Вступление
Привет, Хабр!
Предыдущая часть понравилась многим, поэтому я снова перелопатил половину документации boost и нашёл о чем написать. Очень странно что вокруг boost.compute нету такого же ажиотажа как и вокруг boost.asio. Ведь достаточно, того эта библиотека кроссплатформенная, так ещё и предоставляет удобный (в рамках c++) интерфейс взаимодействия с параллельными вычислениями на GPU и CPU.
Все части
- Часть 1
- Часть 2
Содержание
- Асинхронные операции
- Пользовательские функции
- Сравнение скорости работы разных устройств в разных режимах
- Заключение
Асинхронные операции
Казалось бы, куда ещё быстрее? один из способов ускорить работу с контейнерами пространства имён compute это использование асинхронных функций. Boost.compute предоставляет нам несколько инструментов. Из них класс compute::future для контроля использования функций и функции copy_async(), fill_async() для копирования или заполнения массива. Конечно, существуют ещё и инструменты для работы с событиями, но их рассматривать нет необходимости. Дальше будет пример использования всего выше перечисленного:
auto device = compute::system::default_device();
auto context = compute::context::context(device);
auto queue = compute::command_queue(context, device);
std::vector<int> vec_std = {1, 2, 3};
compute::vector<int> vec_compute(vec_std.size(), context);
compute::vector<int> for_filling(10, context);
int num_for_fill = 255;
compute::future<void> filling = compute::fill_async(for_filling.begin(),
for_filling.end(), num_for_fill, queue); // асинхронно заполняет заданный вектор
compute::future<void> copying = compute::copy_async(vec_std.begin(),
vec_std.end(), vec_compute.begin(), queue); // асинхронно копирует следующий вектор
filling.wait();
copying.wait();
Пояснять тут особо нечего. Первые три строчки — стандартная инициализация необходимых классов, потом два векторы для копирования, вектор для заполнения, переменная которой будем заполнять предыдущий вектор и непосредственно функции для заполнения и копирования соответственно. Потом дожидаемся их выполнения.
Для тех, кто работал с std::future из STL, тут абсолютно всё тоже самое, только в другом пространстве имён и нет аналога std::async().
Пользовательские функции для вычислений
В предыдущей части я сказал, что поясню как использовать свои собственные методы для обработки массива данных. Я насчитал 3 способа как это можно сделать: использовать макрос, использовать make_function_from_source<>() и использовать специальный фреймворк для лямбда выражений.
Начну с самого первого варианта — макроса. Сначала приложу пример кода а потом поясню как работает.
BOOST_COMPUTE_FUNCTION(float,
add,
(float x, float y),
{ return x + y; });
Первым аргументом указываем тип возвращаемого значения, потом название функции, её аргументы и тело функции. Дальше под именем add, данную функцию можно использовать например в функции compute::transform(). Использование этого макроса очень похоже на обычное лямбда выражение, но я проверял, они работать не будут.
Второй и, наверное, самый сложный способ очень похож на первый. Я смотрел код предыдущего макроса и оказалось, что он использует именно второй способ.
compute::function<float(float)> add = compute::make_function_from_source<float(float)>
("add", "float add(float x, float y) { return x + y; }");
Здесь всё очевидней чем может показаться на первый взгляд, функция make_function_from_source(), использует всего два аргумента, один из которых название функции, а второй — её реализация. После объявления функции её можно использовать так же как и после реализации макросом.
Ну и последний вариант это фреймворк для лямбда выражений. Пример использования:
compute::transform(com_vec.begin(),
com_vec.end(),
com_vec.begin(),
compute::_1 * 2,
queue);
Четвёртым аргументом мы указываем что хотим умножить каждый элемент из первого вектора на 2, всё достаточно просто и делается на месте.
Этим же способом можно указывать логические выражения. Например в методе compute::count_if():
std::vector<int> source_std = { 1, 2, 3 };
compute::vector<int> source_compute(source_std.begin() ,source_std.end(), queue);
auto counter = compute::count_if(source_compute.begin(),
source_compute.end(),
compute::lambda::_1 % 2 == 0,
queue);
Таким образом мы посчитали все чётные числа в массиве, counter будет равен единице.
Сравнение скорости работы разных устройств в разных режимах
Ну и последнее, про что я хотел бы написать в этой статье, это сравнение скорости обработки данных на разных устройствах и в разных режимах(только для CPU). это сравнение докажет, когда есть смысл использовать GPU для вычислений и параллельные вычисления в целом.
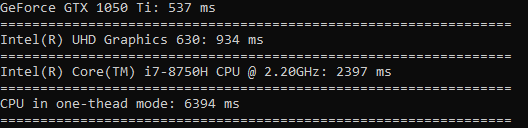
Тестировать я буду так: с помощью compute для всех устройств вызову функцию compute::sort() для того чтоб отсортировать массив из 100 млн. значений типа float. Для теста однопоточного режима вызову std::sort для массива такого же размера. Для каждого устройства засеку время в миллисекундах с помощью стандартной библиотеки chrono и выведу всё в консоль.
Получился такой результат:
Теперь сделаю всё тоже самое только для тысячи значений. На этот раз время будет в микросекундах.
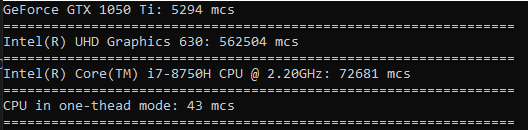
На этот раз процессор в однопоточном режиме опередил всех. Из этого делаем вывод что такого рода операции стоит делать только когда речь идёт о действительно больших данных.
Хотелось бы сделать ещё несколько тестов, поэтому сделаем тест на вычисление косинуса, квадратного корня и возведения в квадрат.
В вычислении косинуса разница очень большая (GPU работает в 60 раз быстрее CPU в одном потоке).
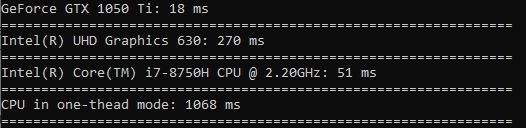
Квадратный корень считается почти с такой же скоростью как и сортировка.

Время затраченное на возведение в квадрат имеет ещё меньше разницу чем сортировка(GPU быстрее всего в 3.5 раза).

Заключение
Итак, прочитав эту статью, вы научились использовать асинхронные функции для копирования массивов и их заполнения. Узнали какими способами можно использовать свои собственные функции для проведения вычислений над данными. А также наглядно увидели когда стоит использовать GPU или CPU для параллельных вычислений, а когда можно обойтись одним потоком.
Буду рад позитивным отзывам, спасибо за уделённое время!
Всем удачи!
