В этой статье мы подробно разберем понятие сопрограмм (coroutines), их классификацию, детально рассмотрим реализацию, допущения и компромиссы, предлагаемые новым стандартом C++20.


Пользователь
В этой статье мы подробно разберем понятие сопрограмм (coroutines), их классификацию, детально рассмотрим реализацию, допущения и компромиссы, предлагаемые новым стандартом C++20.


Для написания эффективных и корректных многопоточных приложений очень важно знать какие существуют механизмы синхронизации памяти между потоками исполнения, какие гарантии предоставляют элементы многопоточного программирования, такие как мьютекс, join потока и другие. Особенно это касается модели памяти C++, которая была создана сложной таковой, чтобы обеспечивать оптимальный многопоточный код под множество архитектур процессоров. Кстати, язык программирования Rust, будучи построенным на LLVM, использует модель памяти такую же, как в C++. Поэтому материал в этой статье будет полезен программистам на обоих языках. Но все примеры будут на языке C++. Я буду рассказывать про std::atomic, std::memory_order и на каких трех слонах стоят атомики.
int main()
{
int n = 500000000;
int *a = new int[n + 1];
for (int i = 0; i <= n; i++)
a[i] = i;
for (int i = 2; i * i <= n; i++)
{
if (a[i]) {
for (int j = i*i; j <= n; j += i) {
a[j] = 0;
}
}
}
delete[] a;
return 0;
}
Сегодня необычный для меня формат статьи: я скорее задаю вопрос залу, нежели делюсь готовым рецептом. Впрочем, для инициирования дискуссии рецепт тоже предлагаю. Итак, сегодня мы поговорим о чувстве прекрасного.
Я довольно давно пишу код, и так вышло, что практически всегда на C++. Даже и не могу прикинуть, сколько раз я написал подобную конструкцию:
for (int i=0; i<size; i++) {
[...]
}Хотя почему не могу, очень даже могу:
find . \( -name \*.h -o -name \*.cpp \) -exec grep -H "for (" {} \; | wc -l
43641Наш текущий проект содержит 43 тысячи циклов. Проект пилю не я один, но команда маленькая и проект у меня не первый (и, надеюсь, не последний), так что в качестве грубой оценки пойдёт. А насколько такая запись цикла for хороша? Ведь на самом деле, важно даже не то количество раз, когда я цикл написал, а то количество раз, когда я цикл прочитал (см. отладка и code review). А тут речь очевидно идёт уже о миллионах.
На КПДВ узел под названием «совершенная петля» (perfection loop).

Так каков он, совершенный цикл?



(прим. переводчика: времена жизни (lifetimes) — это одна из самых запутанных вещей в Rust, которая часто вызывает затруднение у новичков, даже несмотря на официальную документацию. Разъяснения по отдельным аспектам времён жизни есть, но они все разбросаны по разным источникам и ответам на Stack Overflow. Автор статьи собрал в одном месте и разъяснил множество связанных с временами жизни вопросов, что и делает эту статью столь ценной (я и сам почерпнул новое для себя отсюда). Я решил перевести её, чтобы дать возможность прочитать её тем, кто не владеет английским в достаточной степени, чтобы свободно читать оригинал, а также для того, чтобы повысить известность этой статьи среди русскоязычного Rust-сообщества)
19 мая 2020 г. · 37 минут · #rust · # lifetimes
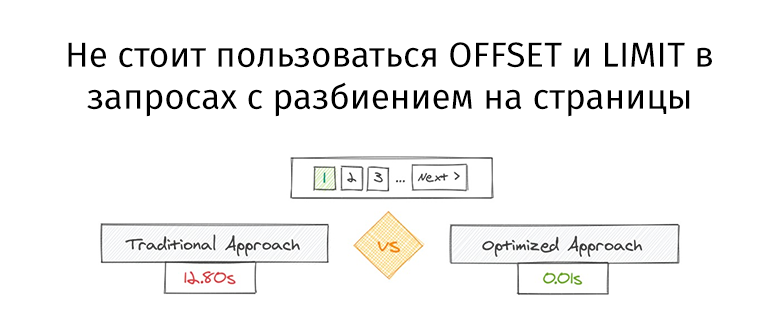

explicit(bool), назначенные инициализаторы (designated initializers), циклы for на основе диапазонов с инициализаторами.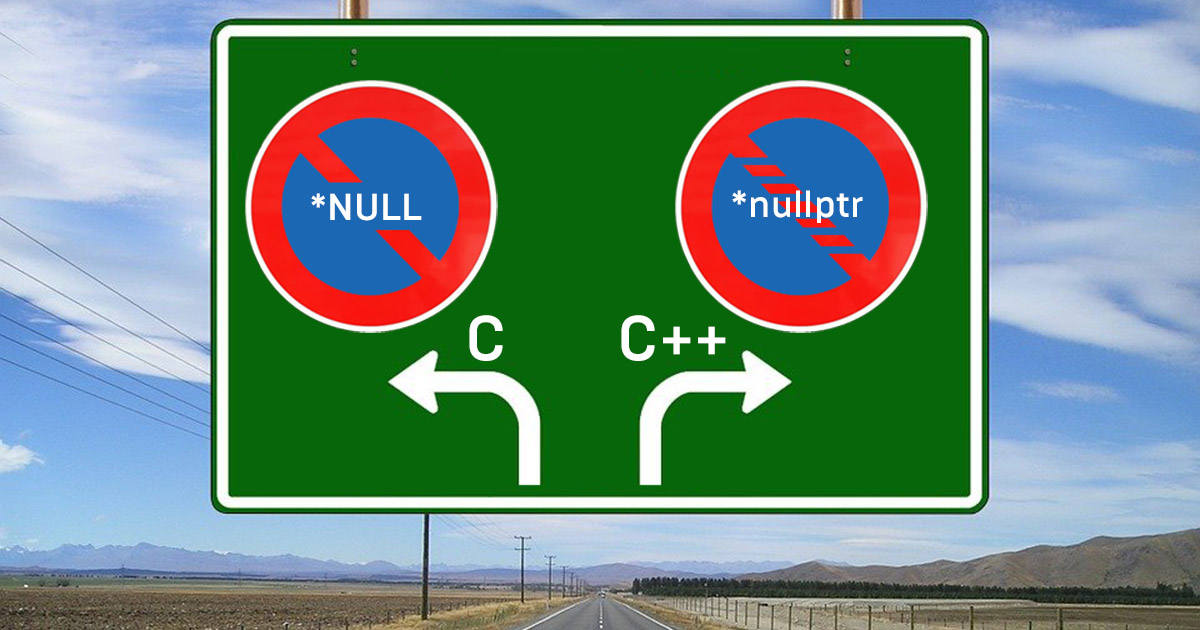
Некоторым этот банальный вопрос уже набил оскомину, но мы взяли 7 примеров и попытались объяснить их поведение при помощи стандарта:
struct A {
int data_mem;
void non_static_mem_fn() {}
static void static_mem_fn() {}
};
void foo(int) {}
A* p{nullptr};
/*1*/ *p;
/*2*/ foo((*p, 5));
/*3*/ A a{*p};
/*4*/ p->data_mem;
/*5*/ int b{p->data_mem};
/*6*/ p->non_static_mem_fn();
/*7*/ p->static_mem_fn();