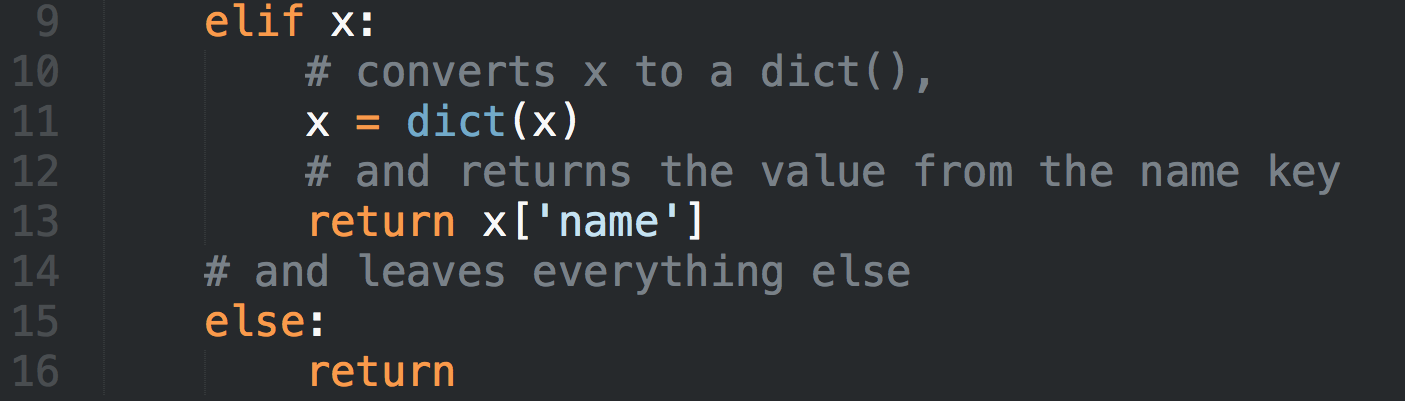
Современные программы, претендующие на звание эффективных, должны учитывать особенности аппаратного обеспечения, на котором они будут исполняться. В частности, речь идёт о многоядерных процессорах, например, таких, как Intel Xeon и Intel Xeon Phi, о больших размерах кэш-памяти, о наборах инструкций, скажем, Intel AVX2 и Intel AVX-512, позволяющих повысить производительность вычислений.

Еле удержались, чтобы не пошутить про руссиано)
Вот, например, Caffe – популярная платформа для разработки нейронных сетей глубокого обучения. Её создали в Berkley Vision and Learning Center (BVLC), она пришлась по душе сообществу независимых разработчиков, которые вносят посильный вклад в её развитие. Платформа живёт и развивается, доказательство тому – статистика на странице проекта в GitHub. Caffe называют «быстрой открытой платформой для глубокого обучения». Можно ли ускорить такой вот «быстрый» набор инструментов? Задавшись этим вопросом, мы решили оптимизировать Caffe для архитектуры Intel.
Еле удержались, чтобы не пошутить про руссиано)
Вот, например, Caffe – популярная платформа для разработки нейронных сетей глубокого обучения. Её создали в Berkley Vision and Learning Center (BVLC), она пришлась по душе сообществу независимых разработчиков, которые вносят посильный вклад в её развитие. Платформа живёт и развивается, доказательство тому – статистика на странице проекта в GitHub. Caffe называют «быстрой открытой платформой для глубокого обучения». Можно ли ускорить такой вот «быстрый» набор инструментов? Задавшись этим вопросом, мы решили оптимизировать Caffe для архитектуры Intel.
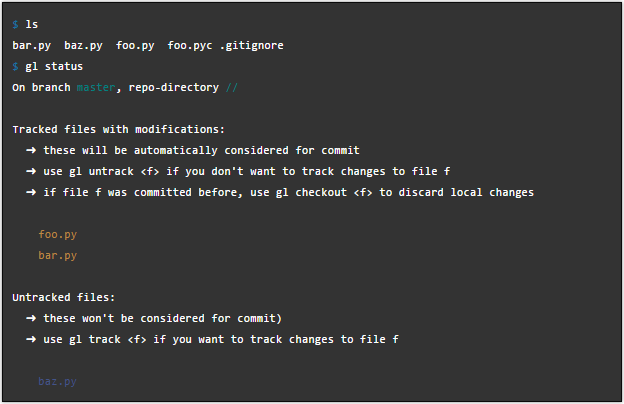



 Сразу оговорюсь, что поскольку мне в процессе всех экспериментов уже поднадоело сносить и заново настраивать дроплет в DO, пример я буду выполнять в VMware ESXi, но на конечный результат это влиять не будет, команды все будут те же самые, в принципе, это применимо к любому облачному VPS хостингу, где у нас есть доступ по SSH.
Сразу оговорюсь, что поскольку мне в процессе всех экспериментов уже поднадоело сносить и заново настраивать дроплет в DO, пример я буду выполнять в VMware ESXi, но на конечный результат это влиять не будет, команды все будут те же самые, в принципе, это применимо к любому облачному VPS хостингу, где у нас есть доступ по SSH. Экосистема языка python стремительно развивается. Это уже не просто язык общего назначения. С его помощью можно успешно разрабатывать веб-приложения, системные утилиты и много другое. В этой заметке мы сконцентрируемся все же на другом приложении, а именно на научных вычислениях. Я хотел бы поделиться своим опытом в данной теме.
Экосистема языка python стремительно развивается. Это уже не просто язык общего назначения. С его помощью можно успешно разрабатывать веб-приложения, системные утилиты и много другое. В этой заметке мы сконцентрируемся все же на другом приложении, а именно на научных вычислениях. Я хотел бы поделиться своим опытом в данной теме. В последние два месяца лета в управлении хранилищ данных (Data Warehouse, DWH) Тинькофф Банка появилась новая тема для кухонных споров.
В последние два месяца лета в управлении хранилищ данных (Data Warehouse, DWH) Тинькофф Банка появилась новая тема для кухонных споров.