
 Я люблю графические отладчики. Обычные я тоже люблю, но графические — больше. Они дают ощущение сродни заглядыванию за кулисы театра во время выступления: «ага, вот эта декорация крепится так, а этот луч света падает отсюда, а у этого шкафа нет задней стенки...». Графический отладчик пробрасывает мостик понимания между текстовым кодом приложения и полученной красивой картинкой.
Я люблю графические отладчики. Обычные я тоже люблю, но графические — больше. Они дают ощущение сродни заглядыванию за кулисы театра во время выступления: «ага, вот эта декорация крепится так, а этот луч света падает отсюда, а у этого шкафа нет задней стенки...». Графический отладчик пробрасывает мостик понимания между текстовым кодом приложения и полученной красивой картинкой. Но индустрия не балует нас обилием подобного инструментария. Есть графические отладчики от Intel, NVidia и AMD, но они не работают на чипах конкурентов и предназначены не столько для разработки\отладки, сколько для бенчмарков и хвастовства своими видеокартами. Они неплохо рассказывают ЧТО и КОГДА произошло, но плохо объясняют ПОЧЕМУ и КАК ИСПРАВИТЬ.
В другом лагере находится мой любимый RenderDoc, о котором я уже писал. Прекрасная утилита, написанная ребятами из Crytek для себя и людей. Открытый код, поддержка всех вендоров, DirectX11 (с планами на Вулкан и DirectX12), куча мелких полезных мелочей.
Вторым представителем когда-то был PIX — утилита для анализа производительности DirectX9. Задумывалась она как инструмент для разработки под XBox (само название это аббревиатура от Performance Investigation for XBox), но хорошо работала и для десктопных приложений. До того момента, пока не умерла (с выходом DirectX 10/11 и новых версий Windows). Microsoft, у которого в очередной раз маркетологи победили инженеров, объявил единственным инструментом для графической отладки Visual Studio, в которой именно для этих целей было много лишнего, многого не хватало, а кое-что было и вовсе невозможно. Студия — прекрасный инструмент для программирования, но далеко не столь хорошая вещь для изучения, профилирования и отладки графического кода (тем более чужого).
Всё это уныние продолжалось несколько лет, пока инженеры Microsoft не одержали временную победу и в январе 2017 года Microsoft объявила о запуске беты полностью обновлённой версии PIX для DirectX 12!
Давайте же посмотрим, что мы получили.

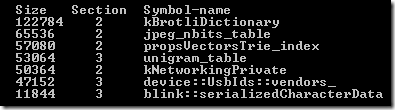
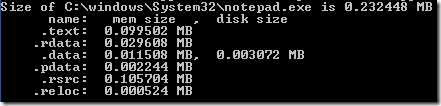

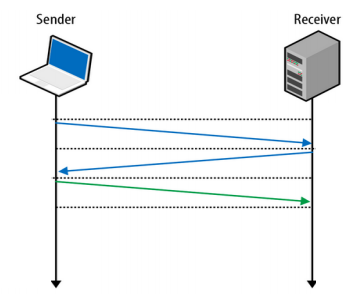
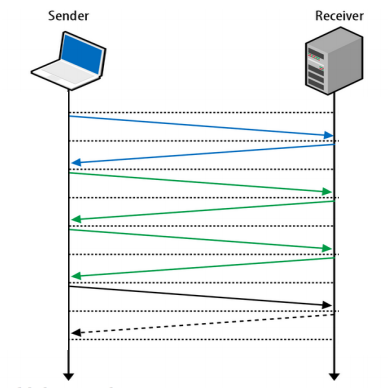
 В статье об
В статье об  Второй причиной заблуждений могут служить, как это ни парадоксально, бенчмарки. К примеру, далее в этой статье мы будем измерять производительность блокировок под высокой нагрузкой: каждый поток будет требовать блокировку для выполнения любого действия, а сами блокировки будут очень короткими (и, в результате, очень частыми). Это нормально для эксперимента, но такой способ написания кода — это не то, что вам нужно в реальном приложении.
Второй причиной заблуждений могут служить, как это ни парадоксально, бенчмарки. К примеру, далее в этой статье мы будем измерять производительность блокировок под высокой нагрузкой: каждый поток будет требовать блокировку для выполнения любого действия, а сами блокировки будут очень короткими (и, в результате, очень частыми). Это нормально для эксперимента, но такой способ написания кода — это не то, что вам нужно в реальном приложении.
