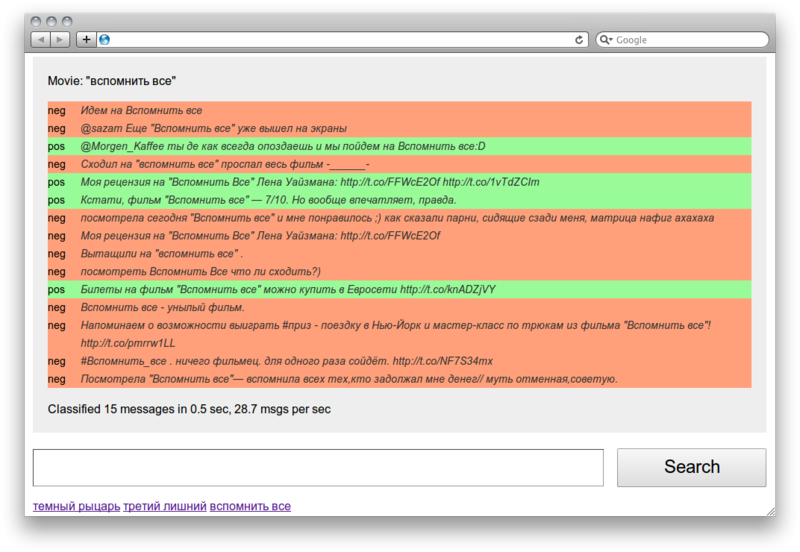
Вчера получил от freelansim.ru «письмо счастья» – с новостью о том, что появилась новая возможность — «Верификация учетной записи». Зачем это нужно, почему это хорошо, и как это работает – хочу рассказать в этой статье.


Java разработчик
a = 0
def increment1():
global a
a += 1
def increment2(a):
return a + 1



 Суффиксное дерево – мощная структура, позволяющая неожиданно эффективно решать мириады сложных поисковых задач на неструктурированных массивах данных. К сожалению, известные алгоритмы построения суффиксного дерева (главным образом алгоритм, предложенный Эско Укконеном (Esko Ukkonen)) достаточно сложны для понимания и трудоёмки в реализации. Лишь относительно недавно, в 2011 году, стараниями Дэни Бреслауэра (Dany Breslauer) и Джузеппе Италиано (Giuseppe Italiano) был придуман сравнительно несложный метод построения, который фактически является упрощённым вариантом алгоритма Питера Вейнера (Peter Weiner) – человека, придумавшего суффиксные деревья в 1973 году. Если вы не знаете, что такое суффиксное дерево или всегда его боялись, то это ваш шанс изучить его и заодно овладеть относительно простым способом построения.
Суффиксное дерево – мощная структура, позволяющая неожиданно эффективно решать мириады сложных поисковых задач на неструктурированных массивах данных. К сожалению, известные алгоритмы построения суффиксного дерева (главным образом алгоритм, предложенный Эско Укконеном (Esko Ukkonen)) достаточно сложны для понимания и трудоёмки в реализации. Лишь относительно недавно, в 2011 году, стараниями Дэни Бреслауэра (Dany Breslauer) и Джузеппе Италиано (Giuseppe Italiano) был придуман сравнительно несложный метод построения, который фактически является упрощённым вариантом алгоритма Питера Вейнера (Peter Weiner) – человека, придумавшего суффиксные деревья в 1973 году. Если вы не знаете, что такое суффиксное дерево или всегда его боялись, то это ваш шанс изучить его и заодно овладеть относительно простым способом построения.