Привет, Хабр!
Блог «Я безумный» зачем-то переименовали в «Подсознание», поэтому писать буду здесь. Как-то раз я не мог вспомнить название фильма, но точно помнил названия пары других, которые были на него похожи. Появилась идея зарегистрироваться на каком-нибудь рекомендательном киносервисе, затем, поставить известной мне паре фильмов наивысшие возможные оценки. Ну а дальше, уповать на то, что сервис порекомендует мне похожие фильмы и среди них будет тот, название которого я забыл.
Регистрироваться в подобном сервисе мне стало лениво потому, что всё что на самом деле мне было нужно — это просто указать пару названий фильмов и получить список похожих. Никакие регистрации-оценки-рекомендации не нужны. Так и родилась идея сделать сервис, который по паре строчек текста мог бы определить принадлежность этих строк к какому-либо множеству и показать это множество пользователю.
Естественно, основная проблема — где достать данные по множествам, ответ — получить их от самих пользователей. Но беда в том, что первые пользователи сервиса обречены на бесполезные попытки найти хоть какие-то ответы на свои запросы. Так что, всё-таки нужно где-то заранее добыть эти множества. Для английского языка, я это худо-бедно, но сделал, а вот для русского не получилось.
Если вы владеете английским, попробуйте что-нибудь поискать, другое что-нибудь непременно найдётся. Из русских множеств, сервис знает только о «хабр, лепра, дёрти» и «мир, труд, май», но ничто не мешает вам эти знания расширить. Ах да, ссылка —
aliketo.com.
Весёлых выходных!
UPDATE: Вижу, что ищут одной строчкой «мир, труд», так не работает. Так работает:
мир
труд

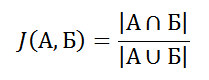
 Почти все разработчики знают, что кэш процессора — это такая маленькая, но быстрая память, в которой хранятся данные из недавно посещённых областей памяти — определение краткое и довольно точное. Тем не менее, знание «скучных» подробностей относительно механизмов работы кэша необходимо для понимания факторов влияющих на производительность кода.
Почти все разработчики знают, что кэш процессора — это такая маленькая, но быстрая память, в которой хранятся данные из недавно посещённых областей памяти — определение краткое и довольно точное. Тем не менее, знание «скучных» подробностей относительно механизмов работы кэша необходимо для понимания факторов влияющих на производительность кода.