 20-50 кусочков информации описанных выше, очевидно загрузить всю инфу из них в память я не могу, тем более что там полезно хранить еще кучу служебных данных об индексе.
Googlebot начал делать POST-запросы через Ajax
2 min
Поисковый краулер Google постоянно улучшается, чтобы получить доступ к относительно закрытым частям сайтов. В 2008 году Googlebot начал сабмиттить GET-формы, а нынешним летом — исполнять JavaScript. Сейчас дошло дело и до передачи данных серверу методом POST.
Веб-мастер сайта thumbtack.com демонстрирует примеры таких запросов в логах Apache за сентябрь-октябрь 2011 года.
Веб-мастер сайта thumbtack.com демонстрирует примеры таких запросов в логах Apache за сентябрь-октябрь 2011 года.
Общедоступный индекс веба (5 миллиардов веб-страниц)
1 min
Организация Common Crawl сделала щедрый подарок разработчикам и компаниям, которые работают в области поиска и обработки информации. В открытый доступ на Amazon S3 выложен индекс из 5 миллиардов веб-страниц с метаданными, PageRank и графом гиперссылок.
Если вы видели в логах веб-сервера CCBot/1.0, то это их краулер. Некоммерческая организация Common Crawl выступает за свободу информации и поставила целью сделать общедоступный поисковый индекс, который будет доступен каждому разработчику или стартапу. Предполагается, что это приведёт к созданию целой плеяды инновационных веб-сервисов.
Если вы видели в логах веб-сервера CCBot/1.0, то это их краулер. Некоммерческая организация Common Crawl выступает за свободу информации и поставила целью сделать общедоступный поисковый индекс, который будет доступен каждому разработчику или стартапу. Предполагается, что это приведёт к созданию целой плеяды инновационных веб-сервисов.
Wolfram Alpha может определить, какой тип самолета сейчас пролетел над вами
1 min

И не только. Этот сервис сможет также подсказать, какой компании самолет принадлежит, и куда именно он направлялся. Для того, чтобы все это узнать, нужно только знать свои координаты, и забить в поисковую строку запрос типа «flights overhead». Сделать это можно и в десктопном браузере, и в браузере мобильного устройства (если будет включена геолокация, то все просто идеально). Результаты поиска удивляют, их можно видеть на скриншоте ниже.
Делаем приватный монитор из старого LCD монитора
2 min
Translation

Вы наконец-то можете сделать кое-что со своим старым LCD монитором, который завалялся у Вас в гараже. Превратите его в шпионский монитор! Для всех вокруг он будет выглядеть просто белым экраном, но не для Вас, потому что у Вас будут специальные «волшебные» очки.
Всё что Вам нужно – это пара старых очков, нож для бумаги и растворитель для краски.
Анонсы Alawar: движок HTML5-игр, поддержка IE9 pinned site и собственная сборка браузера
2 min

Компанию Alawar можно без преувеличения назвать крупнейшим российским разработчиком казуальных игр для множества платформ, в том числе социальных сетей. Сегодня я очень рад озвучить ряд анонсов Alawar и представить вам новинки, которые компания подготовила в сотрудничестве с Microsoft.
В первую очередь я очень рад представить вам видео-анонс нового HTML5-движка компании, который будет использоваться в будущих проектах Alawar. Я думаю, многие из вас будут рады узнать, что Alawar присоединилась к лагерю разработчиков HTML5-игр и разработке богатых приложений на современных веб-стандартах. Ниже представлено видео, которое впервые было показано в рамках конференции TechEd Russia 2011 на треке докладов по инструментам и языкам программирования.
Ниже вы можете узнать про другие анонсы от Alawar: новый сайт с функцией закрепления на панели задач Windows 7 и сборку браузера Internet Explorer 9 с быстрым доступом к играм компании.
Слоистая архитектура на основе фреймворка yii
8 min

Представим себе компанию, которая реализует целый ряд собственных продуктов — как для внешних пользователей, так и для внутренних. Скорее всего, каждый продукт не сможет существовать по отдельности, как сферический конь в вакууме, а в какой-то степени будет интегрирован с другими. В итоге все они вместе образуют некий слой взаимосвязанных между собой и при этом самостоятельно развивающихся организмов. И скорее всего, их развитие осуществляется совершенно разными командами.
Хорошие примеры такой среды — это Яндекс (поиск, Директ, карты, почта, вертикальные и внутренние сервисы) или Google. Понятно, что у перечисленных гигантов технологии в каждом продукте свои, но если взять компанию поменьше и работающую в более узкой предметной области, то можно предположить, что веб-продукты будут выполнены на одних технологиях (языках программирования, фреймворках и.т.д).
Именно об опыте в организации архитектуры всей линейки продуктов у такой компании я и хочу рассказать.
Алгоритм сортировки Timsort
6 min
Timsort, в отличии от всяких там «пузырьков» и «вставок», штука относительно новая — изобретен был в 2002 году Тимом Петерсом (в честь него и назван). С тех пор он уже стал стандартным алгоритмом сортировки в Python, OpenJDK 7 и Android JDK 1.5. А чтобы понять почему — достаточно взглянуть на вот эту табличку из Википедии.
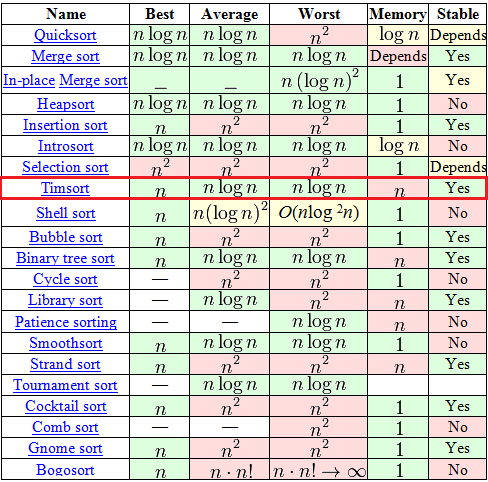
Среди, на первый взгляд, огромного выбора в таблице есть всего 7 адекватных алгоритмов (со сложностью O(n logn) в среднем и худшем случае), среди которых только 2 могут похвастаться стабильностью и сложностью O(n) в лучшем случае. Один из этих двух — это давно и хорошо всем известная «Сортировка с помощью двоичного дерева». А вот второй как-раз таки Timsort.
Алгоритм построен на той идее, что в реальном мире сортируемый массив данных часто содержат в себе упорядоченные (не важно, по возрастанию или по убыванию) подмассивы. Это и вправду часто так. На таких данных Timsort рвёт в клочья все остальные алгоритмы.
Среди, на первый взгляд, огромного выбора в таблице есть всего 7 адекватных алгоритмов (со сложностью O(n logn) в среднем и худшем случае), среди которых только 2 могут похвастаться стабильностью и сложностью O(n) в лучшем случае. Один из этих двух — это давно и хорошо всем известная «Сортировка с помощью двоичного дерева». А вот второй как-раз таки Timsort.
Алгоритм построен на той идее, что в реальном мире сортируемый массив данных часто содержат в себе упорядоченные (не важно, по возрастанию или по убыванию) подмассивы. Это и вправду часто так. На таких данных Timsort рвёт в клочья все остальные алгоритмы.
Корова десятого уровня
2 min

Работать по 12 часов в сутки, тащить на себе миллионы, быть кумиром тысячей хомячков, напиваться до безумия каждый релиз, экспериментировать и фанатично строчить фичекат до 3-х утра.
Забудь.
Ты в мейнстриме, бро.
Видеоплеер из подручных материалов
6 min
Tutorial
 Эта статья расскажет, как сделать видеоплеер из предметов, которые можно найти в кладовке любого айтишника. Ардуино, журнал Vogue, и дисплей от Нокиа 3310 можно оставить в покое — они нам не понадобятся. Наличие паяльника приветствуется, но можно обойтись и без него.
Эта статья расскажет, как сделать видеоплеер из предметов, которые можно найти в кладовке любого айтишника. Ардуино, журнал Vogue, и дисплей от Нокиа 3310 можно оставить в покое — они нам не понадобятся. Наличие паяльника приветствуется, но можно обойтись и без него.Судя по скорости развития технологий, лет через десять появится поколение, никогда не видевшее электронно-лучевых трубок. А между тем, история видео дисплеев начиналась с совершенно других устройств…
Процессор и ПК своими руками: проект BMOW 1
2 min

Никому не известный инженер Стив Чемберлин (Steve Chamberlin) решил изменить общепринятое мнение о том, что процессор своими руками создать невозможно. Точнее, процессор достаточно сложного ПК, который смог бы дублировать функции 8-битных вычислительных устройств, получивших распространение в начале 80-х. Вначале это было небольшой проект, который со временем вырос в нечто большее. Сейчас BMOW 1 представляет собой полноценный ПК на основе самодельного процессора, который запускает программы, имеет клавиатуру, VGA-видео, аудио-систему. Программная среда для BMOW 1 — Basic.
История взлома одной браузерной игры. Возврат контроля
11 min
Доброго времени суток. Я занимаюсь аудитом защищённости веб-приложений. По простому — тестами на проникновение в отношении веб-сайтов. Иногда в моей практике встречаются интересные и познавательные случаи, которые я бы хотел описывать в виде таких вот статей, но редко (для меня это первый случай) бывают ситуации когда клиент разрешает публикацию подобного материала с подробным описанием всех имевшихся проблем и предпринятых действий. Естественно, тут вы не встретите никаких конкретных имён, названия фирмы-заказчика и т. д. Упоминания таких данных мне, наверное, никто никогда не разрешит. Надеюсь что для вас, уважаемые читатели, данная статья окажется интересной и полезной.
Графические фильтры на основе матрицы скручивания
6 min
UPD: Заголовок изменен, что бы более соответствовать теме статьи
В статье пойдет речь об использовании convolution matrix (матрицы скручивания или матрицы свертки), с помощью которой можно создавать и накладывать на изображения фильтры, такие как blur, sharpen и многие другие.
Cтатья будет интересна не только веб-программистам, но и всем кто так или иначе занимается программной обработкой изображений, поскольку функции для работы с матрицей скручивания имеются во многих языках (точно известно о php и flash). Так же, статья будет интересна дизайнерам, использующим Adobe Photoshop, поскольку в нем имеется соответствующий фильтр (Filter-Other-Custom).
Примеры будут на языке PHP с использованием библиотеки GD. Теория, практика, примеры (осторожно, много картинок!)
В статье пойдет речь об использовании convolution matrix (матрицы скручивания или матрицы свертки), с помощью которой можно создавать и накладывать на изображения фильтры, такие как blur, sharpen и многие другие.
Cтатья будет интересна не только веб-программистам, но и всем кто так или иначе занимается программной обработкой изображений, поскольку функции для работы с матрицей скручивания имеются во многих языках (точно известно о php и flash). Так же, статья будет интересна дизайнерам, использующим Adobe Photoshop, поскольку в нем имеется соответствующий фильтр (Filter-Other-Custom).
Примеры будут на языке PHP с использованием библиотеки GD. Теория, практика, примеры (осторожно, много картинок!)
Ещё более современный C++
6 min
Translation
“C++11 feels like a new language.” – Bjarne Stroustrup
Не так давно Герб Саттер открыл на своём сайте новую страничку — Elements of Modern C++ Style, где он описывает преимущества нового стандарта и то, как они повлияют на код.
Не так давно Герб Саттер открыл на своём сайте новую страничку — Elements of Modern C++ Style, где он описывает преимущества нового стандарта и то, как они повлияют на код.
Бди!
1 min
Как известно, в большинстве европейских языков принято начертание текста слева направо, а у некоторых ближневосточных языков принято начертание текста справа налево. Если символ Юникода не является буквою алфавита (таковы знаки пунктуации и арабские цифры), то по умолчанию в браузере он принимает ориентацию предшествующего текста (например, появляется слева от текста, предшествующего ему в HTML-коде, если этот текст был семитским).
Однако случается и так, что ориентация некоторого текста может быть любою (например, у имени пользователя, когда оно берётся из базы данных), но положение последующей пунктуации и нумерации (например, для единообразия пунктов в списке имён пользователей сайта) должно соответствовать не этому тексту, а ориентации остального документа. Понятно, что тогда такой текст, ориентация которого заранее не известна, придётсякак-то экранировать от остального документа.
Традиционным средством такого экранирования является задание тексту соответствующегоCSS-свойства (кодом <span style="unicode-bidi: isolate">…</span>). Однако это и долго записывать, и тег span (как известно) не семантический, да и браузерам всё ещё разрешено игнорировать CSS, если такова их настройка. Было бы лучше, кабы был специальный тег HTML для такого экранирования.
И такой тег действительно оказался введён WhatWGв подразделе 4.6.23 черновика стандарта HTML5.
Однако случается и так, что ориентация некоторого текста может быть любою (например, у имени пользователя, когда оно берётся из базы данных), но положение последующей пунктуации и нумерации (например, для единообразия пунктов в списке имён пользователей сайта) должно соответствовать не этому тексту, а ориентации остального документа. Понятно, что тогда такой текст, ориентация которого заранее не известна, придётся
Традиционным средством такого экранирования является задание тексту соответствующего
И такой тег действительно оказался введён WhatWG
Ajenti 0.6
1 min
Мы снова приветствуем вас на волнах Changelog FM, и сегодня у нас в студии — Ajenti 0.6.0.